- The paper identifies benchmark quality flaws that mask true AI performance in automating ELT pipelines.
- The authors introduce an Auditor-Corrector methodology that pairs LLM-driven root-cause analysis with expert validation.
- Benchmark corrections boost data transformation accuracy from 22.66% to 32.51%, highlighting previously underestimated agent potential.
ELT-Bench-Verified: Revealing Benchmark Quality as a Limiting Factor in AI Agent Evaluation
Introduction: ELT Pipelines and Benchmarking AI Automation
Automating Extract-Load-Transform (ELT) pipelines is a prominent research direction in data engineering, given their critical role in integrating and transforming heterogeneous enterprise data sources. ELT-Bench was devised as the first systematic benchmark for evaluating autonomous agents on end-to-end ELT pipeline construction. Initial studies reported strikingly low success rates, with only 37% success for extraction/loading (EL) and a mere 1% for data transformation (T), suggesting severe limitations in current agent capabilities.
However, the paper “ELT-Bench-Verified: Benchmark Quality Issues Underestimate AI Agent Capabilities” (2603.29399) elucidates two dominant confounders: rapid model advancements and pervasive benchmark quality issues. Through rigorous audit methodologies, the authors demonstrate that both factors significantly mask underlying agent performance, necessitating a benchmark re-evaluation and correction.
ELT-Bench: Task Complexity and Evaluation
ELT-Bench comprises 100 tasks requiring the agent to configure data extraction (aggregating from databases, APIs, flat files), load into a cloud warehouse (Snowflake), and then synthesize SQL transformations for analytics-ready tables (Figure 1).
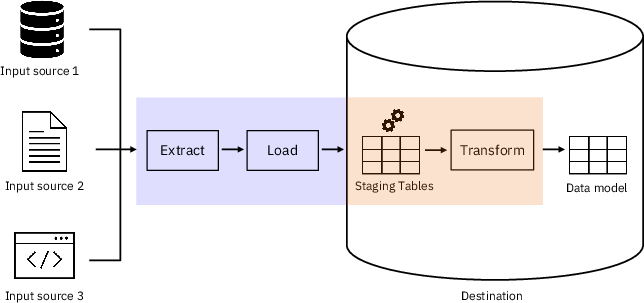
Figure 1: ELT pipeline overview from heterogeneous data sources to analytics tables.
The agent workflow is segmented into EL and T stages, each with distinct evaluation metrics: SRDEL (Success Rate for Data Extraction and Loading) and SRDT (Success Rate for Data Transformation). Tasks span multiple relational schemas and transformation complexities challenging both generalization and robustness (Figure 2).
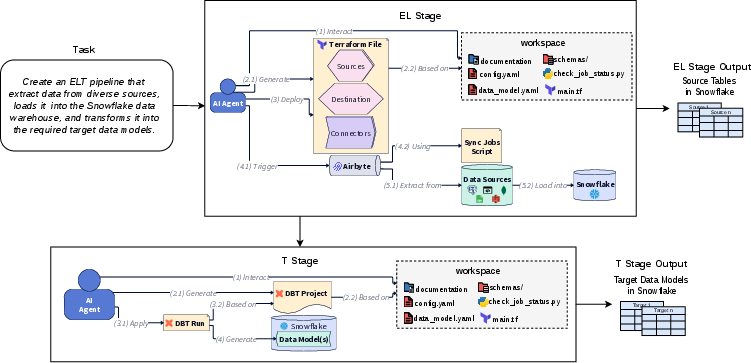
Figure 2: Agent workflow illustrating the dual-stage pipeline construction in ELT-Bench.
To isolate the effect of model advancements, the authors re-execute ELT-Bench using SWE-Agent, but swap the underlying LLM from Claude Sonnet 3.5 to Claude Sonnet 4.5. This single substitution elevates SRDEL from 37% to 96%, almost solving the extraction/loading phase for benchmark configurations, while SRDT rises from 1% to 22.66%. The transformation rate remains unexpectedly low compared to contemporary text-to-SQL benchmarks achieving over 80% execution accuracy.
