- The paper demonstrates that integrating low-power binocular cameras into earbuds enables robust, real-time egocentric visual intelligence with sub-2s response times.
- It employs a custom hardware pipeline including BLE streaming, stereo image stitching, and prompt-adaptive VLM inference to balance low latency and image quality.
- User studies confirm that VueBuds achieves comparable MOS to smart glasses with high task accuracy, while preserving the ergonomics and battery life of commercial earbuds.
VueBuds: Visual Intelligence with Wireless Earbuds — A Technical Perspective
Introduction
VueBuds (2603.29095) presents an innovative system that extends egocentric visual intelligence to the audio wearable domain by integrating low-power binocular cameras into wireless earbuds. The paper demonstrates the feasibility of this novel form factor through a comprehensive pipeline, from custom hardware and data streaming to low-latency VLM inference and extensive user studies, positioning ear-level vision systems as a potent alternative to head-mounted smart glasses for multimodal interaction.
System Architecture and Hardware Design
The VueBuds prototype integrates an ultra-low-power grayscale image sensor and BLE SoC within modified Sony WF-1000XM3 earbuds, maintaining commercial device weight and power envelopes. The camera module draws under 5 mW in typical use, introducing an 11–14% battery overhead for scenarios with up to 60 visual queries/hour. Binaural integration enables forward stereo capture via 3D-printed enclosures that facilitate physically unconstrained, forward-facing camera alignment, while preserving charging case compatibility and typical earbud ergonomics.

