- The paper presents an adaptive framework that evaluates conversation turns using a composite importance score based on semantic relevance, recency, and dialogue dependencies.
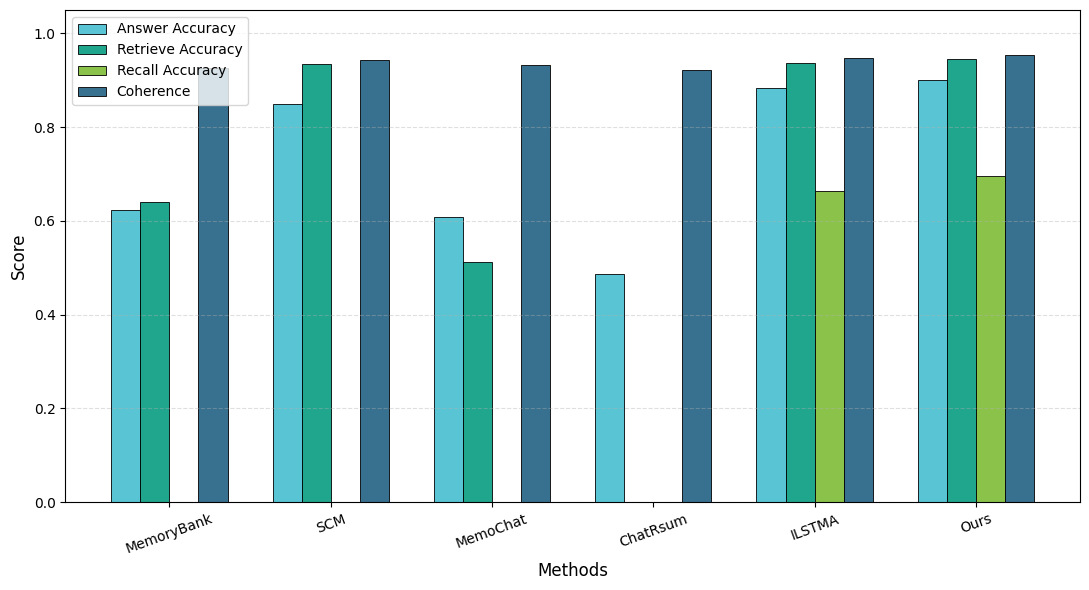
- It achieves up to 55% token reduction with improved answer accuracy (0.89–0.91) and enhanced coherence in multi-turn LLM interactions.
- The approach dynamically compresses context based on dialogue entropy and coherence filtering, outperforming fixed-memory and retrieval-only baselines.
Adaptive Context Compression for LLMs in Long-Running Interactions
Motivation and Problem Setting
Maintaining performance of LLMs in persistent interaction scenarios is significantly constrained by context window limitations, computational overhead, and memory saturation. As session lengths increase, naive approaches—such as fixed context truncation or static summarization—cause critical historical information to be lost, producing context decay and noticeable declines in response consistency. This degradation places hard limits on the deployment of LLM-based systems in multi-turn and session-spanning applications where continuity, memory retention, and efficiency must be balanced. This work formulates the problem as one of adaptively compressing context without sacrificing retrieval and reasoning quality, notably in benchmarks for conversational memory and long-context understanding.
Adaptive Context Compression Framework
The proposed framework formulates context management as a dynamic joint optimization of recall fidelity, coherence preservation, and token-level efficiency. Each conversational turn is evaluated with an adaptive importance score—a linear combination of semantic similarity (via context-query relevance), recency, and explicit dialogue dependencies. These produce a temporally and conversely sensitive ranking for compression operations.
Critically, the method hierarchically partitions memory into:
- High-importance turns for verbatim retention,
- Medium-importance segments for summarization,
- Low-importance segments for removal,
with dynamic thresholds that respond to evolving session properties and interaction complexity.
The compression process incorporates a coherence-sensitive filter, employing a contradiction probability estimator to quantify the coherence risk when context elements are removed or summarized. The context compression operator is driven by an adaptive token budget, modulated according to dialogue entropy, ensuring that unpredictable or complex sessions receive expanded budgets, while lower-entropy exchanges are compressed more aggressively.
