- The paper introduces MS-Emulator, a GPU-native reinforcement learning framework that achieves precise and diverse emulation of complex human movements.
- It integrates a detailed musculoskeletal model with over 700 muscle-tendon units, yielding mean joint-angle errors of ≤2° in steady locomotion.
- The approach leverages value-guided flow exploration to efficiently navigate high-dimensional muscle actuation spaces while overcoming traditional CPU bottlenecks.
Scaling Whole-Body Human Musculoskeletal Behavior Emulation for Specificity and Diversity
Introduction
Emulating human whole-body musculoskeletal behavior with both specificity (accurate trajectory reproduction) and diversity (retention of the feasible solution manifold) is a central challenge in computational neuroscience, biomechanics, and embodied AI. Wei et al. present MS-Emulator, a high-throughput, GPU-native simulation and reinforcement learning pipeline that enables precise, diverse, and efficient reproduction of complex human movements in a detailed musculoskeletal model with approximately 700 muscle-tendon units (2603.29332). The framework addresses critical optimization and computational bottlenecks in scaling RL-based motion imitation for musculoskeletal control, and provides a tractable avenue to interrogate the internal dynamics underlying observable human movement.
Framework Design
The MS-Emulator framework is composed of three primary modules:
- GPU-parallel musculoskeletal simulation: A detailed anatomical model (MS-Human-700) is integrated with the MuJoCo Warp GPU physics backend, supporting thousands of parallel rollouts with rich access to internal joint, muscle, and force states.
- Unified motion-imitation environment with adversarial rewards: Tracking errors are adaptively aggregated via a discriminator-based reward (not manually engineered), serving as instantaneous feedback for policy optimization across diverse motor behaviors.
- Scalable flow-based exploration in RL: A value-guided probability flow parameterization enables efficient, directed exploration of the high-dimensional muscle actuation space without imposing low-rank priors or limiting solution diversity.
This architecture eliminates the CPU throughput bottleneck, avoids manual reward shaping, and significantly improves the scalability of control policy training.
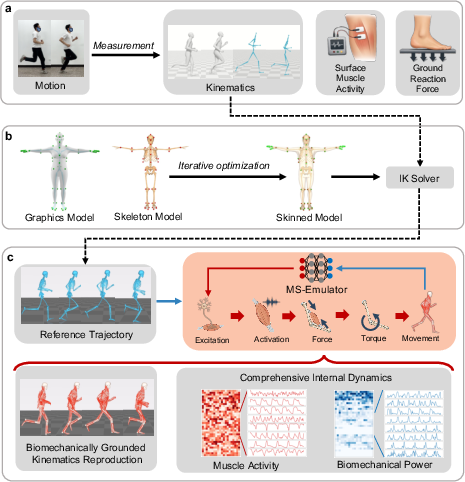
Figure 1: Workflow for retargeting experimentally measured kinematics onto the musculoskeletal model, yielding tractable internal dynamics emulation beyond observable signals.
Simulation and Control Methodology
The GPU-native pipeline compiles muscle-actuated full-body dynamics (with neural excitation, muscle force, complex constraint resolution) directly into CUDA kernels. A large set of parallel environments is stepped efficiently, with simulation throughput exceeding 7,000 steps/sec per device in benchmarks. The motion imitation environment extracts kinematic and muscle states, computes tracking errors with respect to reference trajectories, and forms a high-dimensional error vector. This error is mapped to a reward by an adversarial discriminator, enabling implicit curriculum learning and robust pose fidelity across tasks.
Control policies operate in the 700-dimensional muscle excitation space, parameterized as a Gaussian initial sampler refined by a learned flow field. Training leverages policy gradients for the base sampler and flow matching for the velocity field, with target actions directed along the value gradient of a learned Q-function. Unlike conventional RL with isotropic Gaussian exploration, this facilitates accelerated convergence and solution diversity in over-actuated systems.
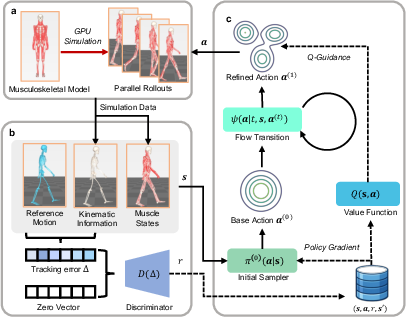
Figure 2: Overview of the parallel simulation framework, adversarial reward mechanism, and value-guided policy architecture for muscle-actuated control.
Kinematic Specificity and Versatility
The framework is validated on a broad repertoire of skills extracted from large-scale motion-capture datasets, including cyclic locomotion (walking, running), agile maneuvers (backflip, cartwheel), and fine-grained actions (dancing). Tracking accuracy is evaluated using joint-angle and body-segment errors; on steady locomotion, mean joint-angle errors are ≤2∘, and across highly dynamic maneuvers, errors remain below 7∘, with robust temporal and spatial alignment to reference trajectories. The system demonstrates low inter-trial variance, indicating convergence to consistent and stable policies without imposing single-solution bias.
