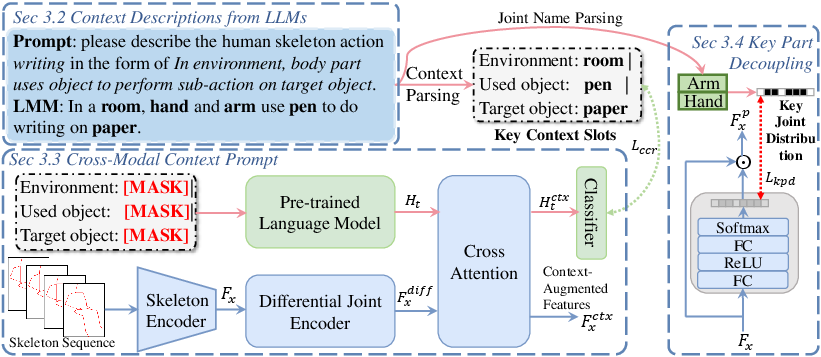
- The paper introduces a novel context-aware framework that leverages language-driven cues to bridge the semantic gap in zero-shot skeleton-based action recognition.
- It integrates a cross-modal context prompt module and a key-part decoupling module to enhance fine-grained motion discrimination and robust action understanding.
- Experimental results on NTU and PKU benchmarks show significant gains, with ZSL accuracies up to 89.6% and balanced performance under GZSL protocols.
SkeletonContext: Context-Aware Zero-Shot Skeleton-Based Action Recognition
Motivation and Novelty
The SkeletonContext framework addresses the persistent semantic gap in zero-shot skeleton-based action recognition (ZSSAR), where traditional methods directly align skeletal features with textual descriptions, but fail to account for contextual cues required to distinguish visually similar actions. ZSSAR imposes the challenge of generalizing from source (seen) categories to target (unseen) categories relying on semantic descriptions. The absence of contextual information—such as objects and environments in interaction—hampers discriminability especially in skeleton representations that encode only human joint coordinates.
SkeletonContext introduces a new paradigm, enriching skeletal motion features with language-driven contextual semantics by leveraging pretrained LLMs. This design reconstructs masked context prompts (objects, environment, target) and injects them directly into the skeleton encoding pipeline, fundamentally improving cross-modal alignment. Additionally, the Key-Part Decoupling (KPD) module ensures robust action understanding for context-independent actions by explicitly disentangling motion-relevant joint features.
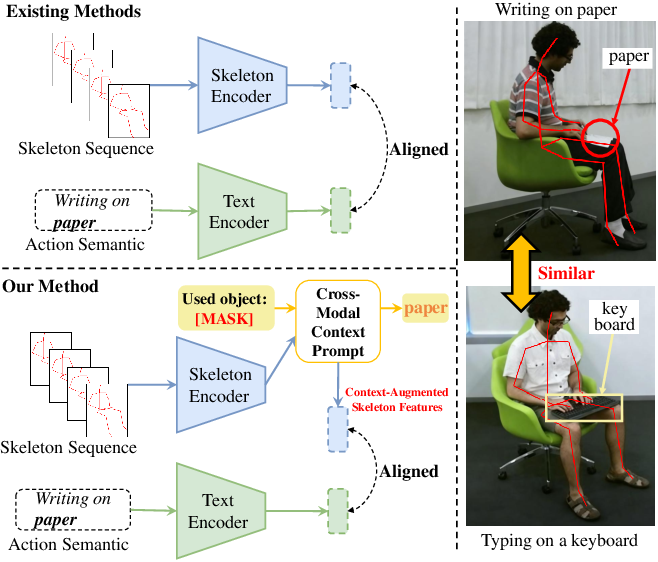
Figure 1: Comparison between conventional ZSSAR approaches and SkeletonContext, illustrating context injection into skeleton representations for improved discrimination of similar actions.
Framework Overview
SkeletonContext is instantiated with two core modules:
Context Description Generation
Context descriptions are structured via prompt engineering for LLMs to obtain compositional semantics associated with each action, e.g., "In office, hand uses pen to write on paper." Multiple context descriptions are generated for each action to expand intra-class diversity and facilitate contextual knowledge transfer between categories sharing similar semantics.
The CCPM reconstructs context prompts at progressively harder masking ratios using the Progressive Partial Masking (PPM) curriculum, enabling stable optimization and gradual semantic induction.
