- The paper proposes four methodological shifts that redefine IRR usage, transparency reporting, LLM auditing, and validity-focused annotation practices in AIED.
- It criticizes conventional annotation methods that rely on rigid IRR metrics, highlighting risks like automation bias and the erosion of contextual nuance.
- The study underscores the need for validity-oriented evaluation frameworks to ensure that AI models deliver meaningful educational outcomes and theoretical insights.
Four Shifts for Modernizing Ground Truth in AI in Education
Overview
The work "Modernizing Ground Truth: Four Shifts Toward Improving Reliability and Validity in AI in Education" (2603.29141) articulates a critique of current annotation practices in the AI in Education (AIED) community and delineates a framework of four methodological shifts to cultivate both reliability and validity of ground truth data in educational machine learning. The study addresses pervasive issues with inter-rater reliability (IRR) metrics, the growing role of LLMs as annotators and judges, and the particular complexities of temporally segmented, multimodal educational data. The authors advocate for an evolution from threshold-based heuristics to diagnostic, transparent, and validity-oriented approaches.
Critique of Conventional Annotation and Reliability Practices
Standard AIED annotation pipelines, especially for high-inference constructs (such as engagement or confusion), frequently rely on single-metric IRR measurements (e.g., Cohen’s kappa) as acceptance criteria. This practice disregards context, the subjective nature of pedagogical phenomena, and the non-exchangeability of disagreement with labeling error. The authors marshal evidence that highlights: (1) the superficial reporting of IRR in published work, with over half of recent higher education AI studies omitting IRR or coding protocol information, and (2) the prevalence of forced consensus protocols that may obscure constructive ambiguity or erase meaningful interpretive variance among expert annotators.
Moreover, the introduction of LLMs for annotation has created new risks, including automation bias, circular validation, and the amplification of models’ shared biases. These shifts, coupled with high complexity and noise in naturalistic educational data, make current benchmarking practices insufficient for ensuring model generalizability or theoretical grounding.
Four Methodological Shifts
The authors contend that IRR statistics (kappa, alpha, etc.) should function as diagnostics for identifying latent sources of disagreement (valid ambiguity, construct underspecification, or rater heterogeneity), rather than as mechanical gates for dataset readiness. Agreement should be interpreted relative to task inference level and annotation design, supporting iterative codebook refinement and construct clarification. Reliance on rigid thresholds (e.g., κ>0.8) is discouraged, particularly for high-inference, context-dependent, or multimodal annotation regimes.
This shift is especially salient in the context of sequential and multimodal tutoring data, where temporal segmentation disagreements disproportionately deflate agreement statistics without reflecting underlying construct confusion or error.
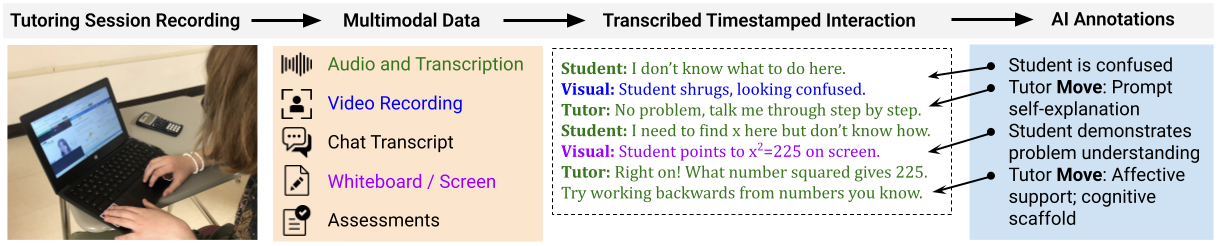
Figure 1: A processing pipeline for multimodal tutoring data, illustrating transcript generation enriched with AI-extracted features and complexity inherent to annotating educational interactions.
2. Transparent Reporting of Annotation and Reconciliation
There is a call for systematic and granular transparency in reporting rater expertise, codebook development, disagreement reconciliation procedures, and modality-specific segmentation rules. The field should move towards rigorous annotation protocols akin to established behavioral coding frameworks (e.g., BROMP), adopting mandatory reporting standards that include rater training history, demographic context, and explicit documentation of annotation edge cases. This transparency enables interpretability of IRR values and provides context for external validity assessments.
3. Audit and Verification of LLM-generated Annotations
To mitigate unique risks introduced by LLMs, the authors advocate for explicit auditing frameworks to detect automation, authority, and presentation biases in machine-generated labels. They suggest verification pipelines that use independent validation models and human-in-the-loop workflows for low-confidence or contentious cases. The "Alternative Annotator Test" is recommended to benchmark LLMs against multiple human annotators on a curated subset, justifying the substitution of human coders with LLMs only when group-level agreement is at least preserved.
Systemic biases—such as high LLM-human agreement driven by superficial heuristics—are highlighted as pitfalls, especially if models are evaluated predominantly by their ability to mimic human labels rather than support educational theory or intervention effectiveness.
4. Prioritizing Validity and Impact Over Consensus
The authors advocate for integrating multilabel and uncertainty-aware annotation schemas, expert-based adjudication, predictive validity checks (labels’ capacity to forecast independent outcomes of interest), and "close-the-loop" experimental evidence in which models’ downstream instructional impact is explicitly evaluated. This approach acknowledges pedagogical ambiguity, protects against over-indexing on rater consensus, and aligns AIED annotation pipelines with psychometric standards for both construct and consequential validity.
By prioritizing frameworks that enable nuanced, confidence-calibrated, and expert-refined ground truth, the field can achieve more robust and meaningful AI interventions—models are evaluated not merely for their fidelity to human labeling, but for their capacity to effect real learning gains and theoretical insight.
Implications for Research and Practice
The recommendations in this paper have direct implications for (1) annotation protocol design, (2) peer review norms (shifting focus from high kappa to defensible reporting and explanatory power), and (3) the development of infrastructure to support multi-label, confidence-scored, and expert-augmented annotation at scale. The adoption of these shifts will impact model selection and evaluation in AIED, as systems trained on consensus-forced or opaque annotations risk codifying human biases and may yield spurious or non-interpretable improvements in learning.
In the era of GenAI, with the automation and scaling of complex educational assessments, these recommendations are essential for preserving the scientific rigor, interpretability, and effectiveness of AI-driven educational technologies. Future progress depends on evolving from single-metric thresholding to procedural transparency, multimodal diagnostic annotation, and validity-centric evaluation frameworks.
Conclusion
This paper systematically dismantles the sufficiency of traditional IRR-centered annotation paradigms in AIED, particularly under the pressures of LLM integration and the complexity of multimodal, high-inference constructs. The four proposed shifts—redefining IRR usage, mandating annotation transparency, introducing formal auditing for LLMs, and embedding validity- and impact-centered evidence—collectively chart a path toward more reliable, interpretable, and educationally meaningful ML systems. Adoption of these methodologies is likely to concretely improve both model performance and the epistemological credibility of data-driven research in education.