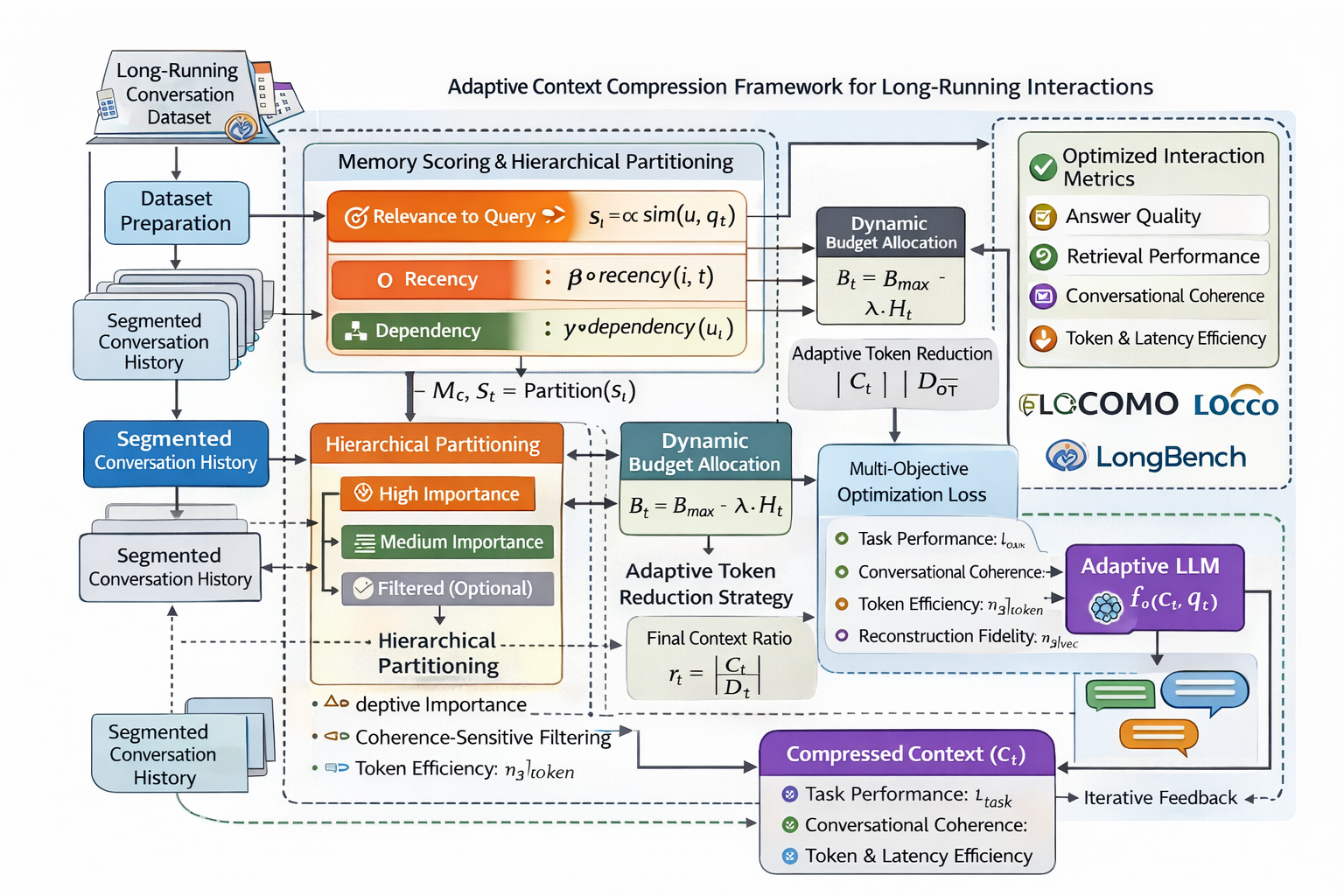
Figure 1: The adaptive context compression pipeline integrates importance scoring, coherence filtering, dynamic memory hierarchy, and architecture for context optimization in ongoing LLM dialogues.
A multi-objective loss, Lfinal, integrates task-specific performance, coherence penalties, and a token efficiency term, with an enforceable BLEU-based reconstruction constraint for information drift suppression. The framework, implemented as an inference-time preprocessing and memory management layer, is designed for compatibility with modern memory-augmented LLM agents.
