- The paper demonstrates that LLMs generate strong clinical PA content but consistently lack complete administrative elements required for real-world payer submissions.
- The evaluation used a six-criterion rubric across three LLMs, revealing Claude Sonnet 4.5’s superior performance in denial anticipation and medical necessity argumentation.
- The study underscores that while LLMs can cut physician drafting time, integrating deterministic administrative data is essential for full PA letter readiness.
Evaluation of LLMs for Prior Authorization Letter Generation: Clinical Strengths and Administrative Gaps
Context and Motivation
Prior authorization (PA) is a major source of administrative burden in U.S. healthcare, directly contributing to clinician burnout, delayed patient care, and substantial financial costs. Despite policy shifts toward electronic PA and health IT standards, the challenge persists for most small and independent practices. While LLMs have demonstrated efficacy in medical text tasks, structured evaluation of their ability to generate clinically and administratively adequate PA letters has been limited. This study evaluates three leading commercial LLMs—GPT-4o, Claude Sonnet 4.5, and Gemini 2.5 Pro—across 45 synthetic, physician-validated PA scenarios spanning five specialties, using a meticulous six-criterion rubric and secondary analysis of administrative features.
Methodology
A total of 135 PA letters were generated across three models for 45 diverse clinical scenarios developed and iteratively validated by physicians. Prompts were standardized, omitting insurer-specific denial criteria to assess each model's embedded knowledge of payer practices. The evaluation framework encompassed clinical accuracy, medical necessity argumentation, step therapy documentation, denial anticipation, structural completeness, and professional quality. Secondary analysis quantified the presence of eight real-world administrative elements such as CPT/HCPCS codes, authorization duration, and follow-up plans. Rigorous manual audit and statistical analysis ensured reproducibility and robustness.
Findings: Clinical Content
All LLMs reliably produced PA letters with strong clinical content, achieving near-ceiling performance in reproducing ICD-10 codes, treatment details, and comprehensive step therapy documentation. Claude Sonnet 4.5 demonstrated statistically superior performance, achieving almost universal perfect scores, primarily due to its advantage in denial anticipation and medical necessity argumentation. GPT-4o lagged in denial anticipation for step therapy scenarios. Importantly, zero clinical hallucinations were detected across all letters, bolstering confidence in LLM safety under tightly structured prompts.
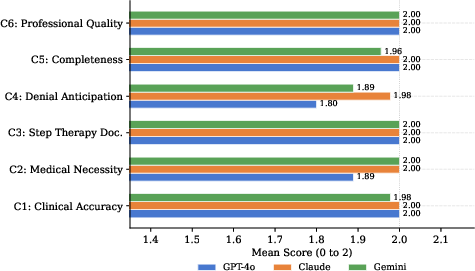
Figure 1: Mean rubric scores by criterion and model (scale: 0 to 2). C4 (denial anticipation) shows the greatest cross-model divergence. C1, C3, and C6 are at or near ceiling for all models evaluated.
Administrative Deficits
Secondary analysis exposed consistent, substantial gaps in administrative scaffolding. All models inadequately incorporated essential payer-required elements—especially billing codes and authorization duration—which are mandatory for submission readiness in real-world workflows. Claude Sonnet 4.5 and Gemini 2.5 Pro performed better than GPT-4o but still failed to meet administrative completeness in most scenarios. Inclusion rates for elements like CPT/HCPCS codes never exceeded 51%, and authorization duration was included in fewer than 30% of Claude Sonnet 4.5's letters.
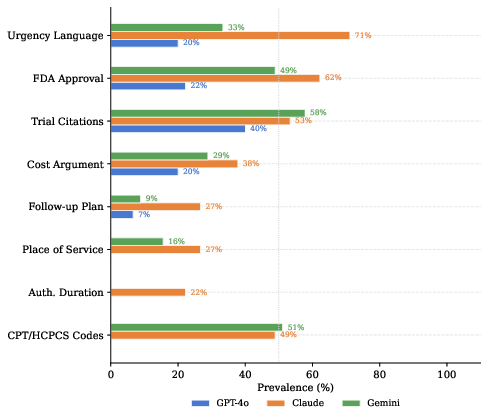
Figure 2: Prevalence of eight secondary PA letter elements by model. Billing codes and authorization duration represent the largest universal gaps. The dotted line marks 50\% prevalence.