Figure 1: VueBuds hardware integrated with Sony WF-1000XM3—custom camera module (left), forward-facing enclosure (middle), and charging case compatibility (right).
The embedded architecture employs a Himax HM01B0 sensor interfaced to a Nordic nRF52840 via SPI-DMA with active-low/select-line adaptation. BLE throughput optimization (2 Mbps PHY, 992 kbps effective) yields 1.4 fps at QVGA (324×239) and 5.7 fps at QQVGA, balancing visual fidelity and real-time streaming constraints. Power state control (OFF/IDLE/ACTIVE) exploits both hardware interrupts (via in-ear sensors) and wake-word-activated fast transitions for minimal overhead under sporadic use.
End-to-End Multimodal Pipeline
VueBuds implements a fully-wireless, low-latency VLM pipeline. Raw image data is multiplexed via BLE to a USB bridge, demultiplexed and preprocessed on the host, and fed into an on-device VLM model alongside the user's spoken query, parsed via TinyWhisper ASR. The system supports prompt-adaptive VLM input, e.g., direct dual image or stitched panoramic capture to minimize redundant context and optimize inference tokenization and latency.
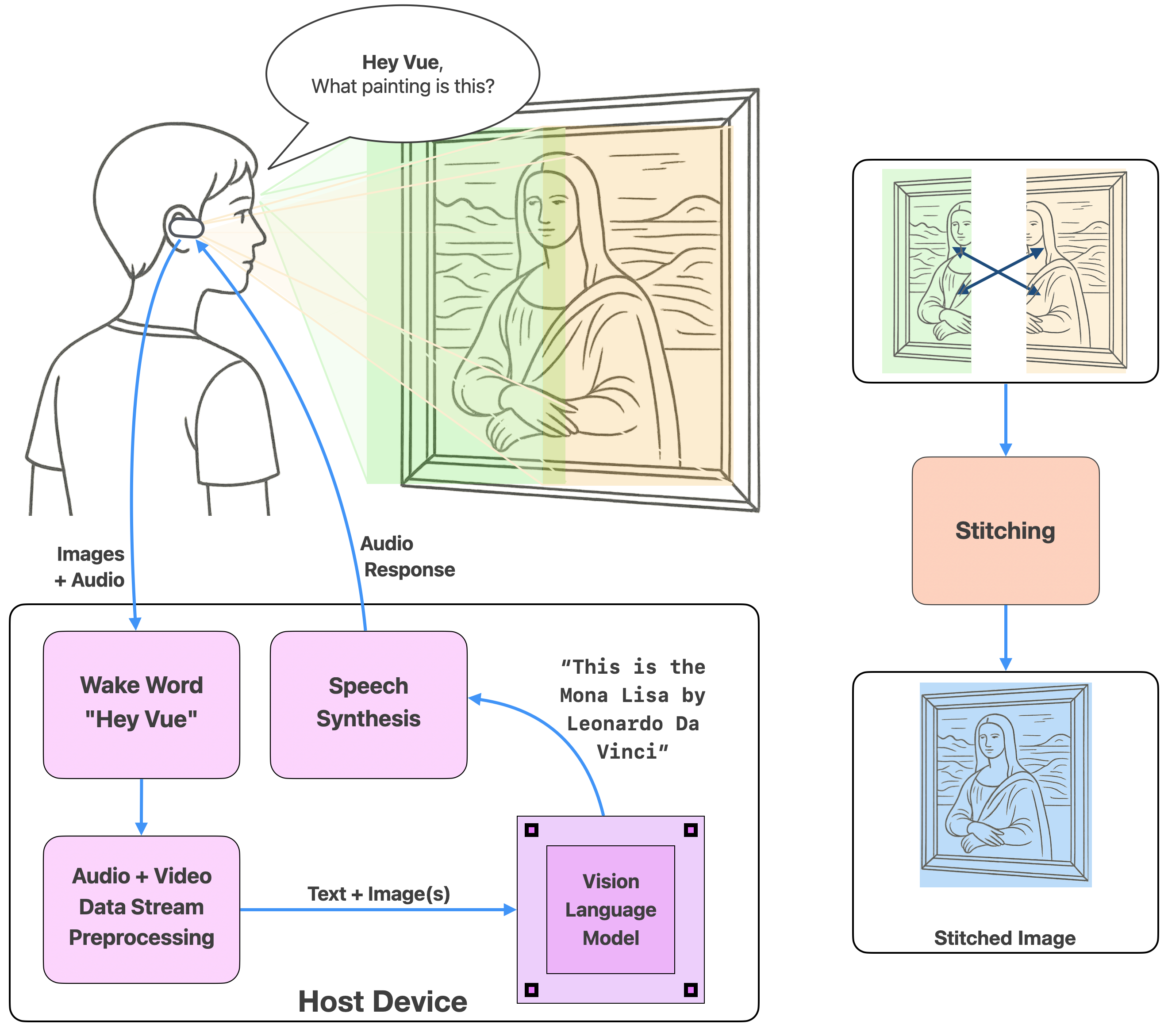
Figure 2: System overview—voice and binocular visual streams processed via a vision LLM, with multimodal interaction and real-time feedback.
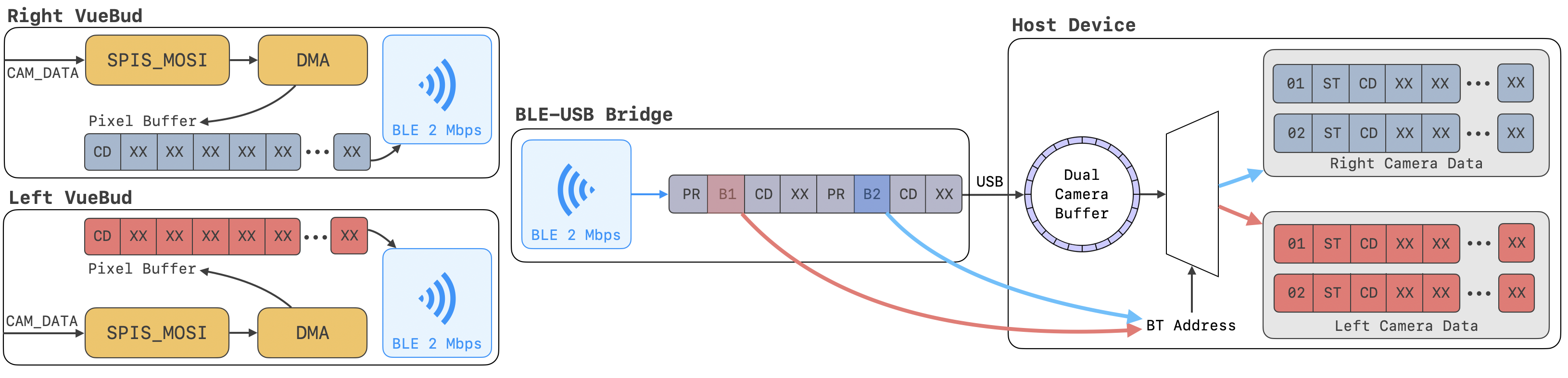
Figure 3: Wireless data pipeline from dual cameras through BLE-USB bridge to host, supporting concurrent streaming and real-time demultiplexing.
