- The paper demonstrates that 43.2% of LLM prompts are factoid, highlighting unnecessary energy usage in routine queries.
- It employs a NIST-inspired taxonomy combined with manual annotation to reliably classify prompt complexity in software development contexts.
- The study indicates that substituting factoid queries with lower-cost alternatives could reduce energy consumption by up to 45%.
Sustainable AI Assistance Through Digital Sobriety: An Expert Analysis
Context and Motivation
The deployment of LLM-based assistants at scale has rapidly increased resource consumption associated with both training and inference. While model- and hardware-level optimizations remain primary areas of research attention, this paper systematically analyzes the behavioral dimension of AI sustainability, operationalizing the notion of "digital sobriety"—the principle of invoking AI only when genuinely necessary. The authors target software development contexts, utilizing a sample of 148 LLM prompts to empirically estimate the prevalence of unnecessary queries. Their methodology centers on distinguishing prompts that require deep, context-sensitive reasoning from those answerable by lower-cost resources such as search engines or documentation.
Methodology
This analysis uses a randomly selected subset from the LMSYS-Chat-1M dataset, applying both automated filtering and manual annotation. Prompts are categorized according to an NIST-inspired AI use taxonomy and a three-level complexity schema: "factoid" (trivial, searchable), "convenience" (nontrivial but not requiring deep reasoning), and "complex" (demanding analytical synthesis or decision-making). Manual annotation is explicitly selected to ensure explainability and reproducibility in a research context where automated classification of necessity is not yet reliable. Throughout, explicit exclusion criteria are rigorously implemented to ensure data quality and focus.
Key Findings
A core result is that 43.2% of analyzed LLM prompts are factoid, that is, unnecessary from a sustainability and resource efficiency standpoint. The prevalence of unnecessary use is not uniformly distributed across use cases. Specifically, information retrieval tasks are dominated by low-complexity queries: 76% of information retrieval queries are classified as factoid.
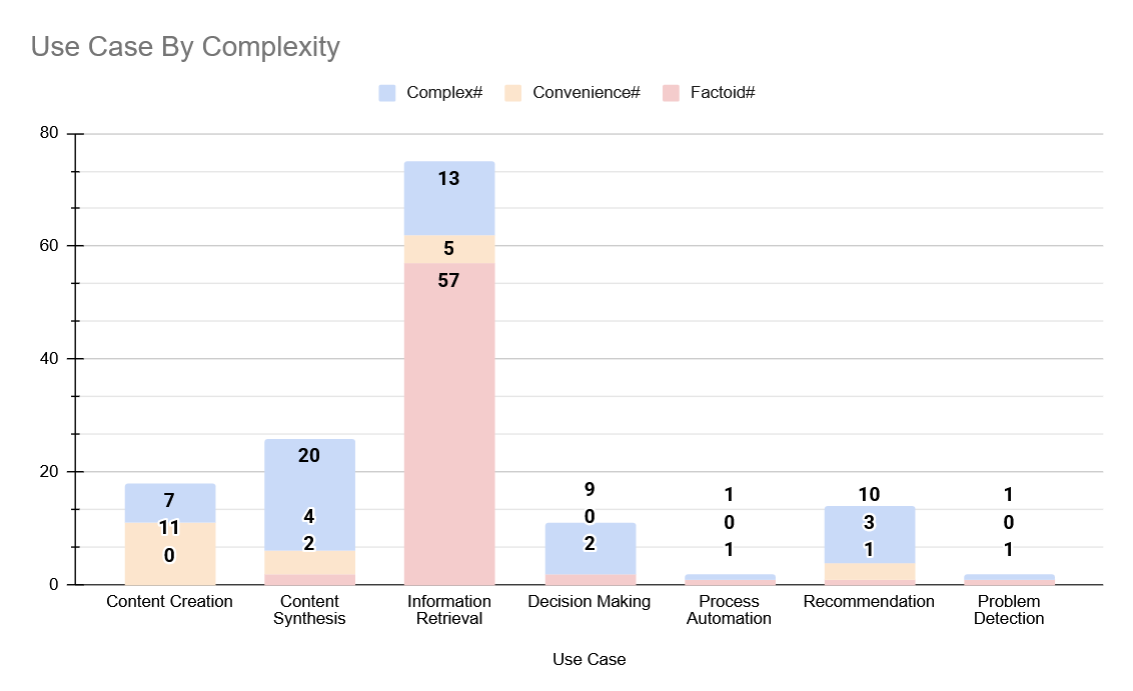
Figure 2: Distribution of prompt complexity across primary AI use cases in the analyzed sample, highlighting the concentration of factoid queries in information retrieval.
In contrast, content synthesis, recommendation, and decision-making uses strongly correlate with complex reasoning-required queries, justifying LLM invocation from an energy efficiency perspective. The "convenience" category—comprising queries that could plausibly be automated but are nontrivial—represents a smaller, nuanced domain requiring further scrutiny.
Theoretical and Practical Implications
The principal implication is a reframing of sustainable AI: demand-side intervention via digital sobriety holds quantifiable promise alongside the dominant focus on technical optimization. If a substantial fraction of LLM use, particularly in information retrieval and boilerplate generation, can be replaced by lower-cost systems, the aggregate reduction in energy and emissions could be significant. The authors estimate that eliminating unnecessary factoid queries could yield energy reductions on the order of 45% in these workloads, assuming plausible efficiencies of AI vs. search engine queries and broad demand reduction.
Operationalizing digital sobriety as a design principle opens several research and engineering directions:
- Interface-level interventions and user education: Systematic nudging to redirect factoid-style prompts to better-suited tools.
- Dynamic resource allocation architectures: Intelligent routing of requests to lightweight models or conventional search depending on predicted query complexity, leveraging prompt classification techniques.
- Behavior-focused regulatory or incentive approaches: Pay-per-use models, user feedback on energy costs, and public reporting of demand-side sustainability metrics.
The findings recommend shifting attention from "bigger and better" models toward hybrid systems incorporating task-specific, smaller models and non-AI alternatives where possible.
Limitations and Directions for Future Work
This study is limited by its modest sample size, potential dataset biases, and the inherent subjectivity of manual annotation for task complexity. The exclusion of rare use cases (e.g., process automation) from robust statistical treatment is an explicit design constraint. Further, generative AI use beyond software development demands similar analyses in other domains, with additional validation required for cross-context generalization.
Critical follow-up work should focus on:
- Developing scalable, explainable classifiers for query complexity to enable large-scale behavioral measurement.
- Cross-validation with alternative datasets and usage logs.
- Quantifying the real-world impact of digital sobriety interventions, both on aggregate energy use and on user productivity outcomes.
- Socio-technical analysis of the drivers of unnecessary AI invocation in end-user workflows.
Conclusion
This paper extends the sustainable AI discourse by empirically demonstrating that end-user behavior—specifically, the frequent invocation of LLMs for low-complexity, factoid queries—constitutes a major share of avoidable resource consumption in software development contexts. The results provide strong evidence that digital sobriety can function as a practical strategy for Green AI, with the potential for substantial reductions in compute and environmental footprints. System designers and the research community are encouraged to prioritize demand-modeling, interface nudges, and task-routing mechanisms in future work, with the larger objective of aligning LLM deployment with both economic and environmental sustainability goals.