- The paper presents AGFT, a framework that leverages soft probabilistic alignment to preserve semantic structure during adversarial fine-tuning.
- It combines text-guided adversarial training with temperature scaling to enhance zero-shot adversarial robustness in CLIP-based models.
- Experimental results show a 3.1% gain in robust accuracy and a 1.0% gain in clean accuracy over strong baselines while maintaining semantic structure.
Alignment-Guided Fine-Tuning for Zero-Shot Adversarial Robustness of Vision-LLMs
Introduction
This work addresses the vulnerability of large-scale pre-trained vision-LLMs (VLMs), such as CLIP, to adversarial perturbations despite their strong performance in zero-shot generalization settings. It critically examines the failure of conventional classification-guided adversarial fine-tuning, which disrupts cross-modal semantic structure and undermines zero-shot capabilities. The paper introduces the Alignment-Guided Fine-Tuning (AGFT) framework, which utilizes soft probabilistic supervision derived from the pre-trained model, instead of hard labels, to better preserve visual-textual alignment during adversarial fine-tuning. Additionally, the framework calibrates the output distribution of the robust model to match a temperature-scaled version of the pre-trained predictions, mitigating distributional mismatch and preserving semantic relationships.
AGFT Methodology
AGFT comprises two essential components: text-guided adversarial training by soft alignment and distribution consistency calibration.
After obtaining probabilistic predictions from the pre-trained VLM on clean inputs, AGFT uses these distributions as targets during adversarial fine-tuning. This supervision aligns adversarial image features with multiple text embeddings, maintaining fine-grained semantic correspondence even under attack, unlike hard label-based objectives that collapse similarity structure.
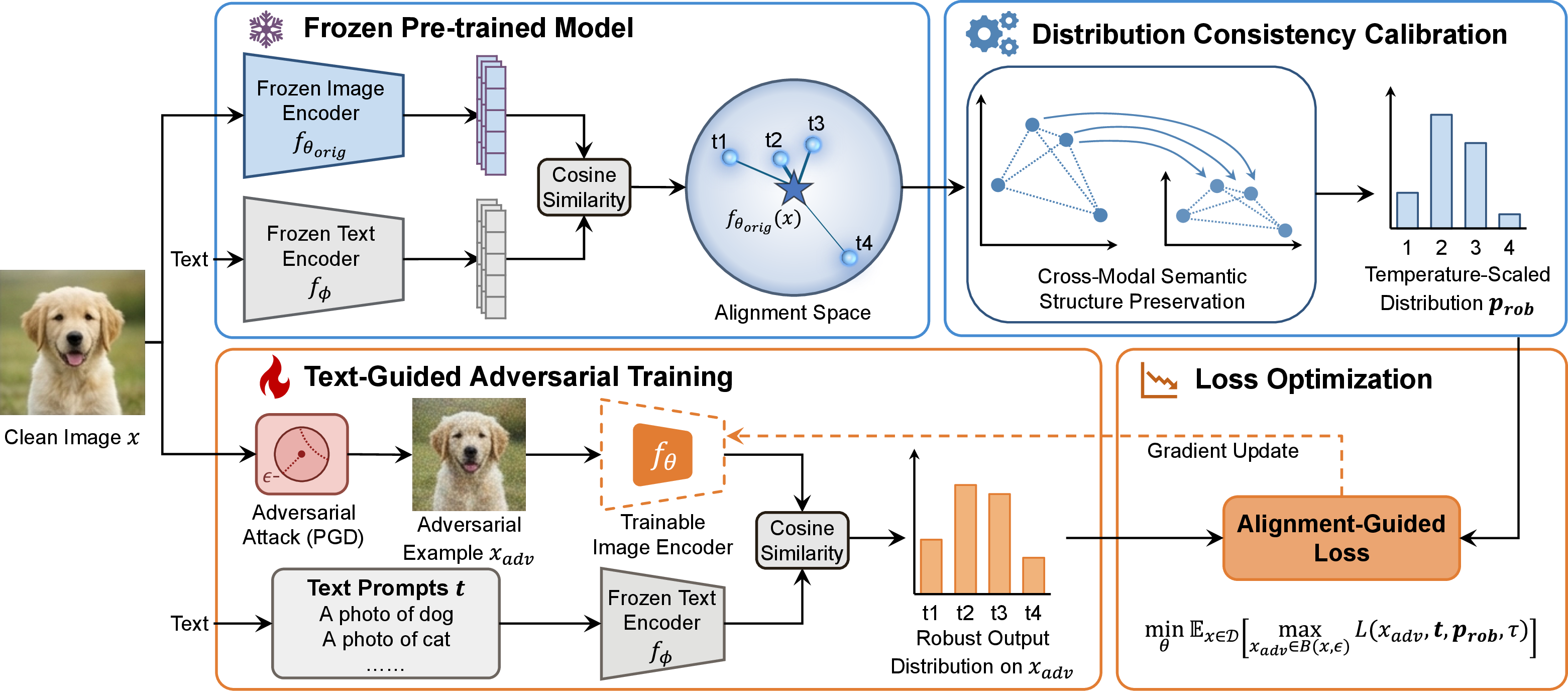
Figure 1: The AGFT pipeline utilizes the pre-trained model's probabilistic outputs to guide adversarial fine-tuning and employs temperature calibration to mitigate distributional discrepancies while preserving cross-modal similarity.
To further prevent structural drift due to robust optimization, AGFT introduces calibration via temperature scaling: the output distribution of the pre-trained model is softened with a temperature scaling factor before being used as the training target. The result is improved preservation of the cross-modal similarity topology in the embedding space and reduced overconfidence in the robust model’s predictions.
