- The paper introduces a two-stage self-supervised framework combining masked reconstruction and contrastive learning to boost radio astronomy representation transfer.
- The model employs ROI-anchored view generation and domain-aware augmentations to handle data heterogeneity from multiple radio surveys.
- Empirical results demonstrate up to a +14.6% increase in Macro-F1 scores on benchmarks, highlighting its effectiveness across diverse evaluation settings.
STRADAViT: Self-Supervised Foundation Models for Radio Astronomy Representation Learning
Introduction and Scientific Context
Radio astronomy is undergoing a dramatic increase in data volume and complexity, driven by facilities such as MeerKAT, ASKAP, LOFAR, and the SKA. The emergence of large, resolved data sets presents significant challenges in robust, transferable morphological analysis due to instrumental heterogeneity, label scarcity, and systematic variations in imaging pipelines. Existing supervised and classic self-supervised methods suffer from brittle cross-survey transfer and lack principled, domain-adapted image representation.
STRADAViT ("Self-supervised Transformers for Radio Astronomy Discovery Algorithms with Vision Transformers") addresses these limitations by introducing an end-to-end framework for foundational radio astronomy encoders using self-supervised continued pretraining. The design is grounded in ViT-MAE architecture, radio-aware augmentation pipelines, and a flexible two-stage pretraining curriculum encompassing masked image modeling (MIM) and contrastive learning. The focus is on transferability and domain adaptation, validated against standard radio morphological benchmarks using both linear probing and end-to-end fine-tuning.
Architecture and Training Pipeline
STRADAViT is constructed around several critical design choices:
- Heterogeneous, mixed-survey pretraining corpus: The self-supervised data comprises $590,654$ radio continuum cutouts (512×512) from MeerKAT MGCLS DR1, ASKAP, LOFAR/LoTSS, and SKA SDC1 simulations. Preprocessing enforces standardized normalization (per-image ZScale stretch), rigorous filtering, and uniform three-channel input construction for ViT compatibility.
- Domain-aware, online view generation: Instead of random crops, views are generated on-the-fly using ROI-anchored strategies tailored to sparse, structured radio fields—preserving semantically salient morphology for both masked reconstruction and contrastive branches.
- Backbone and branch protocol: The backbone is a ViT-MAE (ViT-B/16) with optional register tokens. Downstream, the pipeline supports (a) masked reconstruction-only, (b) contrastive-only, or (c) two-stage reconstruction-to-contrastive pretraining scenarios. For contrastive branches, strong and mild augmentation regimes are systematically explored.
- Loss and objective variants: Masked reconstruction leverages baseline ViT-MAE MSE as well as L1 and brightness-weighted L1 regularizations. Contrastive learning is configured with InfoNCE, Soft-HCL, and hard-negative HCL losses, enabling nuanced control over negative mining in background-dominated radio data.
- Extensible, reproducible evaluation: Downstream evaluation is performed over MiraBest (binary FR~I/II), LoTSS DR2 (multi-class), and Radio Galaxy Zoo DR1 datasets (component/peak morphologies), with exhaustive three-fold stratified cross-validation for both linear probing and full fine-tuning.

Figure 1: Masked-reconstruction views sampled from standardized parent radio cutouts, showcasing ROI-aware, morphology-preserving augmentation.

Figure 2: Contrastive-branch multi-view augmentations with strong and mild radio-astronomy-preserving transforms anchored to object-centric ROIs.

Figure 3: Typical standardized cutouts from each evaluation dataset, illustrating the pipeline's uniform preprocessing and the visual diversity of benchmark classes.
Empirical Results and Analysis
Baseline Comparisons
DINOv2 and ViT-MAE, when used off-the-shelf, are not uniformly competitive across radio morphology benchmarks. DINOv2-Base achieves a Macro-F1 of $0.717$ (MiraBest), $0.569$ (LoTSS DR2), and $0.661$ (RGZ DR1) under linear probing. However, its fine-tuned performance is more volatile, with ViT-MAE matching or surpassing DINOv2 in certain regimes (notably on MiraBest).