Empirical Evaluation
Benchmarks and Methodology
The evaluation encompasses three primary benchmarks:
- LOCOMO: Long-horizon, multi-session QA for memory retention and retrieval analysis
- LOCCO/LOCCO-L: Consistency and coherence in memory after repeated compression cycles
- LongBench: Multi-task, long-context evaluation for reasoning and efficiency
Sessions are processed with adaptive compression prior to LLM inference, using fixed and variable context budgets, and are scored using answer accuracy, retrieval F1/Recall@k, coherence (consistency/coherence metrics), token reduction, and latency.
Main Results
The adaptive framework delivers:
Efficiency scores outpace recent schemes such as ILSTMA (21.45% execution time reduction), LAVA (>9× decoding speedup with negligible extra computation), and ATACompressor (up to 27× compression ratios), while maintaining answer quality and stability.
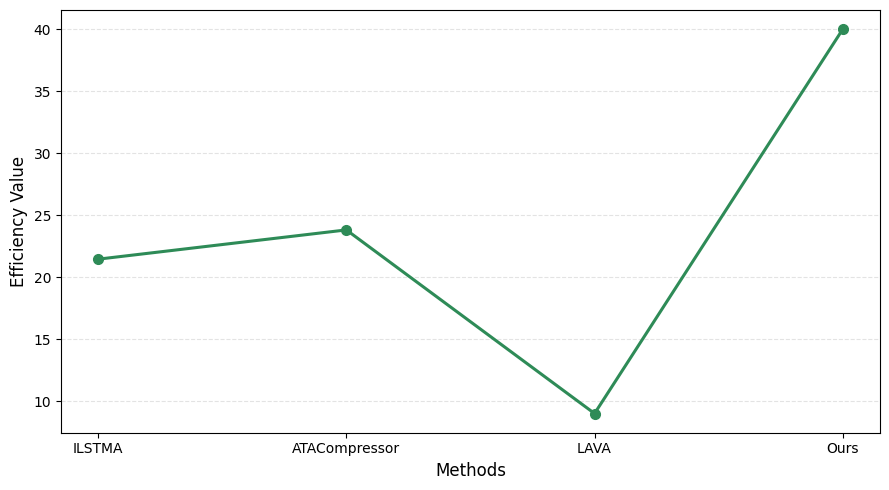
Figure 3: Token and latency efficiency comparison, showing adaptive context compression outperforms fixed and task-agnostic methods without loss of accuracy.
Analysis of Coherence and Long-Term Memory
Experimental results confirm that explicit coherence-sensitivity in context pruning prevents context drift and catastrophic forgetting typical of token-budget optimizers. Dialogue units critical for causal consistency and cross-session references are preferentially preserved due to combined scoring, differentiating the framework from context window extenders or memory-only retrievers. The method achieves consistency and coherence improvements over LOCCO benchmarks, indicating suitability for agents in persistent dialogue or QA settings.
Theoretical and Practical Implications
The methodological advance consists of closing the gap between efficiency-driven context compression and long-term conversational coherence. By making context inclusion dependent on both semantic relevance and coherence risk, the approach provides a defense against the context "flushing" or informational entropy buildup that afflicts large window inputs in memory-augmented transformers. The framework's results demonstrate that adaptive budgets and real-time filtering outperform fixed-window strategies, especially as session durations grow or as memory requirements move into the hundreds of turns.
Practically, this enables deployment of multi-turn agents with theoretical guarantees against abrupt context decay, while minimizing hardware and inference costs. These robust properties are critical for the scalability of LLMs in settings such as customer service, process automation, or multi-session task workflows.
Future Directions
The synergy between dynamic memory selection, coherence maintenance, and adaptive token budgeting opens several avenues:
- Extension to multi-agent conversational ecosystems where shared memory consistency is a requirement;
- Integration with fine-grained user simulation benchmarks to optimize over personalized dialogue retention;
- Hardware-aware implementations where context compression can be co-designed with efficient decoding pipelines for edge and mobile deployment.
Conclusion
This study provides a comprehensive framework for adaptive context compression in long-running LLM interactions, demonstrating superior answer quality, retrieval performance, and coherence compared to prior art, with notable efficiency gains. The explicit integration of coherence metrics into compression and the practical realization of dynamic context budgeting are key contributions, facilitating the deployment of scalable, stable dialogue agents in persistent or resource-constrained environments. The results suggest a paradigm for efficient, high-fidelity context management as LLM applications continue to scale in duration, complexity, and user expectations.