Experimental Results
The effectiveness of AGFT is verified with comprehensive experiments on CLIP backbones using the ViT-B/32 encoder, across 15 zero-shot benchmarks spanning generic, fine-grained, scene, texture, and domain-specialized image classification tasks. Models are adversarially fine-tuned on ImageNet and tested under diverse white-box attack protocols, including PGD-20, C&W, and AutoAttack, as well as transferred to out-of-distribution and unseen attack scenarios.
AGFT consistently outperforms strong baselines (TeCoA, PMG-AFT, TGA-ZSR, GLADIATOR) in both clean and robust accuracy, with particularly strong gains in zero-shot adversarial robustness. On average, AGFT yields a 3.1% gain in robust accuracy and a 1.0% gain in clean accuracy over the strongest prior method. Importantly, it maintains semantic structure, as shown by a much higher overlap in top-5 predictions with the original model under both clean and adversarial images.
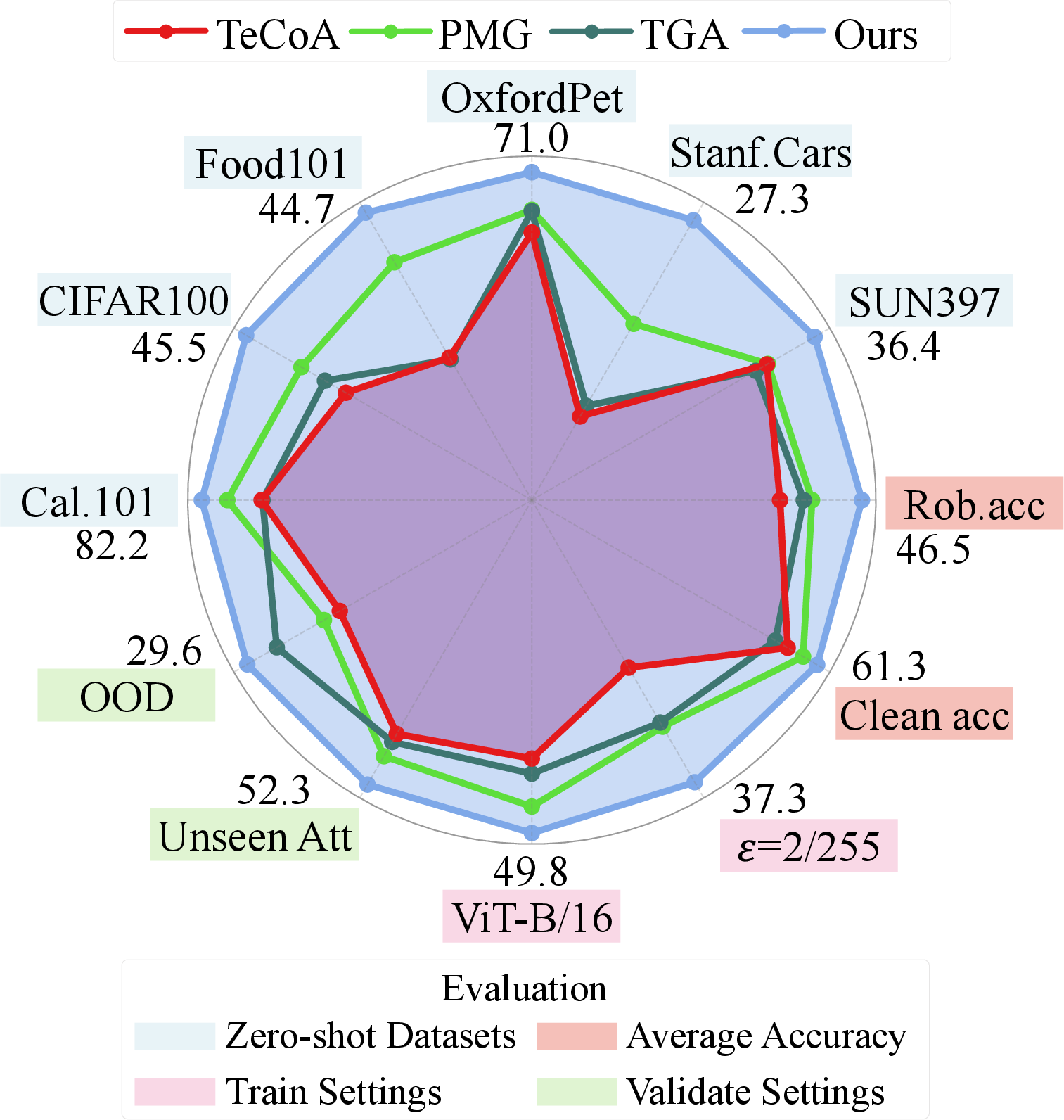
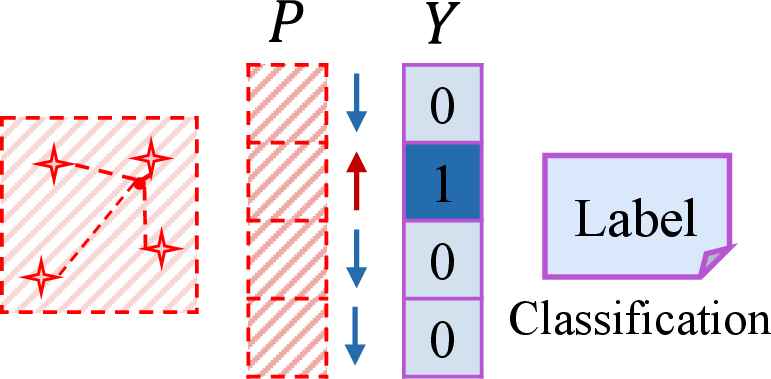
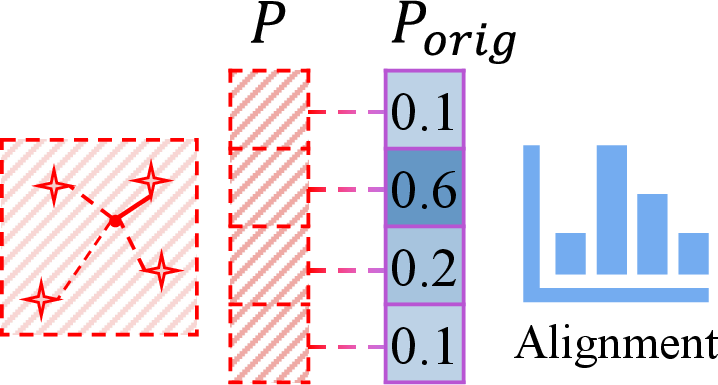
Figure 2: AGFT yields superior robust accuracy compared to conventional classification-guided methods by leveraging alignment-guided supervision and preserving cross-modal structure.
