- The paper introduces randomized approximation schemes that achieve near-exact (1+ϵ) ED and (1-ϵ) LCS values in quasi-subquadratic time.
- It employs a hierarchical random sampling and curvature regularization method to significantly reduce dynamic programming complexity.
- The work establishes a clear separation between approximation and exact computation, highlighting randomization as key for efficient LCS algorithms.
Approximation Schemes for Edit Distance and LCS in Quasi-Strongly Subquadratic Time
Introduction and Context
The edit distance (ED) and longest common subsequence (LCS) problems are foundational in both theory and practice, being central to applications in computational biology, coding theory, and machine learning. Classical algorithms for both ED and LCS are based on dynamic programming with O(n2) time complexity, and strong conditional lower bounds under SETH (Strong Exponential Time Hypothesis) preclude truly subquadratic exact algorithms. Previous advances in subquadratic approximation have been limited to constant-factor algorithms, e.g., factor-3 for ED, or even significantly worse for LCS in the worst case.
This paper presents randomized approximation schemes for both ED and LCS on two strings of total length n, achieving, for any constant ϵ>0, (1+ϵ)-approximation for ED and (1−ϵ)-approximation for LCS. The algorithms run in time n2/2logΩ(1)n, thus giving a quasi-polynomial factor improvement over the classical O(n2) dynamic programming baseline. The result strictly separates the complexity of near-exact approximation from that of exact computation for both problems under plausible fine-grained complexity conjectures.
Furthermore, for LCS, these randomized schemes achieve a multiplicative approximation-time tradeoff that is known to be out of reach for deterministic algorithms unless major circuit complexity lower bounds are broken. Thus, the work establishes a fine-grained complexity separation between randomized and deterministic approximation for LCS.
Technical Contributions and Algorithm Overview