Image fusion is implemented via an ORB-based feature pipeline optimized for non-trimmed, parallax-sensitive alignment, reducing VLM input tokens by 46% and improving TTFT from 2.15s to 1.14s. The full pipeline, under optimal streaming and on-device wake-word detection, achieves sub-2s latency from query completion to first VLM token—matching expectations for real-world conversational agents.
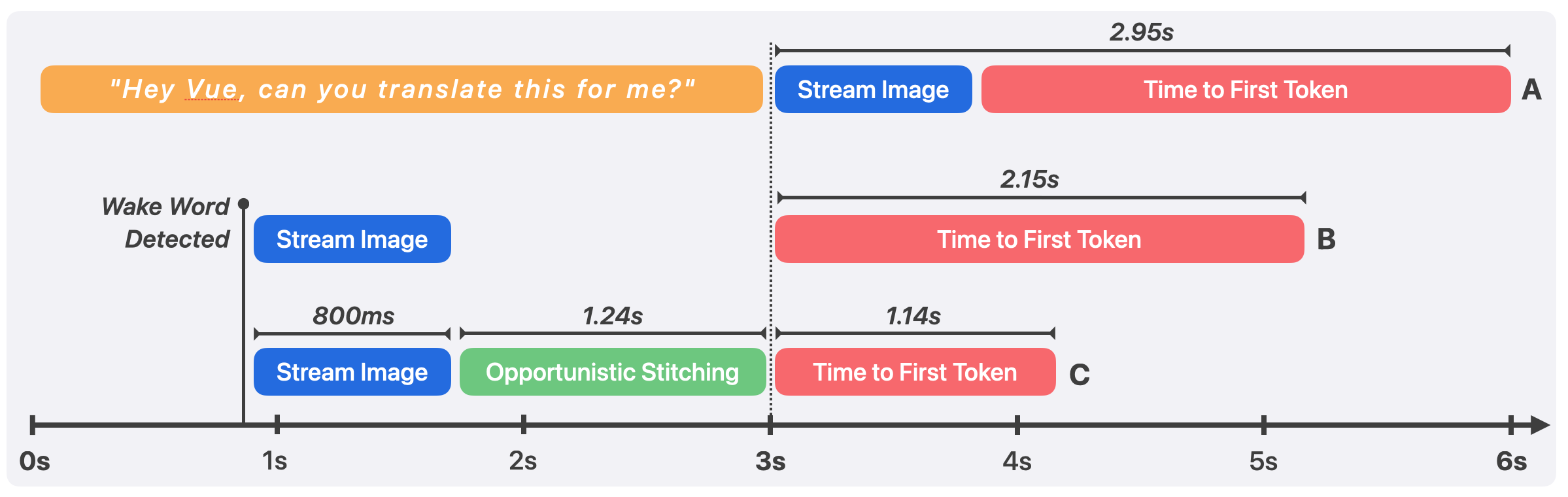
Figure 4: Latency breakdown—pipeline advances reduce end-to-end response time from 2.95s (sequential) to 1.14s (opportunistic stitching).