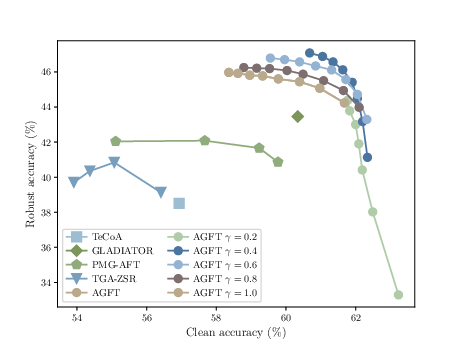
Figure 3: AGFT provides a favorable robustness-accuracy Pareto frontier, displaying flexible and superior trade-offs by tuning hyperparameters relative to baselines.
Ablations show the necessity of temperature scaling: too little (low γ) leads to over-smoothing and overly soft targets, reducing robustness, while an intermediate value optimally balances semantic structure preservation with robust feature learning.
The computational overhead of AGFT is only marginally higher than direct adversarial fine-tuning (requiring one additional forward pass per batch) and notably lower than multi-branch-attention methods.
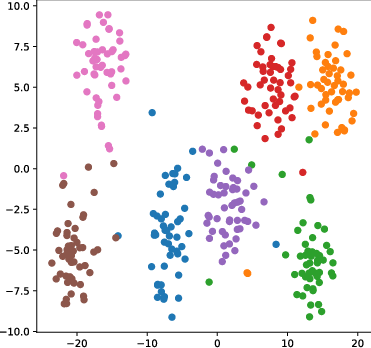
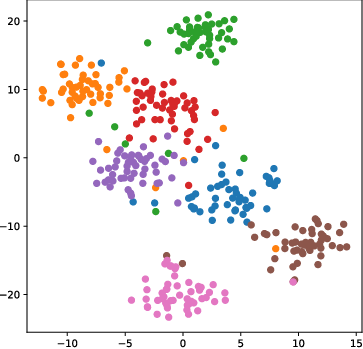
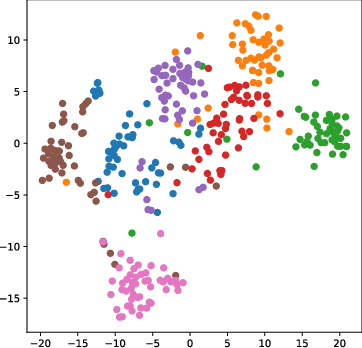
Figure 4: t-SNE visualizations demonstrate that AGFT maintains coherent, aligned clusters in the embedding space under adversarial attack, whereas classification-guided fine-tuning leads to pronounced cluster collapse.
Implications and Discussion
AGFT’s utilization of probabilistic alignment and calibration underscores the importance of preserving intrinsic cross-modal structure during robust optimization in foundation models. By eschewing hard labels, AGFT prevents the logit collapse and semantic distortion typical of robust finetuning, enabling robust generalization and zero-shot transfer in adversarial contexts.
Practically, the approach is model-agnostic and demonstrates strong gains across both transformer-based and convolutional VLM architectures, as well as across a range of attack strengths, unseen attacks, and out-of-distribution scenarios.
Theoretically, AGFT illustrates that maintaining the pre-trained semantic geometry is critical for effective zero-shot transfer under threat, suggesting future extensions to other multi-modal paradigms, fine-grained downstream tasks, and more complex adversarial threat models (e.g., text-image joint attacks).
Conclusion
AGFT presents an effective paradigm for robust adaptation of vision-LLMs, combining adversarial fine-tuning with distributionally calibrated, soft-alignment supervision. This strategy yields marked improvements in zero-shot adversarial robustness, without sacrificing clean generalization or incurring significant computational cost. The methodology provides both a practical tool for robust multimodal systems deployment and a theoretical foundation for future explorations into adversarially robust representation learning.