Analysis stratified by PA challenge type revealed a concentrated deficit in GPT-4o's denial anticipation for medication step therapy, achieving full credit in only half the relevant scenarios, in contrast to near-perfect performance from Claude Sonnet 4.5 and Gemini 2.5 Pro.
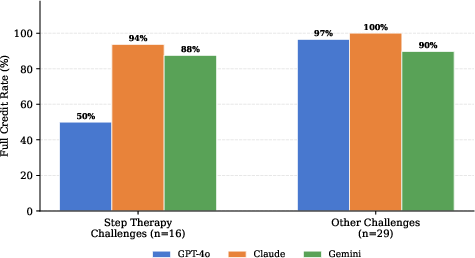
Figure 3: C4 (denial anticipation) full credit rates stratified by PA challenge type. GPT-4o shows marked deficit on step therapy challenges relative to Claude Sonnet 4.5 and Gemini 2.5 Pro.
Performance across specialties was uniformly strong, with scenario-specific complexity (novel drug approvals, discretionary insurer policy) being a stronger predictor of imperfect scores than specialty.

Figure 4: Mean total score by model and clinical specialty (n = 9 per cell). All cells exceed 11.5/12. Perfect scores (12.00) are bolded.
Letter Length and Content Density
Models varied significantly in letter length, with Claude Sonnet 4.5 generating the most content-rich letters (M=610 words), correlating with greater inclusion of evidentiary and administrative material. GPT-4o produced letters 39% shorter on average, omitting context that could substantively influence approval outcomes.
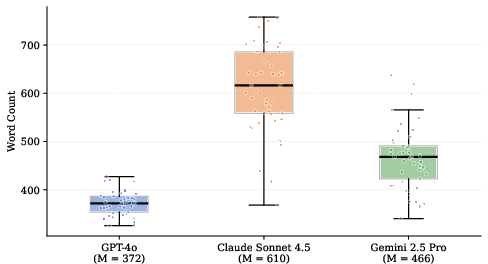
Figure 5: Word count distributions across 45 letters per model. All pairwise differences are significant (p<.001, Bonferroni-corrected). Group means shown in parentheses.
Implications and Future Directions
Practical Deployment
Findings indicate that LLMs can reliably generate clinically sufficient PA narratives, but letter completeness for payer workflows depends on integration with operational IT infrastructure. Hybrid systems must supplement LLM output with deterministic administrative elements from EHRs, formulary databases, and payer APIs—aligning with interoperability frameworks such as HL7 FHIR and transaction sets like X12 278. Retrieval-augmented generation architectures are critical.
Model Selection
Embedded payer knowledge varies across models; for deployment in environments where step therapy compliance is paramount, Claude Sonnet 4.5’s superior performance in denial anticipation recommends its preferential use unless external supplementation is available.
Physician Workflow
LLM drafts can reduce physician authoring time by over 50%, but supervised review remains essential to ensure accuracy and appropriateness—especially in boundary scenarios with recent drug approvals or ambiguous insurer policies.
Future Research
Empirical evaluation on real-world, de-identified PA cases is needed to confirm transferability. Prospective studies should investigate approval rates and turnaround times associated with LLM-generated letters. System architectures should be benchmarked for integration efficacy, administrative gap closure, and safety under less constrained prompts.
Conclusion
Systematic evaluation confirms that commercially available LLMs can generate robust clinical PA narratives across specialties. However, administrative content required for successful submission is consistently underrepresented and must be supplied by deterministic, standards-based supplementation. Claude Sonnet 4.5 demonstrates superior embedded payer knowledge, especially for step therapy. Clinical impact hinges on implementation of hybrid systems combining LLMs with structured administrative data, and rigorous validation against real-world outcomes.