Binocular Ear-Level Vision: Coverage, Occlusion, and Stitching
A central challenge is providing robust egocentric perception despite the lateral-posterior offset of ear-worn cameras. The system achieves comprehensive forward coverage by leveraging binocular imaging and low-FOV windowing, mitigating facial occlusion and minimizing the close-range blind spot. Empirical and model-aligned results confirm that a 5–10° outward camera angle (yielding 18.6–24.7 cm blind spot) preserves natural manipulation distances (well below the Harmon distance, 36.8 cm), while the stereo FOV (108° at 10° angle) matches that of commercial smart glasses.
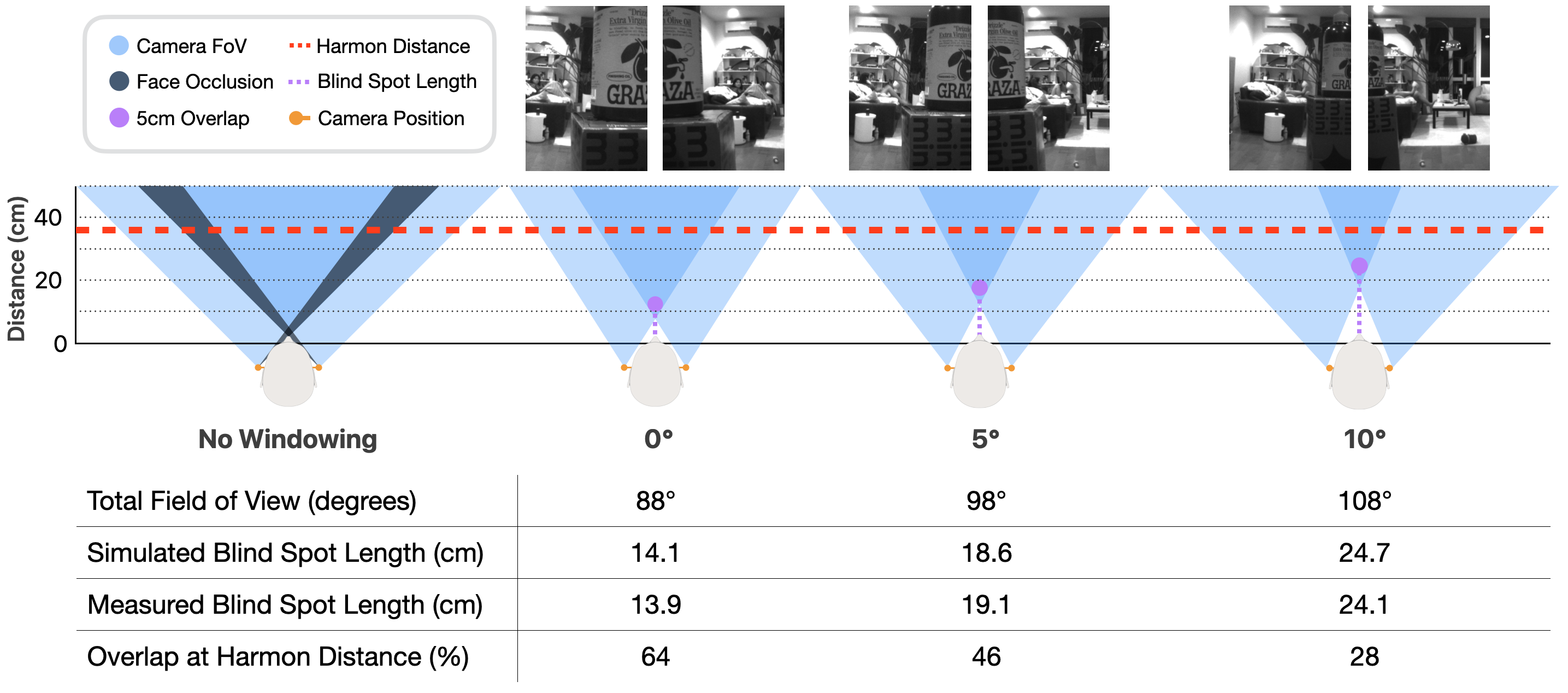
Figure 5: Blind spot analysis—geometric and empirical evaluation of occlusion across camera orientations; 5–10° optimizes FOV and blind spot trade-off.