Reconstruction-Only and Contrastive-Only Pretraining
Masked reconstruction alone (ViT-MAE default or L1-regularized variants) delivers limited transfer improvement over the pretraining checkpoint and often underperforms contrastive alternatives. In contrast, contrastive-only pretraining with either soft-hard negative (Soft-HCL) or HCL loss realizes substantial improvements, especially in linear probe regimes (∼0.71–$0.73$ Macro-F1, up from $0.64$–$0.66$ for ViT-MAE). The effectiveness of contrastive objectives is robust to choice of augmentation strength and register token settings.
Two-Stage Continued Pretraining
The strongest configuration is the two-stage pipeline: masked reconstruction followed by contrastive learning. This protocol secures the highest Macro-F1 scores on the majority of evaluation tasks—most notably an increase of +14.6 percentage points in macro-F1 on RGZ DR1 (linear probe) relative to vanilla ViT-MAE. Gains are distributed across all benchmark datasets, especially under the frozen-feature setting, demonstrating genuine improvements in the linear separability of learned representations.
Importantly, these gains are not universal across all tasks and classes, highlighting the continued challenge posed by multi-modal, label-imbalanced data such as LoTSS DR2, where certain fine-tuning scenarios are still best served by specific DINOv2 off-the-shelf baselines.
Foundation Model Comparison and Ablation
Ablation studies with DINOv2-initialized backbones confirm the transferability of STRADAViT’s radio domain adaptation protocol; the same adaptation pipeline can be ported to non-MAE ViTs, yielding consistent, albeit selective, improvements. Nevertheless, ViT-MAE-based two-stage checkpoints are preferable due to lower parameter/token counts and comparable or superior downstream performance in frozen and fine-tuned settings.
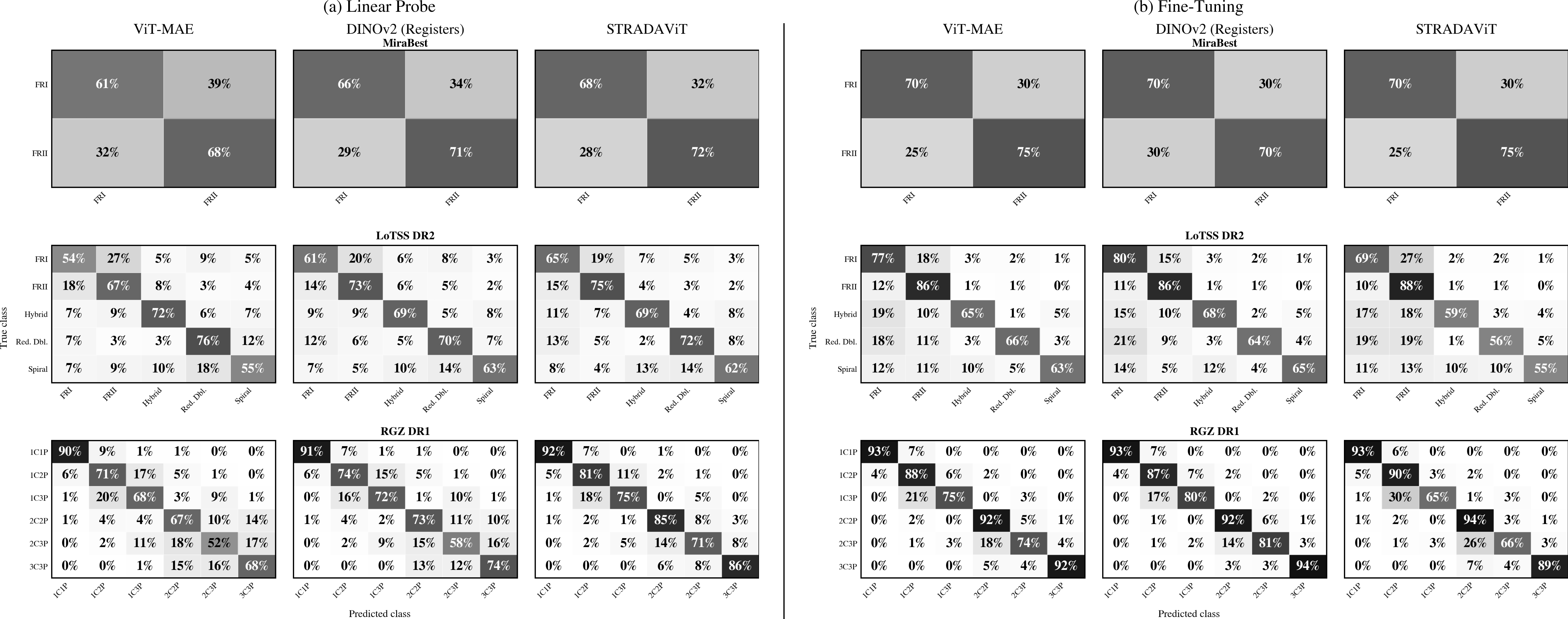
Figure 4: Aggregate recall-form confusion matrices for STRADAViT vs. ViT-MAE and DINOv2 baselines, under both linear probing and full fine-tuning, illustrating classwise effects and distributed gains across label spaces.
Practical and Theoretical Implications
STRADAViT demonstrates that naive transfer of general-purpose vision backbones (even modern ones such as DINOv2 or ViT-MAE) is suboptimal in radio astronomy scenarios. The domain’s unique image statistics, label stratifications, and morphological priors necessitate radio astronomy-aware view generation and carefully balanced self-supervised objectives to achieve robust, generalizable encoders.