Differential Joint Encoding and Semantic Grounding
Skeleton representations are enriched through the Differential Joint Encoder (DJE), explicitly modeling fine-grained spatial dependencies. Inter-joint differences are leveraged to infer likely context, further refined through cross-attention mechanisms with language tokens. The semantic context grounding objective (context reconstruction loss, Lccr) enforces plausible context generation guided jointly by skeleton motion dynamics and LLM priors.
Key-Part Decoupling: Motion-Critical Focus
KPD predicts joint-importance maps using action-specific language priors, calibrated via a key-part decoupling loss (Lkpd). This module robustly highlights informative body regions for each action, generalizing to unseen classes sharing structural motion patterns.
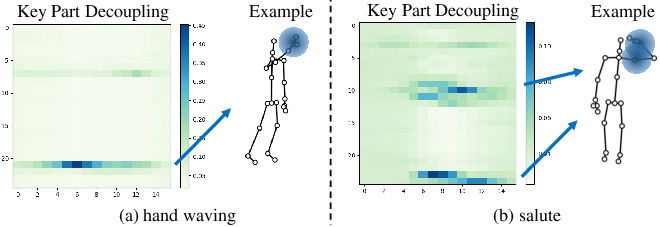
Figure 3: KPD visualization with attention focused on motion-critical joints for each action, aligned to semantic priors.
Experimental Results
SkeletonContext was evaluated on NTU-RGB+D 60/120 and PKU-MMD benchmarks under both ZSL and GZSL protocols. The framework consistently achieves state-of-the-art performance with strong harmonic mean (H) scores indicative of balanced generalization between seen and unseen classes. Notably, SkeletonContext demonstrates robust transfer under random unseen-class splits and outperforms prior art in fine-grained action discrimination across ambiguous clusters.
Key numerical results:
- NTU-60 (55/5 split): ZSL accuracy of 89.6%, GZSL harmonic mean 77.1%
- NTU-120 (96/24 split): ZSL accuracy of 60.1%, GZSL harmonic mean 56.1%
- PKU-MMD (46/5 splits): ZSL 73.5%, GZSL harmonic mean 71.4%
Ablation studies confirm cumulative benefits of DJE, SCG, PPM, and KPD, with each module contributing to improved context induction and motion discrimination. Removal of context reconstruction loss or key-part decoupling loss results in statistically significant degeneration (∼2-3% drop).
Fine-Grained Semantic Reasoning and Qualitative Analysis
SkeletonContext's context reconstruction is validated qualitatively: the model reliably distinguishes visually similar actions such as "typing" and "writing" by correctly inferring contextual objects (keyboard/tablet vs. pen/paper). Similarly, ambiguous clusters e.g., "putting on glasses" vs. "putting on a hat" are resolved via accurate context prediction, demonstrating robust semantic grounding from skeleton-only input.
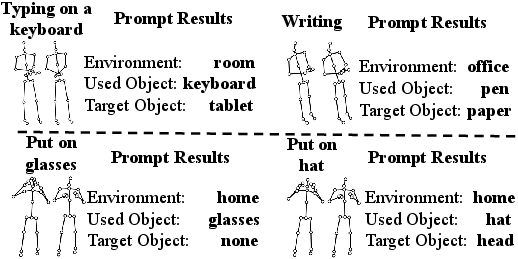
Figure 4: SkeletonContext qualitative results showing inferred contextual objects for visually ambiguous actions, guaranteeing fine-grained discrimination.
Implications and Future Directions
SkeletonContext validates that language-driven context injection substantially bridges the semantic gap in skeleton-based action recognition, enabling robust cross-modal generalization and fine-grained action discrimination. Practically, this advances privacy-preserving action recognition for applications including intelligent surveillance, healthcare analytics, and HCI with minimal dependency on appearance cues. Theoretically, SkeletonContext offers a unified approach for multimodal grounding in abstract visual domains, laying foundations for extending to few-shot learning, video reasoning, and embodied AI.
Further research can investigate:
- Extension to temporally complex or continuous action streams.
- Integration with video-level or multi-modal cues for enhanced context induction.
- Unsupervised or semi-supervised adaptation to real-world settings.
Conclusion
SkeletonContext introduces a principled, context-aware framework for ZSSAR, coupling language-driven contextual reconstruction with motion-centric key-part decoupling. Extensive quantitative and qualitative evidence substantiates its superiority in balancing performance across seen and unseen categories as well as distinguishing visually similar actions. The approach demonstrates practical relevance and theoretical potential for the broader AI community, especially in multimodal understanding and semantic grounding tasks.