Image stitching is non-trivial due to the non-rigid separation of the cameras. The system opportunistically fuses left and right frames, with lightweight feature matching, achieving significant latency gains and improved input compactness for VLM inference.

Figure 6: Input compactness—dual versus stitched panoramic images reduce redundancy and boost inference efficiency.
The pipeline's efficacy depends on VLM performance given low-resolution (324×239), monochrome images. Five VLMs (Qwen2.5-VL, Moondream, MiniCPM-V, LLaVA, Gemma3) were benchmarked for task accuracy and latency. Qwen2.5-VL (7B) exhibited superior accuracy (80.1%) at 1.39s TTFT compared to alternatives; Moondream performed well on object/OCR but was non-functional on reasoning, MiniCPM-V overfit prompts, and Gemma3 suffered from unacceptable latency (12s TTFT).
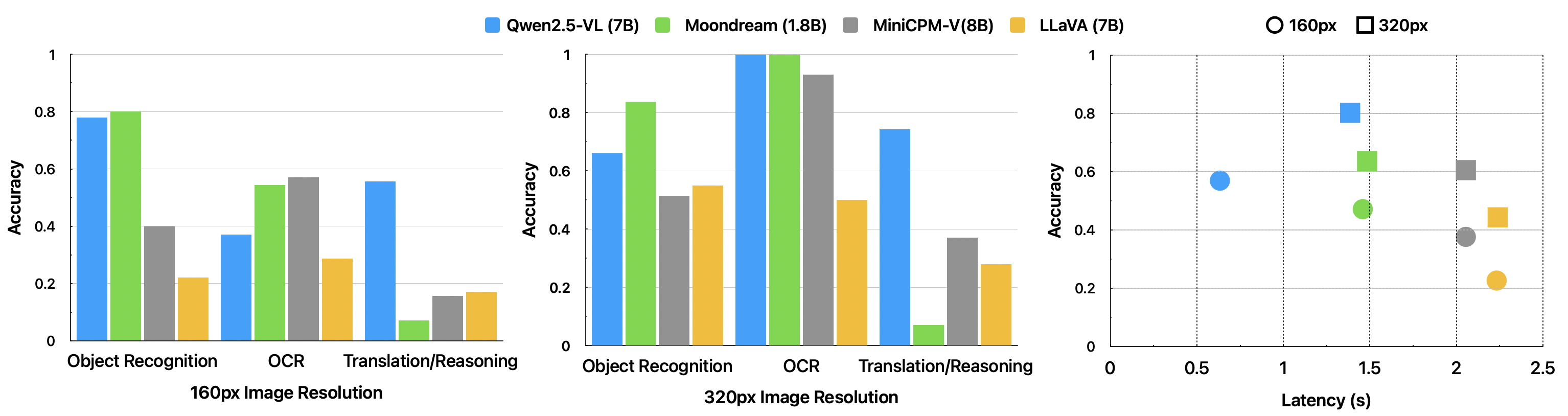
Figure 7: Comparative VLM accuracy and latency; Qwen2.5-VL achieves the optimal trade-off for this hardware-VLM regime.
Resolution scaling from 160px to 320px produced substantial accuracy increases (up to 170% improvement for OCR tasks). The system as configured thus operates at the highest feasible resolution under BLE constraints to maximize text/scene understanding and translation accuracy.
A two-part study with n=90 examined device adoption and subjective response quality against smart glasses.
- Platform Accessibility: 93.3% of participants use earbuds at least occasionally versus 62.7% for glasses, establishing the form factor as broadly accessible.
- Task Performance and MOS: Across 17 VQA tasks, VueBuds with Qwen2.5-VL achieved indistinguishable response quality (MOS 3.33) compared to Ray-Ban Meta (MOS 3.32). VueBuds outperformed in translation (Q7: 4.1 vs. 2.8) but exhibited inferior numerical reasoning (Q15 count errors).