Most transfer gains derive from contrastive learning, with reconstruction primarily serving as a regularizing warm start. ROI-anchored view sampling is critical for disambiguating sparse field structure and drives much of the transfer improvement. The method is computationally practical, with the ViT-MAE-derived STRADAViT checkpoint offering strong performance at lower downstream cost compared to DINOv2-based alternatives.
In a broader context, the results corroborate a growing body of domain-specialized self-supervised vision adaptation studies. STRADAViT’s effectiveness on radio data—in parallel with analogous trends in medical imaging [Ma2024MedSAM, Tang2026HiEndMAE, Wang2025NaMAMamba]—suggests that foundational models in scientific domains must integrate data-generative modeling with physically and visually motivated inductive biases.
Future Directions
There is significant scope for further refinement:
- Stronger pretext tasks such as DINO-style teacher–student objectives and multi-scale ROI policies may improve classwise robustness and extend transfer gains to extended emission morphologies prevalent in LoTSS DR2.
- Dynamic, survey-aware augmentation policies can target improved harmonization and mitigate overfitting to “RGZ-like” compact source distributions.
- Explicit out-of-domain and cross-survey transfer evaluation is warranted to establish true foundation model status and resolve current class-dependent limitations.
- Integrative vision–LLMs and multimodal pipelines leveraging radio annotation corpora offer a promising path to cross-modal reasoning and discovery.
Conclusion
STRADAViT establishes a rigorously benchmarked, domain-adapted protocol for foundational ViT-based encoders in radio astronomy, with robust and reproducible improvements in representation transferability. Contrastive self-supervised adaptation, coupled with radio-aware augmentation and staging, is essential for state-of-the-art performance. The methodology provides a blueprint for foundational model development in other scientific imaging domains and underscores the limitations of direct transfer from generic vision models. The STRADAViT release is positioned as a practical, resource-efficient alternative to off-the-shelf ViTs for radio astronomy and, by extension, for data-driven discovery in large-scale astrophysical imaging workflows.
(2603.29660)