When Bayes goes bad: Weakly-regularized covariate adjustment leads to a biased estimate of prevalence
Published 31 Mar 2026 in stat.ME and stat.AP | (2603.29134v1)
Abstract: When estimating population prevalence from a non-random sample, it is important to adjust for differences between sample and population. However, adjustment for multiple factors requires analysis that can be difficult to understand and validate. In this manuscript, we explore an unexpected downward trend of estimates when covariates are added sequentially to a Bayesian hierarchical model for the estimation of the prevalence of SARS-CoV-2 specific antibodies in an Australian city in late 2020. We compare our data analysis to results from a simulation study to understand four potential contributors to this effect: (i) correction for differences between sample and population, (ii) rare-events bias in logistic regression, (iii) inclusion of the uncertainty of test sensitivity and specificity in a multilevel model, and (iv) increasing model dimensionality. We find that weak prior distributions on the logistic regression coefficients lead to a systematic increase in the amount of partial pooling across adjustment cells-the prior becomes stronger as model dimensionality increases-which in turn feeds through to the estimated assay specificity, which then feeds back to the model and results in lowering the estimated prevalence. Our paper contributes three elements: (i) immediate and longer-term recommendations for using these types of models, (ii) simulation studies to explore the impact of the contributors to this effect, and (iii) a worked example of investigation of unexpected results in a model with multiple adjustment factors.