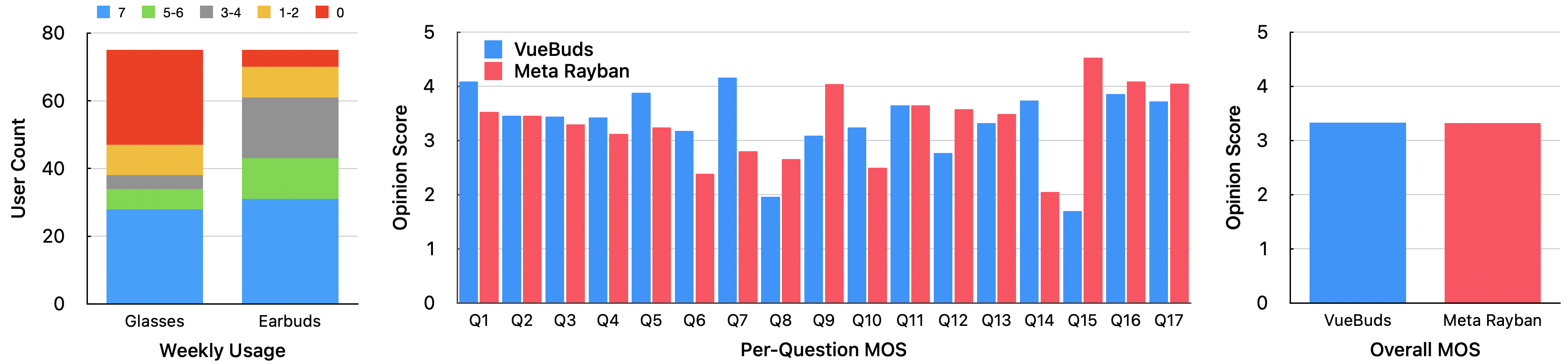
Figure 8: User study results—device adoption rates and comparative MOS across tasks for VueBuds and Ray-Ban Meta.
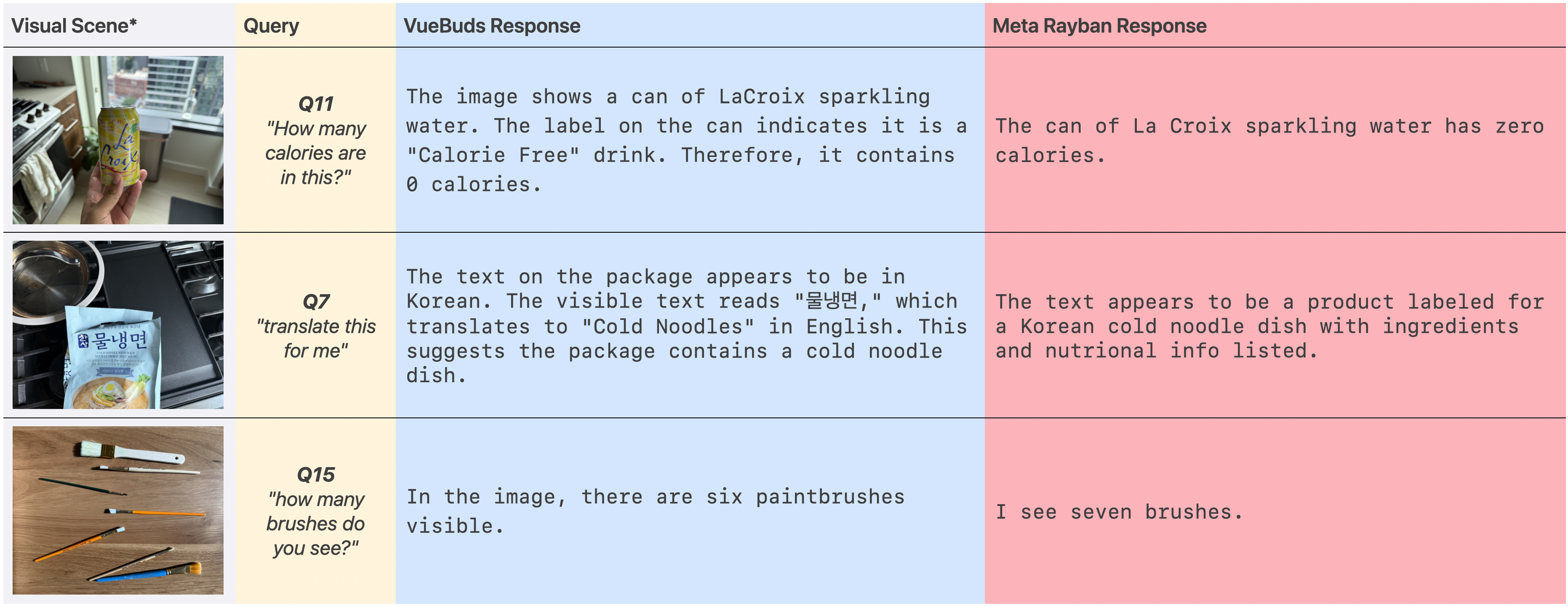
Figure 9: Representative task examples—VueBuds delivers accurate scene/translation responses on par with commercial smart glasses.