Benchmark outcomes across stages are summarized visually in Figure 3.
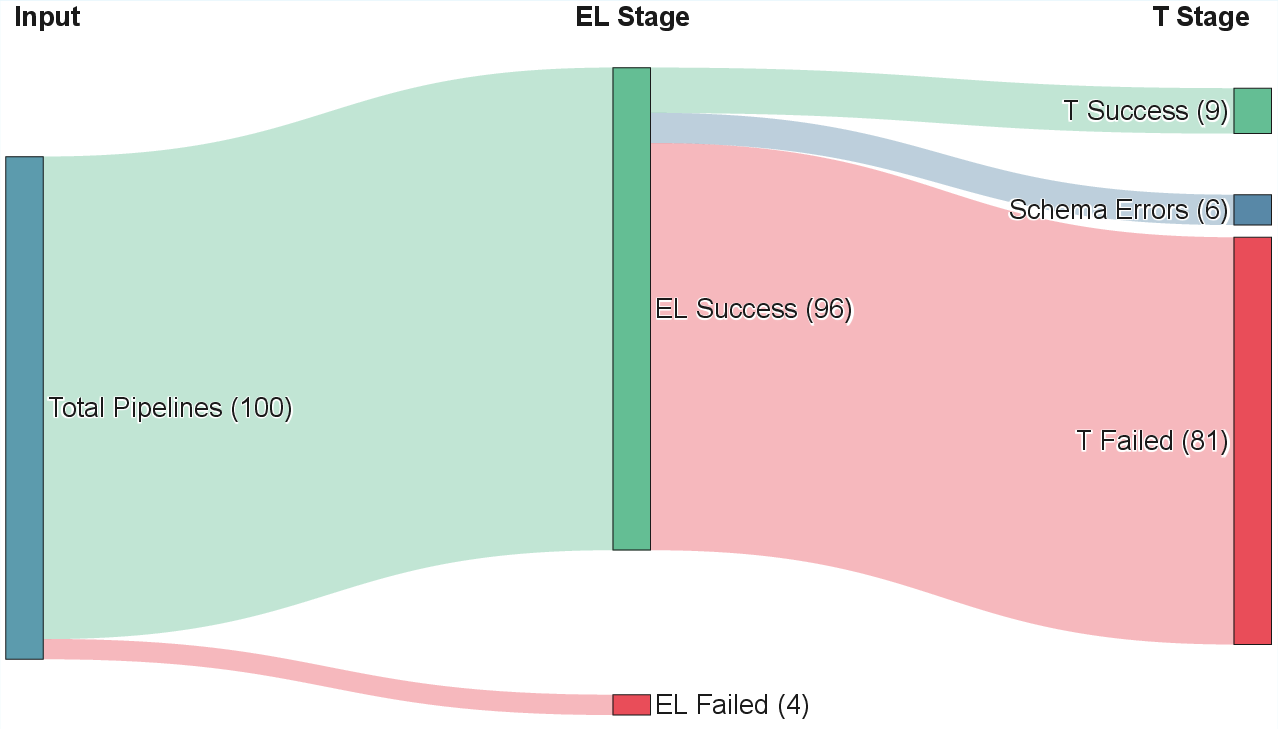
Figure 3: Sankey diagram of pipeline outcomes for extraction/loading and transformation.
Auditor-Corrector Methodology: Systematic Benchmark Quality Audit
A core contribution is the introduction of an Auditor-Corrector pipeline, combining LLM-driven root-cause analysis with expert human validation (Fleiss' κ=0.85), targeting 81 failed transformation tasks and 660 unmatched columns.
Phase 1 constructs detailed task environments for each failure, including source data, agent predictions, ground truth, and schema specifications. In Phase 2, a parallel LLM agent (Claude Opus 4.5) autonomously reverse-engineers SQL for each unmatched column, generating comprehensive analytic reports. Phase 3 involves manual expert categorization of all column mismatches by error type (Figure 4).