The paper demonstrates that weakly regularized covariate adjustment in Bayesian MRP models causes a systematic downward bias in prevalence estimates.
It employs iterative simulation studies and real-data comparisons to isolate contributions from rare-events bias, measurement error, and model complexity.
The findings emphasize the need for adequate calibration data and careful prior specification to ensure reliable disease prevalence estimation.
Weakly-Regularized Covariate Adjustment and Bias in Bayesian Prevalence Estimation
Introduction and Motivating Example
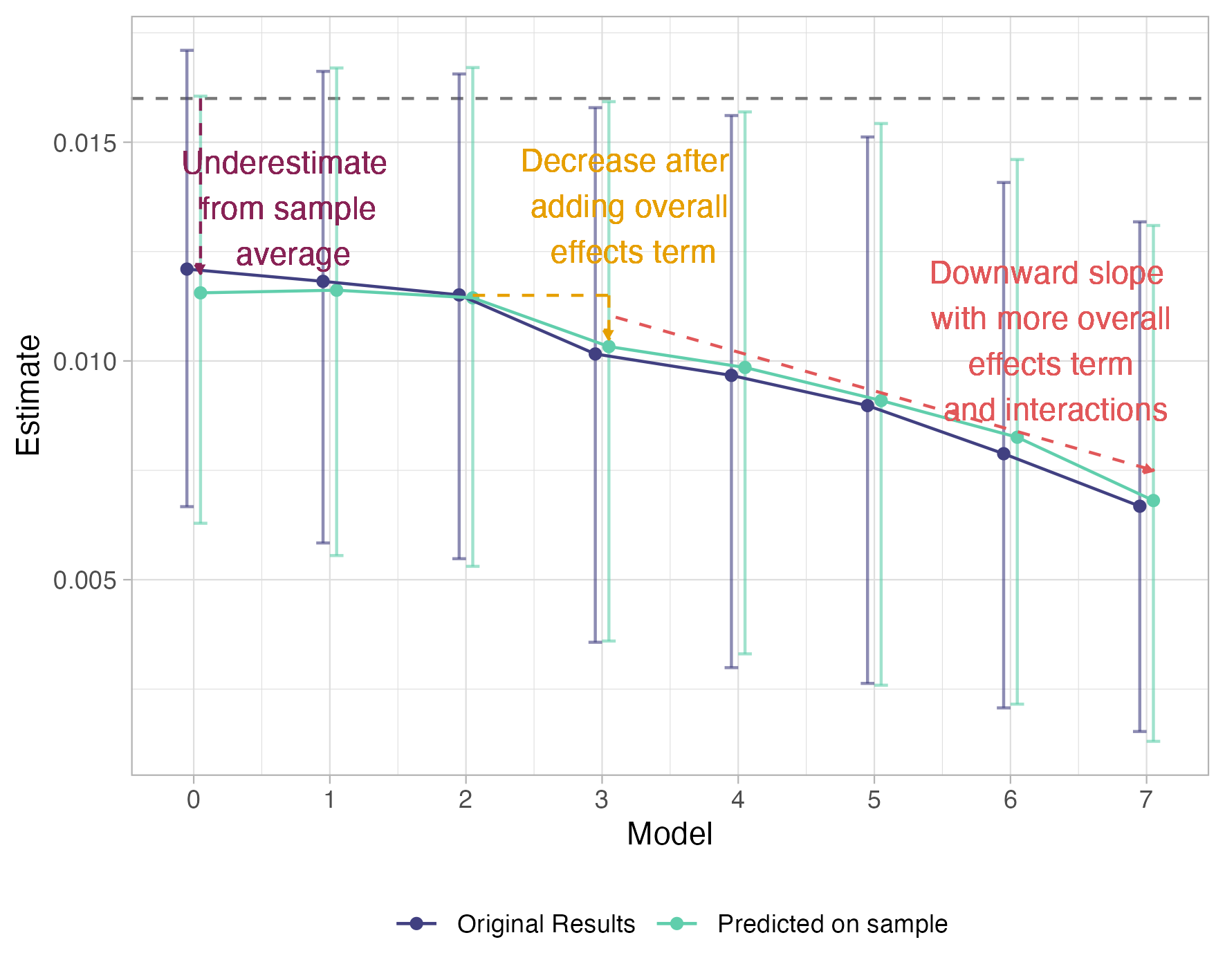
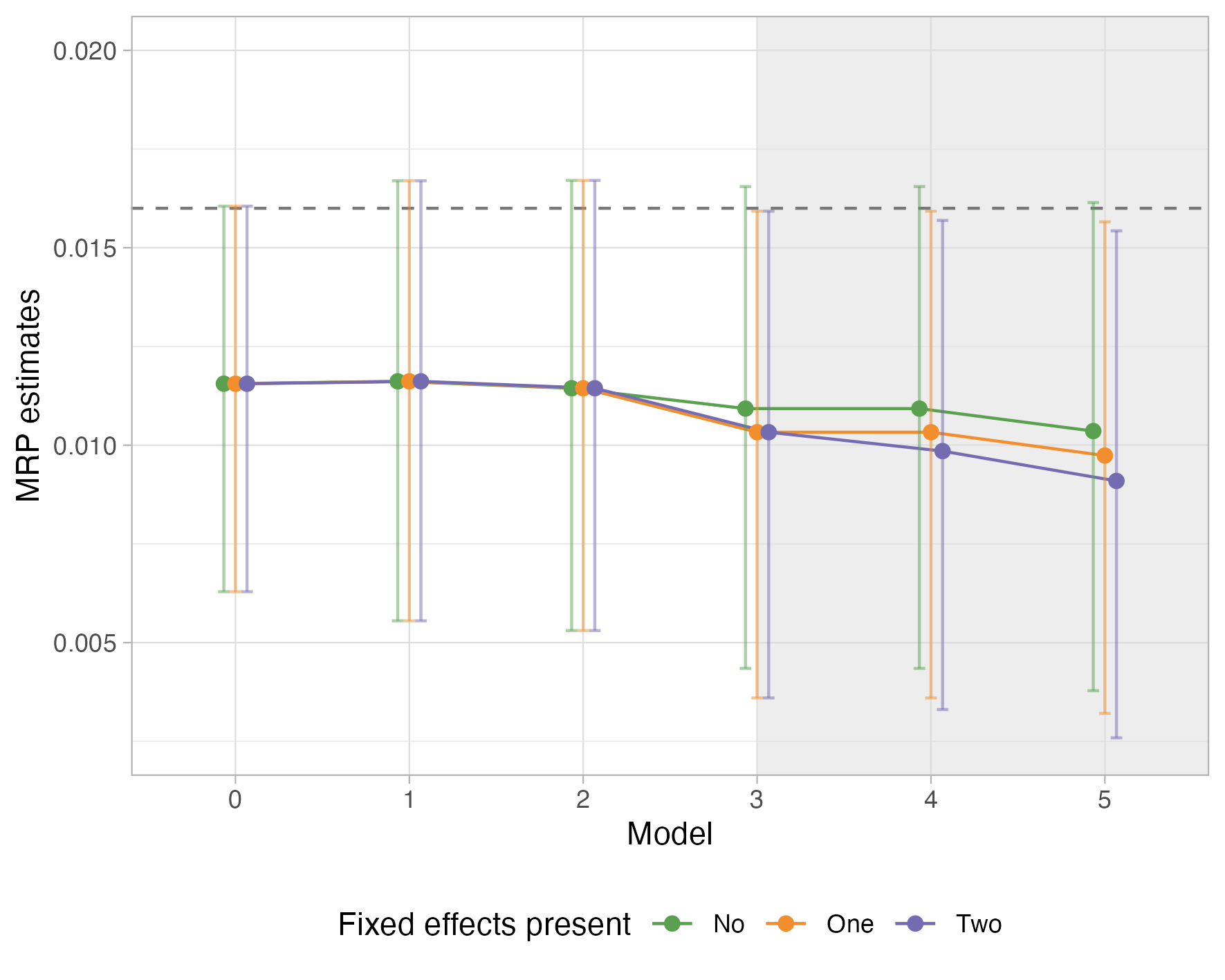
This paper addresses the estimation of disease prevalence, specifically SARS-CoV-2 antibody seroprevalence, via Bayesian hierarchical models using Multilevel Regression and Poststratification (MRP). The authors identify and systematically dissect an unexpected artifact: as more covariates are sequentially added to the model, the estimated prevalence decreases, diverging from both the observed sample mean and the expected population estimate for residential Melbourne during late 2020. The phenomenon persists even under posterior predictive checks targeted at the aggregate estimand, indicating a model-based issue, rather than a poststratification or adjustment artifact.
Figure 1: MRP seroprevalence estimate for Melbourne residential population vs. sample mean, highlighting downward trend as covariates are added.
MRP, as formulated by Gelman and Carpenter [gelman2020], propagates uncertainty from assay sensitivity/specificity together with sample adjustment. The initial motivating application had a stratified sample (by COVID-19 incidence strata) and blood donor data, with relatively rare antibody positives and sensitivity/specificity estimated from calibration datasets.