In-person studies (n=16, 130 trials) measuring real-world object recognition, OCR, and translation yielded 86.9% overall accuracy (ObjRec: 82.5%, OCR: 94.3%, Translation: 83.8%) even under varied user and environmental conditions.
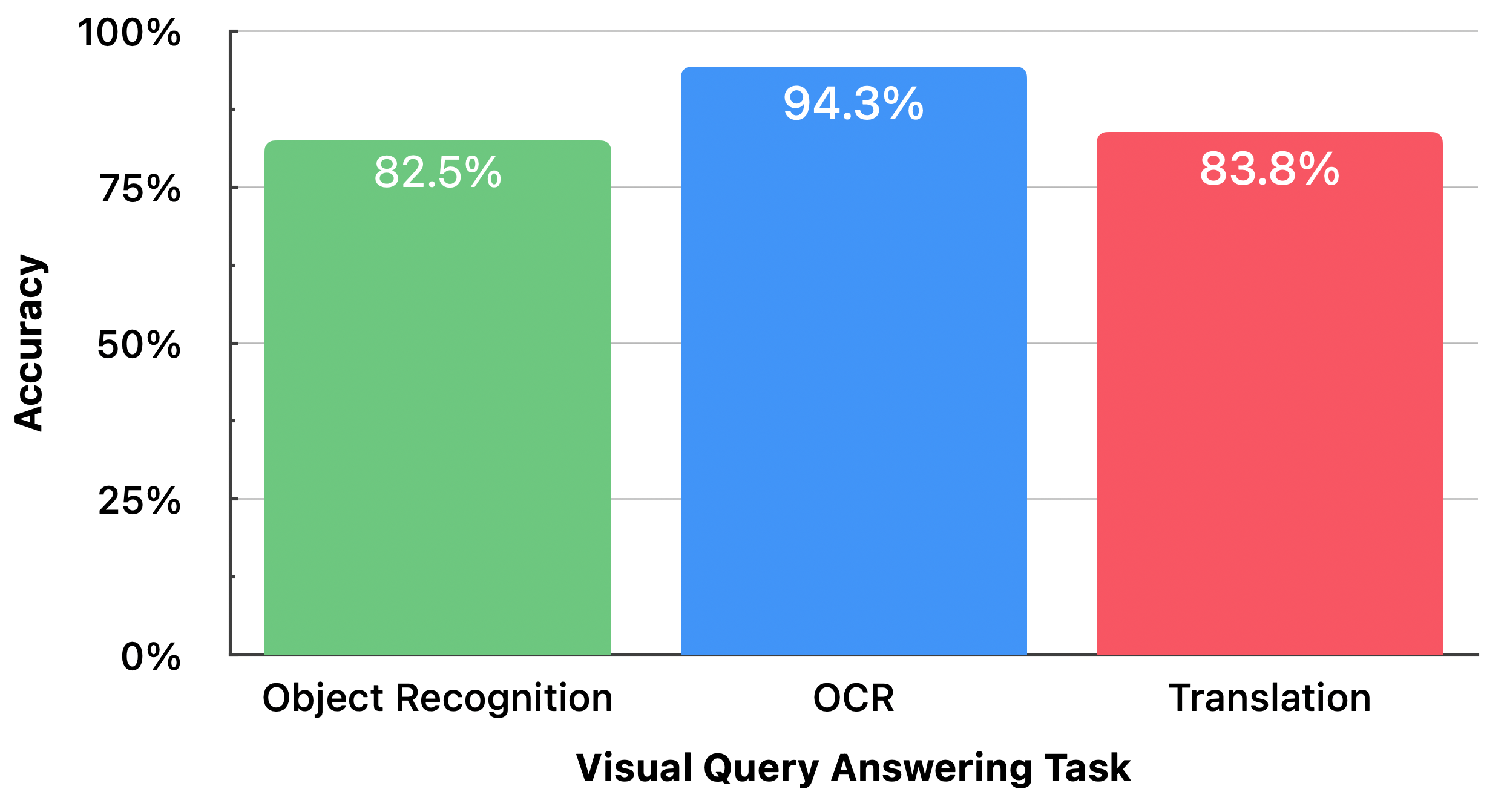
Figure 10: In-person VQA task accuracy—OCR achieves highest task reliability, object recognition is degraded primarily by imaging artifacts.
Latency, Power, and Feasibility
The complete pipeline, including BLE acquisition, image assembly, and VLM inference, achieves sub-1.5s TTFT under optimal opportunistic stitching and embedded wake-word activation. Power profiling indicates that 60 queries/hour (extreme usage) add only 11–14% to baseline battery consumption (yielding >5.3hr life for commercial earbuds). Always-on operation would result in more significant battery loss (~42–47%), but is tractable for newer, higher-capacity devices.
Social, Ergonomic, and Privacy Considerations
The system’s adoption is favored by the social normalization of earbuds over glasses (i.e., the “Google Glass” effect is mitigated). However, form factor discretion introduces a dual-use risk: while ear invisibility benefits wearers, it can obscure camera activation from bystanders. VueBuds mitigates this partially by on-device-only VLM inference (no cloud upload), always-on wake-word requirement, and visual/auditory indications, but does not fully resolve bystander privacy signaling—a limitation shared with other wearable camera modalities.

Figure 11: Explicit system failures—VLM and OCR errors are primarily attributable to low sensor resolution, dynamic range, and glare.