The core technical innovation is the hierarchical random sampling and regularization approach for the path-finding view of ED and LCS. Both problems can be viewed as path problems on a 2D grid: shortest path for ED and longest path for LCS, with dynamic programming corresponding to Bellman–Held–Karp traversal. The algorithm proceeds as follows:
- Sparsified Grid Formulation: Instead of solving on the dense n×n grid, the authors construct a multi-scale sparsification using recursive interval partitioning and random sub-sampling at each scale. This reduces the number of subproblems considered and thus the overall runtime (Figure 1 illustrates the sub-sampling scheme).
- Curvature Regularization: The notion of 'tree total deviation' (TTD) is introduced as a hierarchical measurement of path deviation from regularity (i.e., from a straight line on the grid). Bounding the curvature of optimal paths at various scales allows the rounding of the path to a small, regular representative set (see Figure 2 for the 45°-rotated, regularized coordinate system).
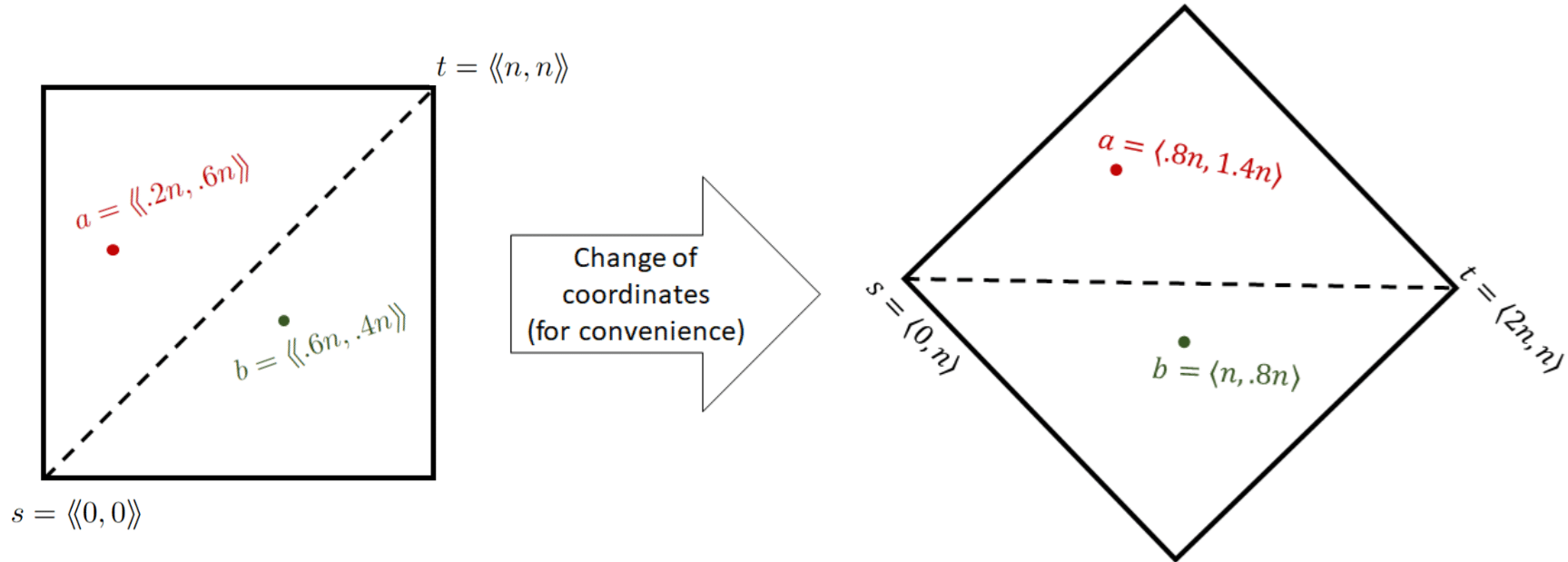
Figure 2: Hierarchically regularized path representation in the rotated coordinate system, enabling efficient divide-and-conquer.
- Recursive Sampling and Rounding: For each randomly chosen "active" scale, only a random subset of subproblems is kept (via subset-sampling in recursive DP), aggressively pruning the search space. On active scales, candidate paths are forced to be close to a straight line between endpoints, inhibiting overfitting to random samples.
- Error Analysis via Total Deviation: Key probabilistic lemmas show that for an optimal or near-optimal path, the cumulative error from rounding to regular paths at sampled scales is sub-linear in n, and the multiplicative error is made arbitrarily small by tuning parameters. When the path weight is low, exact or classical constant-factor approximate algorithms are applied instead.
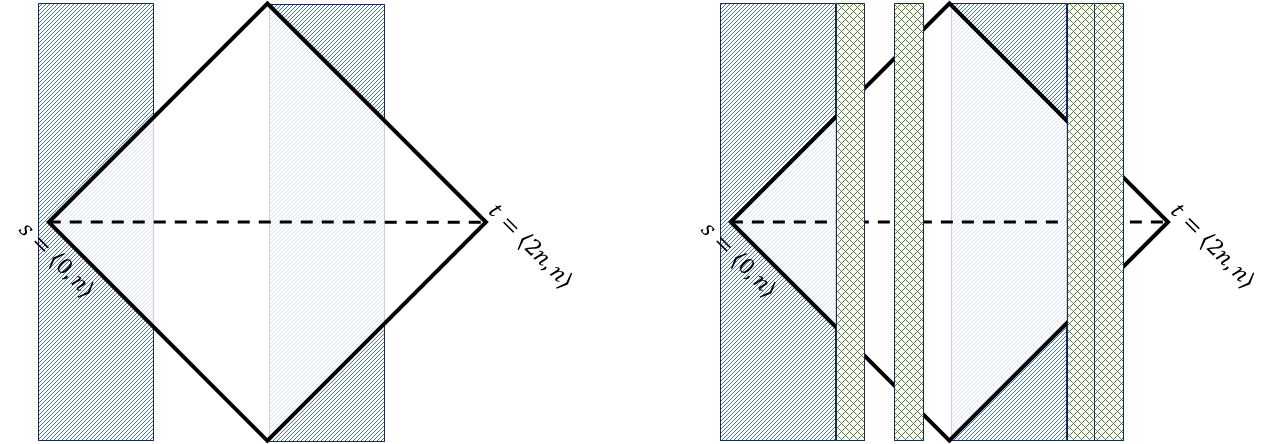
Figure 1: Visualization of recursive sub-sampling in multi-scale grid decomposition, demonstrating the fraction of subproblems preserved at each level.