The paper aims to diagnose the root causes of this downward trend in prevalence estimates, hypothesizing several contributors:
Difference between sample and population correction,
Rare-events bias in logistic regression,
Uncertainty from test sensitivity and specificity estimation,
Effects from increasing model dimensionality and covariate encoding.
The workflow involves iterative simulation studies, progressively reintroducing model complexity, and comparative analyses with real-world data, isolating the contributions of the above factors.
Methodological Foundations
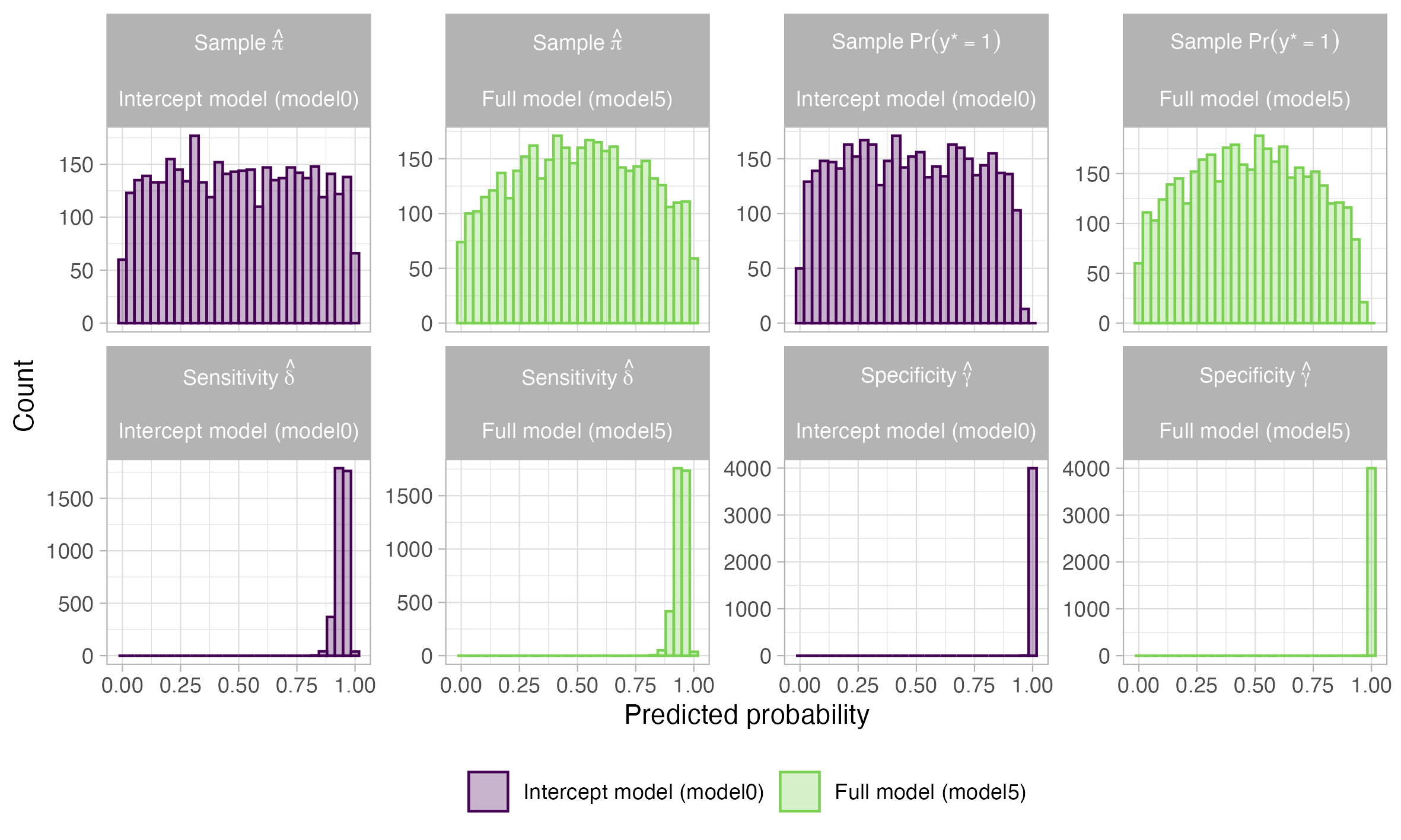
The MRP model is constructed as a multilevel logistic regression, where binary outcome prevalence (πi) is predicted by an intercept, fixed effects, and multiple varying effects. Test error is handled via a sensitivity (δ) and specificity (γ) correction, so the observed test outcome probability is:
Pr(yi∗=1)=(1−γ)(1−πi)+δπi
Sensitivity and specificity are themselves estimated with beta priors informed by calibration data, further propagating uncertainty into prevalence estimates.
Covariates are added sequentially as varying or non-varying effects, with the key diagnostic illustrated in (Figure 1): posterior predictive sample means follow the same downward trend as fully population-adjusted estimates, excluding adjustment as the cause.