Additionally, the lack of direct gaze tracking (versus smart glasses) can reduce implicit deictic grounding ability, though holding/pointing at objects suffices for most queries. The ear-worn form factor affords compatibility with prescription glasses and can serve as a complementary rather than replacement modality for visual AI.

Figure 12: Disambiguation—users in cluttered scenes can resolve reference by grasping the intended target, supporting effective referent grounding in object queries.
Limitations and Future Directions
System accuracy is bottlenecked by sensor dynamic range, latency-acceptable grayscale/image resolution, and BLE throughput. Future hardware may exploit on-device lightweight compression, super-resolution, or color streaming as BLE progresses or BLE/WiFi dual radios are used. Depth estimation from stereo input could unlock further spatial audio applications. Gesture-based modalities or alternative user feedback mechanisms could further improve usability and social comfort.
Mobile inference hardware is not yet at parity with desktop-class systems, but recent advances suggest that real-time, on-device VLMs will be feasible in handheld and wearable compute in the near term. Privacy-preserving cropping, active LED signaling, and user/bystander gesture controls represent promising directions for privacy mediation.
Conclusion
VueBuds establishes that fully wireless, camera-integrated earbuds can achieve robust, real-time egocentric perception and multimodal interaction, with accuracy and user acceptance on par with current smart glasses under practical device constraints. This work opens a new, highly accessible form factor for embedded visual intelligence, suggesting novel directions for ubiquitous, privacy-sensitive, multimodal AI system development.