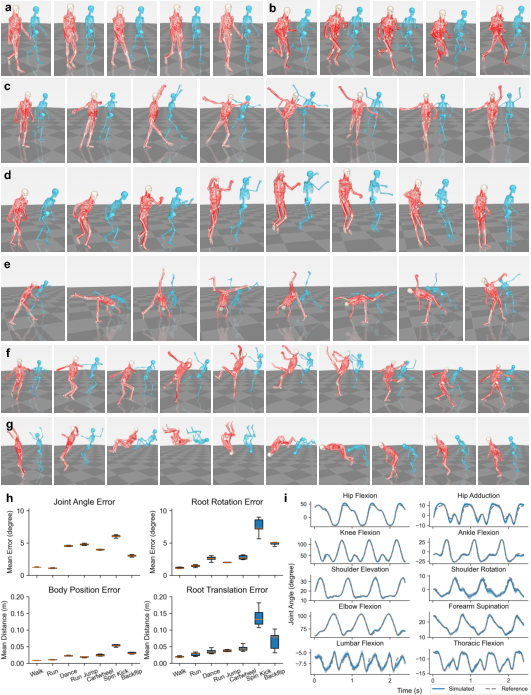
Figure 3: High-fidelity tracking of diverse motor skills by the musculoskeletal agent and quantitative evaluation of tracking errors and temporal agreement.
Computational Efficiency and Sample Efficiency
MS-Emulator's large-scale parallelism enables rapid training of complex controllers. Simulation and training throughput are both measured to scale linearly with the number of parallel environments up to hardware limits, with a single RTX 5090 achieving 4,460 SPS for end-to-end RL training. On both simple (walking) and dynamically demanding (running) tasks, value-guided flow exploration outperforms PPO baselines, yielding faster convergence and lower asymptotic errors with identical environment, hyperparameters, and initializations.
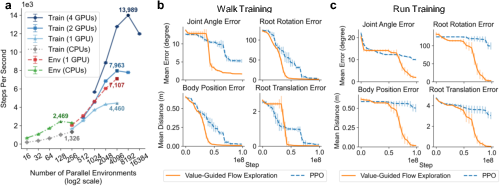
Figure 4: Benchmarks of simulation and training throughput versus parallelization, and tracking error convergence for value-guided flow exploration versus PPO.
Redundant Solution Manifold and Internal Dynamics
A core contribution is empirical verification of the redundancy in musculoskeletal control. The authors train ensembles of policies on the same walking trajectory under three reward regimes: pure imitation, imitation with EMG regularization (to steer muscle activity towards experimental surface EMG), and imitation with muscle power regularization. Policies subject to EMG agreement show high correlation with measured EMG (r=0.973), while power-regularized and imitation-only policies diverge internally but still achieve nearly perfect external kinematics and contact force profiles. Principal component analysis of solution manifolds reveals that joint kinematics and ground reaction forces reside in a low-dimensional subspace, while muscle activity spans a gradually accumulating, high-dimensional space, indicating a broad null space for internal actuation under identical external constraints.
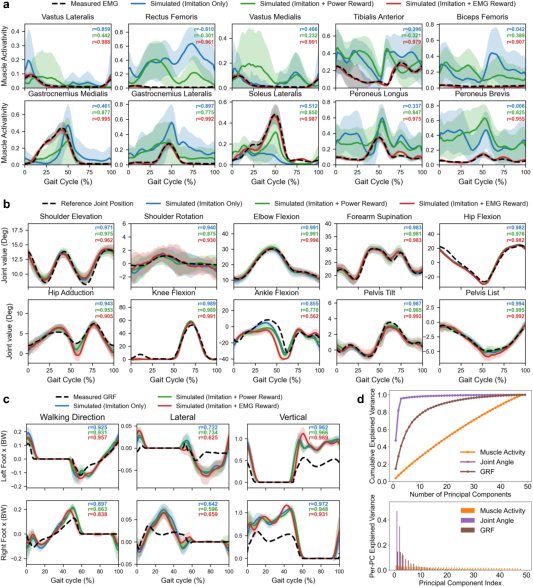
Figure 5: Comparison of simulated muscle activity, joint kinematics, ground reaction forces, and solution manifold dimensionalities across different control regularizations.
Theoretical and Practical Implications
This work establishes a scalable computational paradigm where both specificity and diversity are preserved in emulation of human movement. Unlike traditional inverse dynamics or analytically regularized control design, the RL framework exposes the manifold of plausible internal solutions given observable constraints, providing computational tools for addressing Bernstein's redundancy problem. The system's rapid, high-fidelity performance makes possible statistical analysis over large populations of motor policies and is poised to accelerate data-driven research in movement neuroscience, prosthetics, and embodied AI. The authors explicitly demonstrate that, for a single motor task, multiple muscle activation patterns can converge to identical task outcomes, reconciling the need for reproducibility with biological flexibility.
The platform is readily extensible to other species and applications, contingent on morphometric data and dynamic parameterization, and can be adapted to study the consequences of sensory noise, actuation delays, and inter-subject anatomical variability. Future research directions include integrating signal-dependent noise, soft-tissue and contact mechanics, and population-scale anatomical variation, as well as exploration of human-robot interfaces, neuroprosthesis optimization, and algorithmic advances in large-scale RL for embodied systems.
Conclusion
MS-Emulator demonstrates that high-fidelity, massively parallel emulation of full-body human musculoskeletal dynamics is feasible with current GPU computing and advanced RL techniques, supporting reproducible, diverse, and physiologically plausible motion control. This framework establishes an efficient computational instrument for probing the intersection of motor control, redundancy, and generalizable behavior emulation in biological and artificial agents.