Simulation Studies and Experiments
Experiment I: Rare-Events Bias
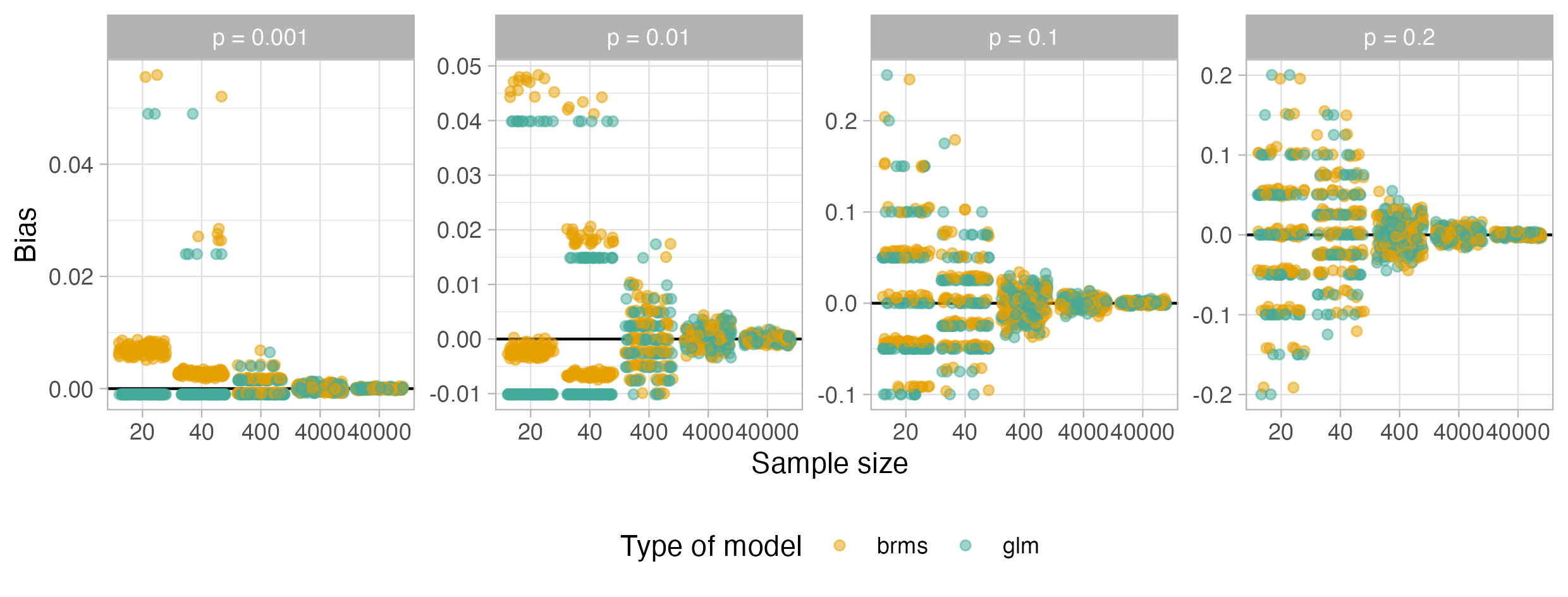
The first experiment quantifies rare-events bias in both maximum likelihood and Bayesian frameworks for logistic regression. Under small sample size and rare prevalence, classical rare-events bias leads to negative bias in prevalence estimates. However, in Bayesian versions with weak priors, the bias is often positive due to prior mass overwhelming sparse data; with larger sample sizes (e.g., n=4000, p=0.01 in motivating data), neither bias is strongly present.
Figure 2: Distribution of bias in prevalence estimates between Bayesian and classical logistic models under rare-event settings.
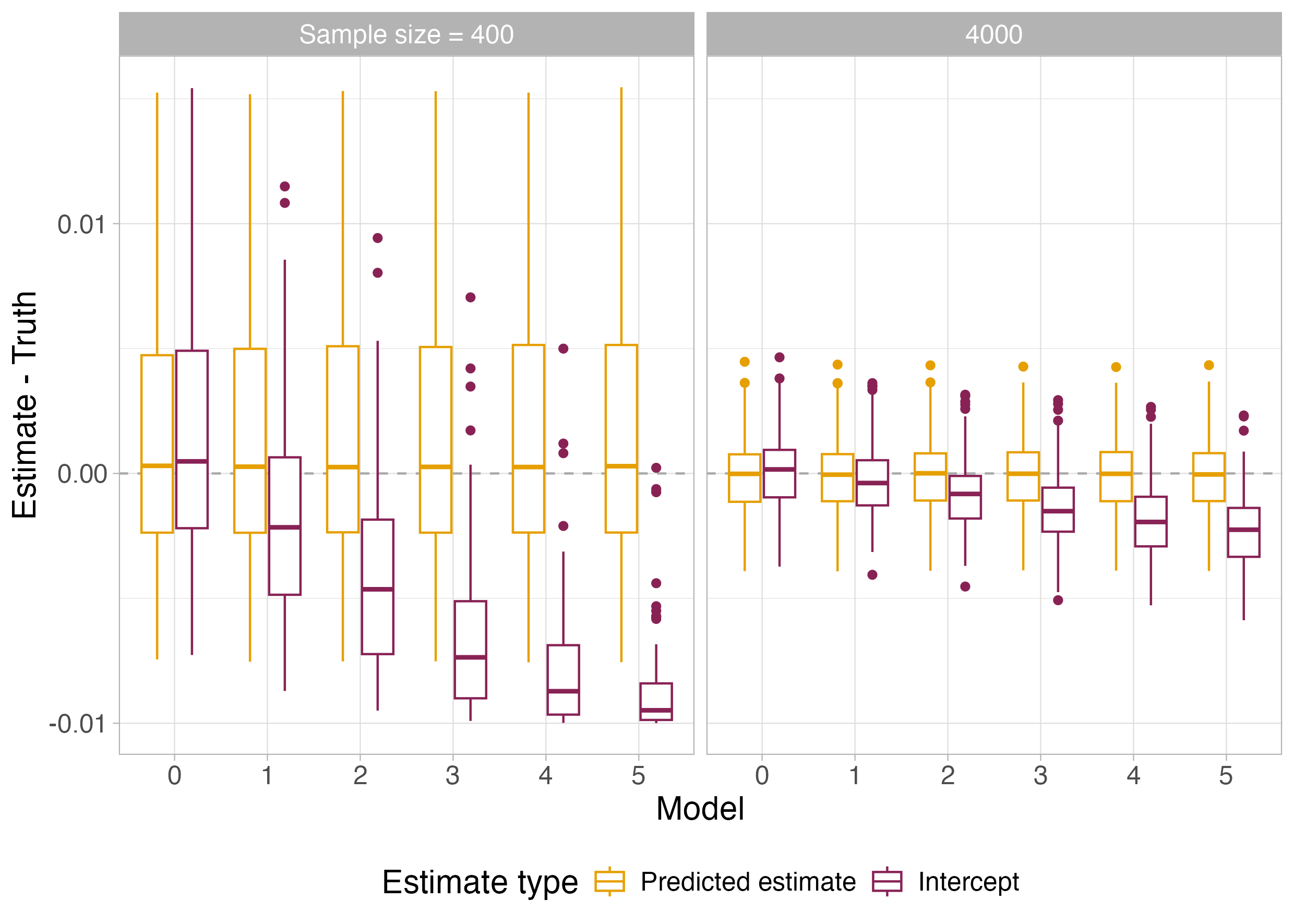
When additional covariates are sequentially added, bias accumulates in intercept estimates but is offset by other parameter biases, such that the poststratification aggregate prevalence estimate is comparatively unaffected, even as the model grows more complex.