- Multiplicative Schemes for ED and LCS: For multiplicative (1±ϵ)-approximation, additional care is given to handle variance in subpath contributions and to rule out cases where a small number of subpaths could dominate the optimum. For LCS, a scaling variant of tree total deviation is used to control error where vertical movement (relevant to LCS path cost) can far exceed horizontal.
Analysis and Theoretical Implications
This work achieves several significant outcomes:
- Quasi-Strongly Subquadratic Algorithms: For both ED and LCS, the running time is reduced from n0 to n1 for arbitrarily fine approximation, representing a quasi-polynomial improvement. No such improvement is believed attainable for exact ED without refuting SETH.
- Separation of Approximate and Exact Complexity: Since even small logarithmic improvements for exact ED or LCS would collapse major complexity class separations, this result sharply delineates approximation as fundamentally easier than exact computation.
- Randomization is Essential for LCS: Under black-box derandomization barriers, deterministic algorithms attaining similar tradeoffs for LCS would yield major circuit lower bounds, currently out of reach. Thus, these randomized algorithms are strictly more powerful, evidence that randomization plays a fundamental role in fine-grained approximate sequence alignment.
- Algorithmic Techniques of Broader Utility: The tools developed, particularly hierarchical deviation and probabilistic sample selection in dynamic programming recursion, could inspire advances in related problems in sequence alignment, dynamic programming on graphs, and metric embedding.
Numerical Results and Quantitative Claims
- Approximation Guarantee: For any n2, the randomized algorithms achieve n3-approximation for ED and n4-approximation for LCS with high probability.
- Runtime: The algorithms run in n5 time for inputs of length n6. This is several orders of magnitude faster than quadratic time for practical n7, and is the first result to achieve this for near-tight multiplicative approximations.
- Complexity Barrier: The authors explicitly demonstrate that no prior algorithm achieves better than a factor-3 approximation for ED or closely subpolynomial for LCS in similar time, and that improving beyond these bounds for exact algorithms is conjectured to be impossible without major breakthroughs.
Implications and Future Directions
The demonstrated separation between near-exact approximation and exact computation in ED and LCS provides a new perspective on sequence analysis algorithms under fine-grained complexity. The multi-scale sub-sampling and deviation control techniques, by circumventing the information-theoretic bottlenecks of dynamic programming, could lead to progress in other problems where the best-known exact algorithms face rigid quadratic or worse barriers.
The methods may have ramifications in related domains such as tree edit distance, dynamic time warping, and geometric measures (e.g., Fréchet distance), where modest improvements over quadratic time are highly significant. Open questions include derandomizing the schemes for broader classes of problems, tightening the dependency of the exponent's denominator on n8, and practical algorithm engineering for bioinformatics-scale inputs.
Future research may further clarify the role of randomization for approximation algorithms in P—potentially leading to a deeper understanding of the computational landscape between P and NP, and between randomized and deterministic computation in fine-grained complexity.
Conclusion
This paper makes a strong and technically novel contribution to the study of fine-grained algorithms for fundamental string problems by proving that n9-approximations for edit distance and LCS can be achieved in quasi-strongly subquadratic time, strictly separating their approximability from exact computability under standard conjectures. The hierarchical deviation framework and randomized sub-sampling paradigm open new directions for subquadratic approximation algorithms and complexity separations in sequence analysis and beyond.