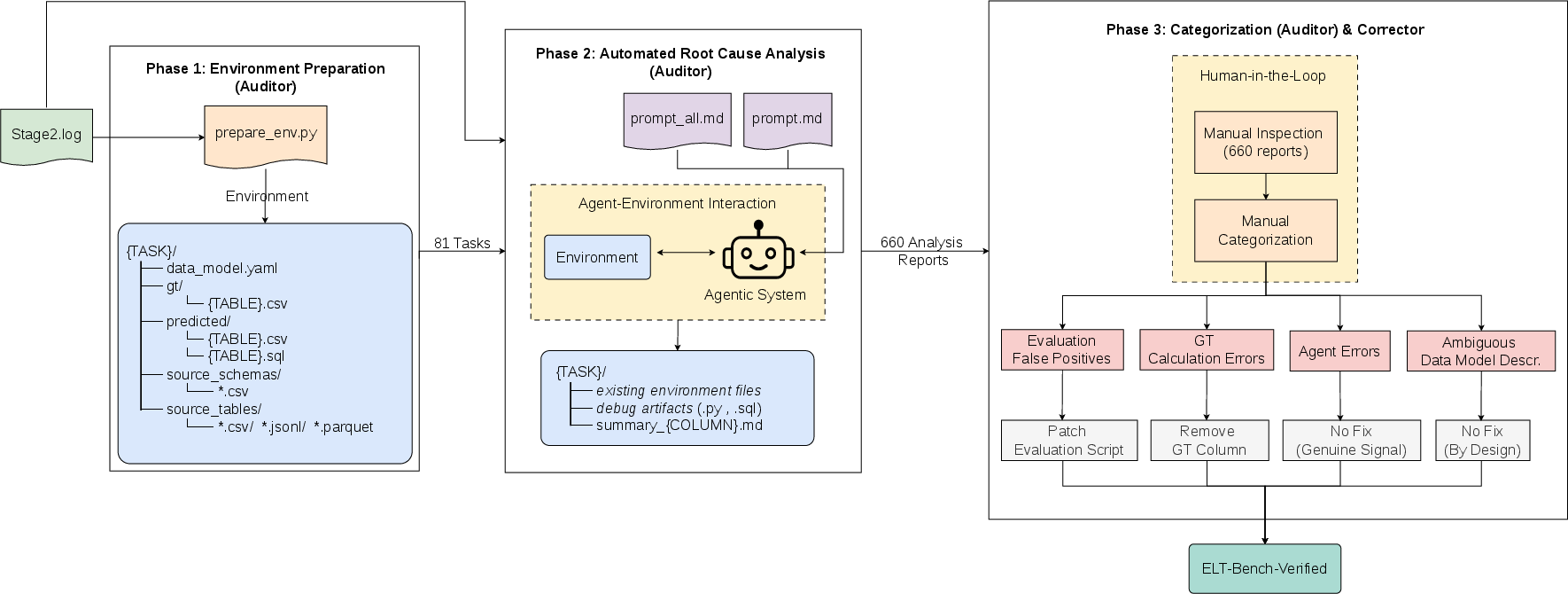
Figure 4: Overview of the Auditor-Corrector methodology for scalable quality auditing.
Benchmark-Attributable Errors: Quantification and Taxonomy
The audit reveals 82.7% of failed transformation tasks contain at least one benchmark-attributable error. At column granularity, 33% of mismatches arise from benchmark flaws rather than genuine agent limitations. These errors cluster into:
- Evaluation False Positives: Semantically equivalent outputs penalized by rigid scripts (e.g., decimal vs. percentage format).
- Ambiguous Data Model Descriptions: Underspecified requirements yielding multiple valid SQL interpretations.
- Ground Truth Calculation Errors: Incorrect or non-derivable ground truth values penalizing correct agent outputs.