Figure 3: Increasing negative bias in intercept estimates as number of covariates increases; overall prevalence estimate remains stable for adequate sample size.
Experiment II: Incorporating Measurement Error
When specificity is incorporated as a fixed parameter, the prevalence estimate shifts vertically but remains unbiased relative to the true population prevalence, especially for larger calibration sample sizes. The artifact appears when specificity is estimated from limited external data; as the model grows more complex, partial pooling intensifies and the prior becomes more influential, resulting in systematic downward bias in prevalence estimates.
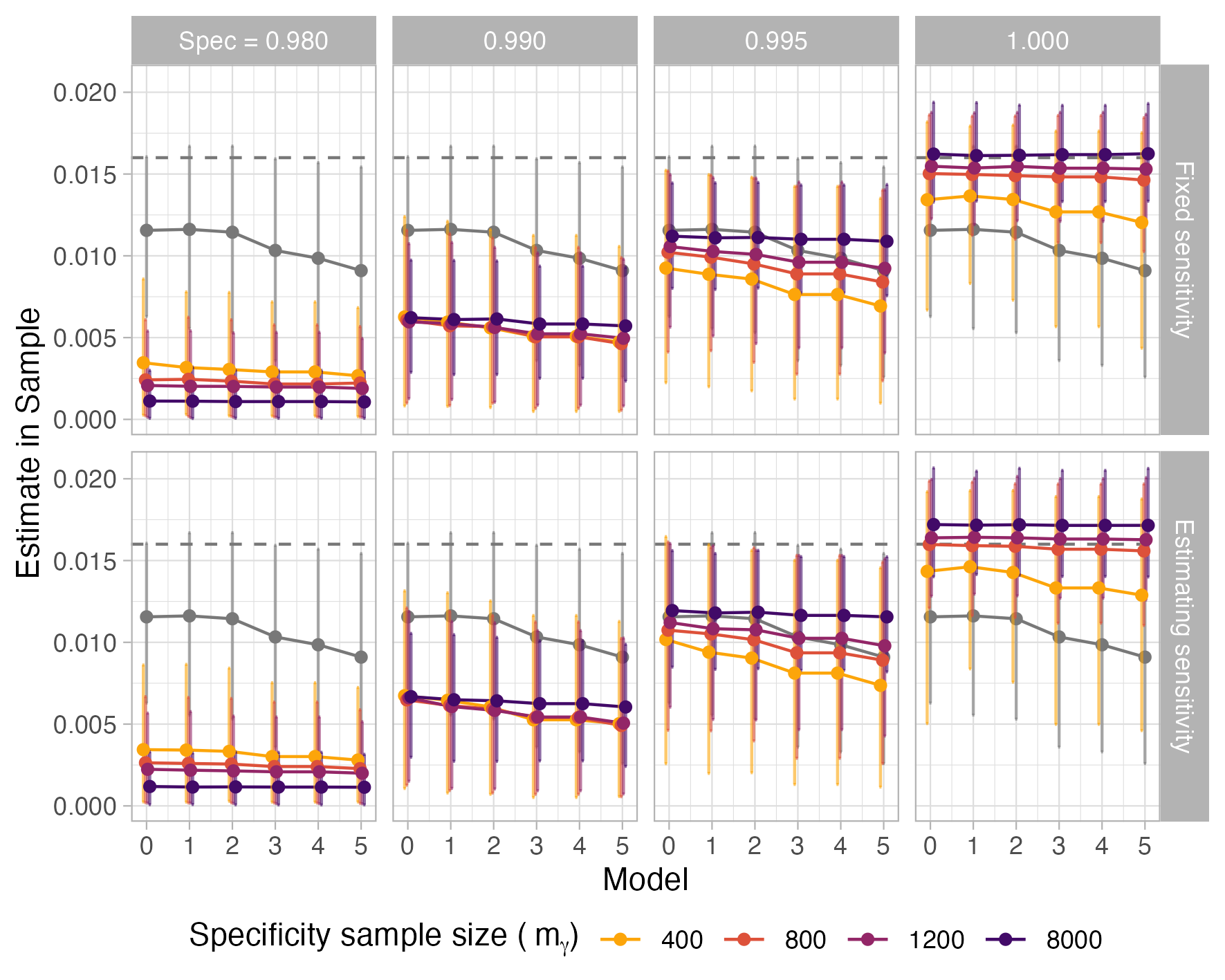
Figure 4: Difference between estimated prevalence and true prevalence, showing increased negative bias as specificity is estimated and models become more complex.