The distribution of error attribution is shown in Figure 5.

Figure 5: Distribution of error attribution across failed transformation tasks and their mitigability.
Benchmark Correction: ELT-Bench-Verified Construction and Validation
Benchmark correction involves two actions:
- Evaluation script refinements: Normalization of representations (boolean, formats, NULL, ordering) to eliminate false positives.
- Ground truth column removal: Discarding 30 columns where ground truth cannot be reliably reconstructed or agreed upon by domain experts.
Ambiguous specifications are deliberately retained for evaluation, as resolving them constitutes a valid agentic capability.
Performance progression across configurations confirms both model upgrades and benchmark correction contribute significant gains (Figure 6).
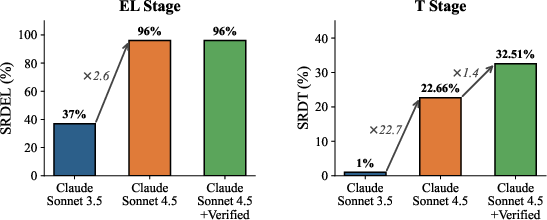
Figure 6: Performance progression: baseline, upgraded model, and verified benchmark.
After correction, SRDT rises from 22.66% to 32.51% (43.5% relative improvement), with 20 additional data models passing, attributable strictly to benchmark correction. Multi-agent validation (LangGraph ReAct/Claude-4.5) replicates these improvements, confirming corrections generalize across different agent architectures.
Error Characterization and Practical Implications
Error taxonomy analysis reveals agentic failures concentrate in SQL mechanics (flawed logic, join types), not semantic comprehension. Benchmark-attributable errors significantly skew evaluation, frequently penalizing correct agent outputs due to rigid scripts or inconsistent ground truth.
Key insights for agentic ELT system builders:
- Extraction/loading is robustly solved under current models for ELT-Bench settings.
- Transformation limitations are primarily due to SQL construction rather than task understanding.
- Benchmark quality audit is non-negotiable; otherwise, evaluation scores systematically underestimate agent capability and misdirect algorithmic development priorities.
Theoretical and Practical Implications for AI Evaluation
This work echoes recent findings in text-to-SQL benchmarking (Jin et al., 13 Jan 2026), establishing that annotation and evaluation errors are pervasive in benchmarks for multi-stage agentic tasks. The implication is that systematic quality auditing must become standard practice for benchmarks involving complex reasoning and program synthesis, as evaluation outcomes directly steer innovation trajectories.
For theory, the high proportion of benchmark errors foregrounds the difficulty of operationalizing semantic equivalence in agent evaluation—a challenge that is amplified in settings involving ambiguous specifications, rigid scripts, and business logic translation. There is scope for future research on robust evaluation methodologies, adaptive metric design, and benchmark co-evolution with agent capabilities.
On the practical front, ELT-Bench-Verified sets a precedent for rigorous benchmark maintenance. The release of refined scripts and ground truth enables reliable measurement of AI progress in agent-based data engineering, fostering both reproducible research and accelerated innovation.
Limitations and Future Directions
The audit was performed for a single agent/model configuration owing to resource constraints. Full multi-agent audits would provide broader coverage of benchmark defects. Categorization rests primarily on individual annotation with corroboration from subsamples; full blind panel annotation could further strengthen reproducibility. Future work should extend the Auditor-Corrector pipeline to other agentic benchmarks and consider robust specification languages for disambiguating transformation tasks.
Conclusion
The research demonstrates that benchmark quality issues and rapid model advancement collectively led to substantial underestimation of AI agent capabilities on ELT-Bench. Through exhaustive error taxonomy and methodology, ELT-Bench-Verified establishes a more accurate foundation for subsequent evaluation, emphasizing the necessity of systematic quality audit in agent benchmarking. The methodological framework and empirical findings are immediately relevant for any domain where agentic AI workflows are evaluated via execution-based benchmarks (2603.29399).