With real data, when specificity is estimated (rather than fixed), the prevalence estimate shows increased downward trend as the complexity of the MRP model increases, especially when calibration sample size for specificity estimation is small.
Figure 5: COVID-19 antibody prevalence estimates for sequential models, stratified by specificity and calibration sample size; increased bias for smaller mγ and more complex models.
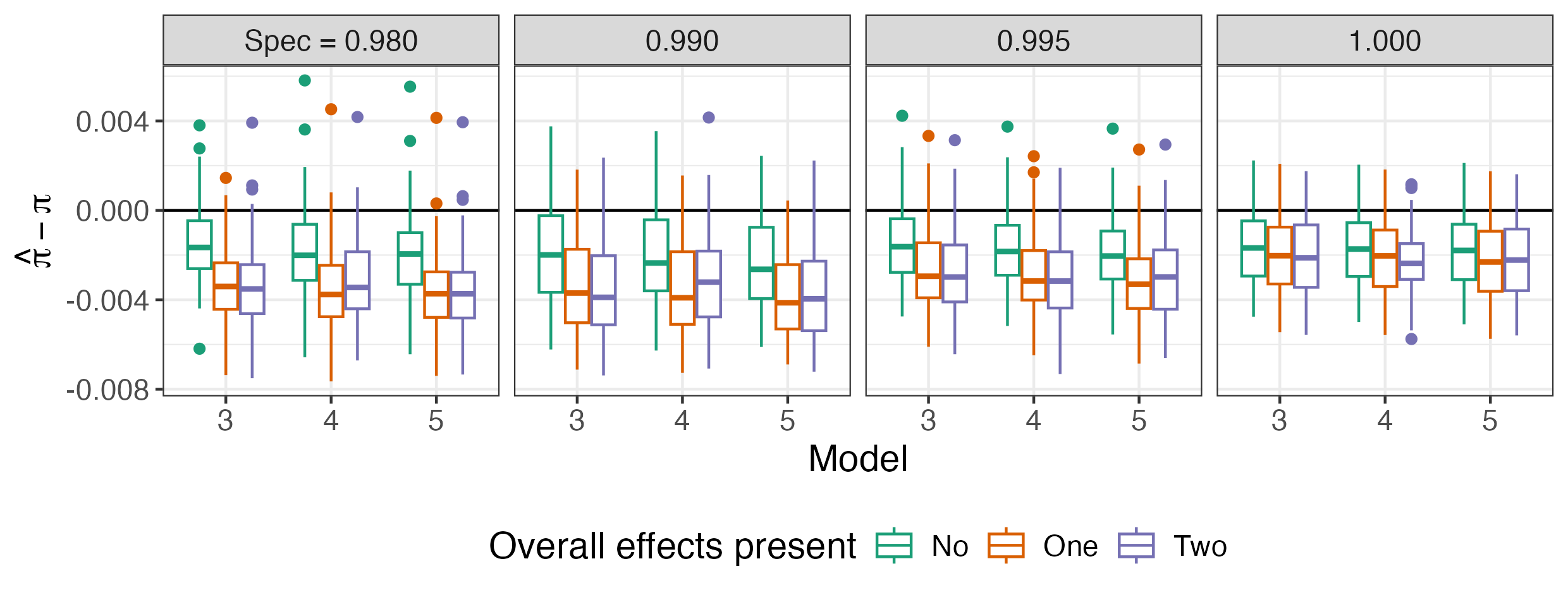
Experiment III: Adding Non-Varying Effects
The third experiment examines the effects of encoding fixed (non-varying) and varying effects for correlated covariates (e.g., SEIFA and postcode), as well as coding binary covariates (e.g., sex) as fixed effects. The addition of such terms in models with limited specificity calibration data further exacerbates downward bias, via intensified partial pooling and feedback between prior specification and specificity estimation.
Figure 6: Difference in estimated and true prevalence by number of fixed effects; downward bias intensifies as more overall effects terms are introduced.
Figure 7: Predicted estimates across model complexity for real data, color-coded by number of fixed effect terms removed—removal stabilizes estimates.
Feedback Mechanisms and Prior Effects
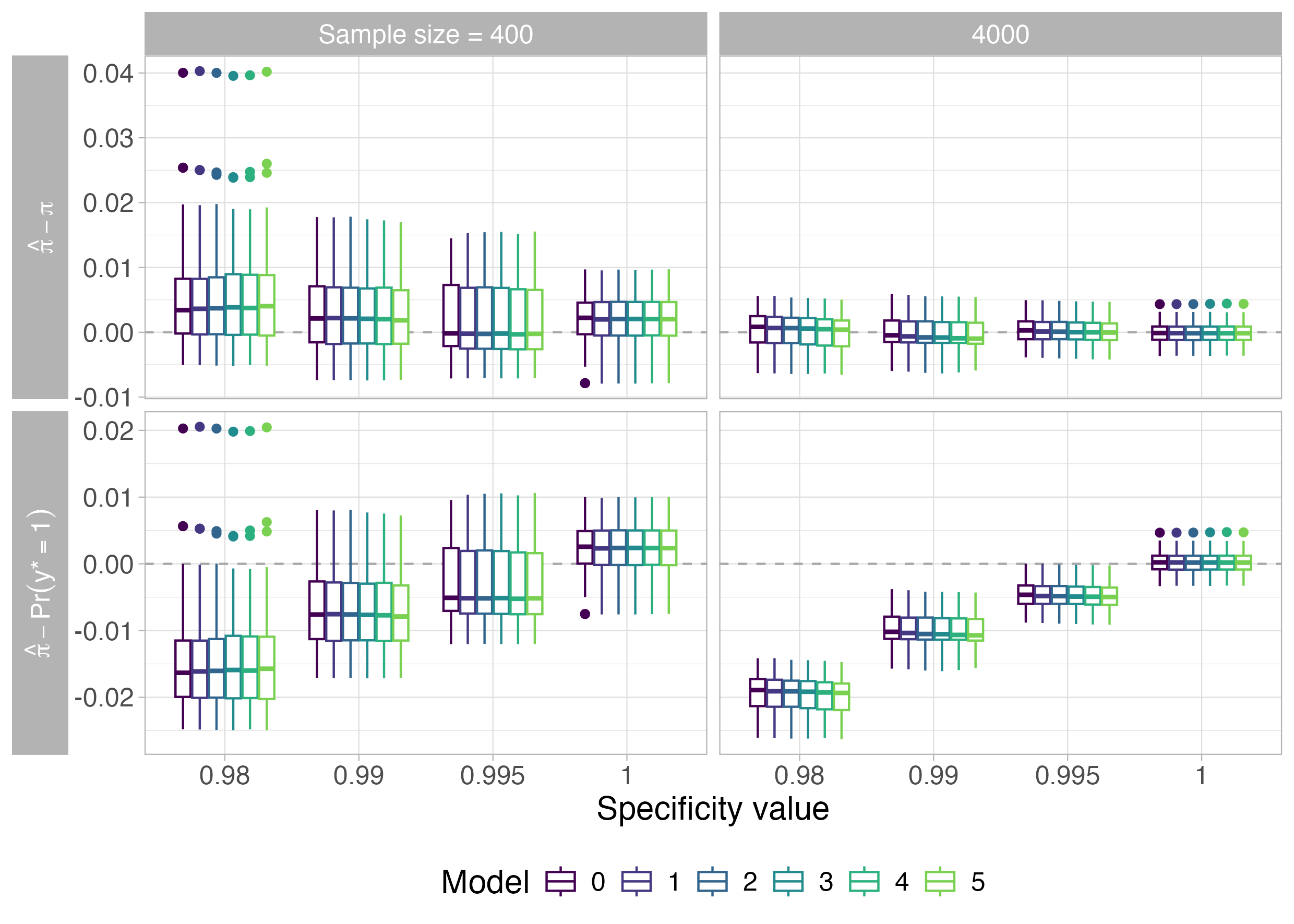
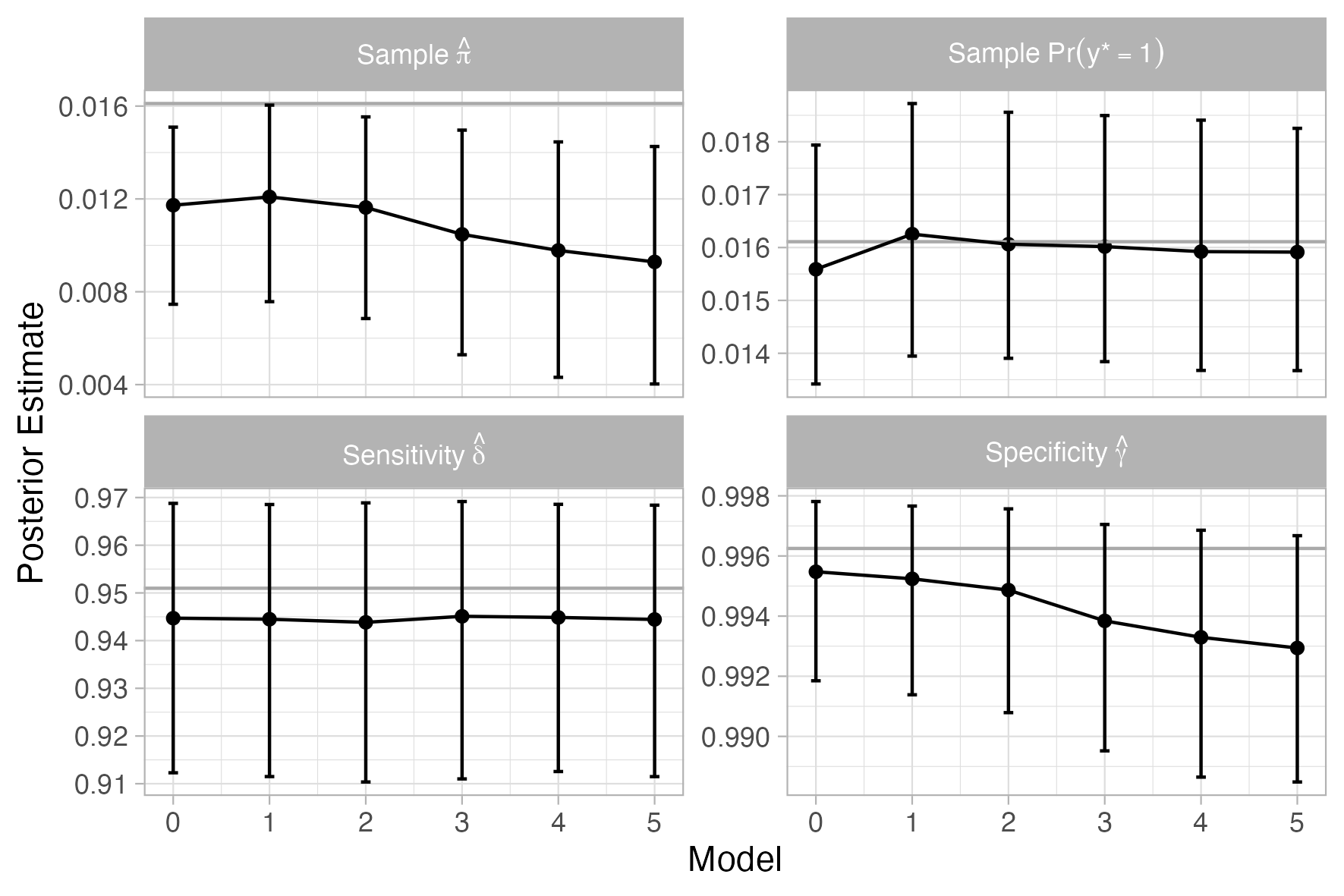
Joint consideration of prevalence estimates and specificity parameter posteriors reveals that as model complexity increases, partial pooling leads to concentration of prior mass, which shifts specificity estimates downward. This effect is amplified when calibration sample size (mγ) is small, reflecting insufficient information to anchor specificity estimates against prior influences.
Figure 8: Posterior estimates for population prevalence and specificity, showing decreasing trends with increased model complexity.
Figure 9: Prior predictive distributions for prevalence and specificity, illustrating increasingly regularized and non-uniform prior mass as model complexity increases.
This dynamic creates a feedback loop in the hierarchical Bayesian MRP framework: increased partial pooling (from weakly regularized priors and higher-dimensional models), alters specificity estimates, which then biases prevalence estimates, especially in rare-event and sparse-calibration settings.
Recommendations and Implications
The analysis yields several practical and theoretical recommendations for Bayesian prevalence estimation with MRP:
Posterior predictive checks should be targeted at the aggregate estimand, not just individual cells.
Calibration sample size for specificity estimation is critical; small mγ amplifies prior-driven artifacts.
Increasing model dimensionality (via additional covariates or non-varying effects) intensifies partial pooling and increases risk of bias.
Modelers should carefully scrutinize interaction between hierarchical priors, test error estimation, and covariate structure, especially in rare-event contexts.
Empirically, deviation of population prevalence estimates from sample means can be legitimate correction for measurement error, but model-driven bias—manifested as systematic decline with increasing complexity—implicates hierarchical prior feedback as primary culprit.
Conclusion
This paper demonstrates, through a rigorous diagnostic workflow and extensive simulation, that downward bias in Bayesian MRP prevalence estimation with weakly-regularized covariate adjustment arises from compounded feedback between hierarchical priors and specificity estimation, particularly when calibration data are sparse and model dimensionality is high. The findings underscore the importance of careful prior specification, sufficient calibration data, and targeted posterior predictive validation in complex prevalence estimation models. The methodology and workflow advanced here are likely to be applicable to a range of hierarchical Bayesian measurement error contexts, and open further avenues for study of regularization and prior feedback in high-dimensional Bayesian multi-component systems.