- The paper introduces DACT, a novel framework that mitigates identifier drift by combining drift-aware fine-tuning with a hierarchical code reassignment strategy.
- The paper utilizes a two-stage pipeline with a Collaborative Drift Identification Module to distinguish drifting items from stationary ones, ensuring stable token embeddings.
- The paper demonstrates state-of-the-art performance across multiple datasets with improved recall and ranking metrics while reducing computational retraining costs.
Drift-Aware Continual Tokenization for Generative Recommendation
Introduction and Motivation
Tokenization has become a crucial component in generative recommender architectures, particularly those employing sequence modeling paradigms for user-item interaction data. The integration of collaborative signals into the tokenization layer—ensuring that items with similar user behavior patterns receive similar token sequences—has been empirically proven to enhance downstream generative recommender model (GRM) performance. However, real-world recommenders operate in a nonstationary environment where continual introduction of new items and evolving interaction patterns induce both identifier drift and collaborative signal drift, compromising static token-vocabulary approaches. Full retraining is computationally prohibitive, and naive incremental fine-tuning can cause catastrophic token reassignments, thus breaking the token-embedding alignment critical for the efficacy of GRMs.
DACT Framework Overview
DACT (Drift-Aware Continual Tokenization) directly addresses the stability–plasticity dilemma for collaborative tokenizers by introducing a two-stage pipeline: (1) drift-aware tokenizer fine-tuning, and (2) differentiated hierarchical code reassignment. The central innovation is the Collaborative Drift Identification Module (CDIM), which is jointly trained with the tokenizer to learn item-level drift confidence scores. These scores govern a differentiated optimization strategy that updates the codes for ‘drifting’ items, while stationary items are constrained by stability regularizers. The code reassignment leverages a relaxed-to-strict strategy across hierarchical codebook layers to minimize disruptive changes in item identifiers.
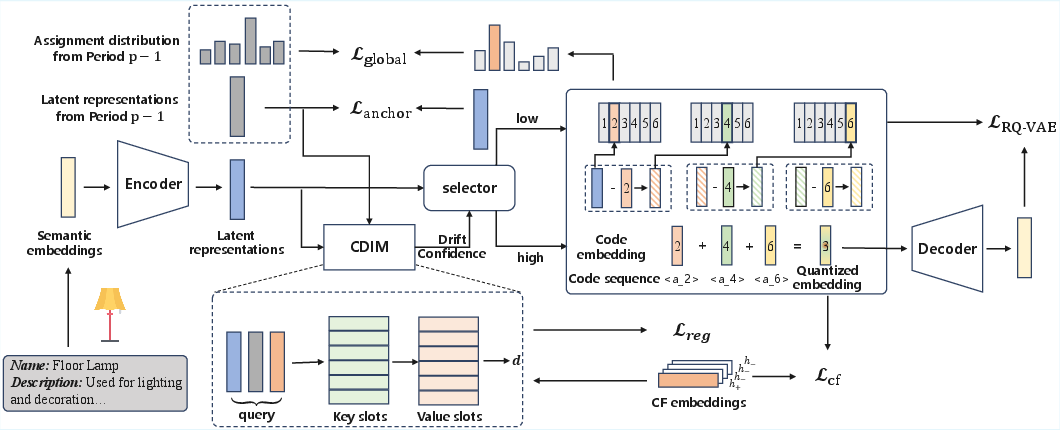
Figure 1: DACT utilizes CDIM for item-level drift identification, enabling differentiated training strategies and applying a global code-assignment constraint for stability.
Methodological Details
Drift Identification and Differentiated Update
CDIM computes drift confidence per item by comparing historical and current latent representations, as well as up-to-date collaborative CF embeddings, leveraging both change signals and pattern memory. Top-K drift confidence items are adaptively updated (plasticity), while stationary items are regularized to anchor their token representations (stability), thus addressing the core stability–plasticity trade-off. The process explicitly supports gradient-based end-to-end training, incorporating a straight-through estimator for subset selection.
Hierarchical Code Reassignment
Code reassignment is performed in a layer-dependent way: the first codebook layer always undergoes reassignment based on current latent representations to reflect substantial semantic drift; reassignment in deeper layers is triggered only upon first-layer changes. This design operationalizes fine-grained control over identifier churn, reducing unnecessary code switches that would otherwise degrade the GRM’s token-embedding alignment. A global KL-divergence stability regularizer is imposed on token assignment distributions to further constrain unnecessary distributional shifts.
Empirical Evaluation
Dataset and Protocol
Experiments were conducted on three partitioned Amazon datasets (Beauty, Tools, Toys), with interaction streams divided into periods for continual training. Two backbone models were considered: TIGER (T5 encoder-decoder GRM) and LCRec (Qwen2.5-1.5B-Instruct with LoRA-based continual learning).
Baseline Comparisons
Benchmarks encompass variants with frozen/fine-tuned/retrained tokenizers, GRMs, as well as strong continual learning baselines such as Reformer, LSAT, and PESO.
Main Results
On both TIGER and LCRec, DACT achieves superior or state-of-the-art results across all evaluation periods and datasets. Strong performance is observed particularly on recall- and ranking-style metrics such as HR@10 and NDCG@10, indicating DACT’s ability to capture evolving interaction semantics without degrading accumulator performance over time.
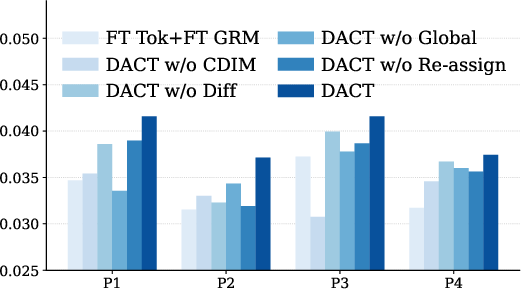
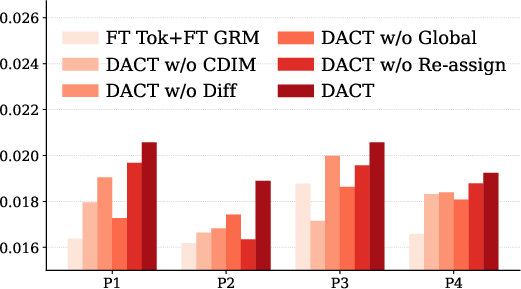
Figure 2: DACT consistently outperforms or matches the best baselines on HR@10 across periods and datasets on TIGER.
DACT’s differentiated fine-tuning approach avoids the severe performance degradation observed when naively fine-tuning the tokenizer (which leads to massive identifier churn), and is more robust than both GRM-only fine-tuning and prior incremental token assignment strategies that ignore collaborative drift.
Ablation and Analysis
Removal of CDIM, the differentiated update mechanism, or the global assignment constraint all cause statistically significant drops in performance. DACT maintains lower code change rates compared to naive fine-tuning—particularly in deeper codebook layers—while maintaining or improving adaptation on truly drifting items.
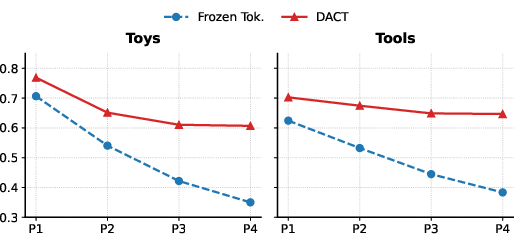
Figure 3: DACT maintains stable average cosine similarity between quantized and CF embeddings over time, indicating effective drift adaptation.
Drift Awareness and Identifier Stability
DACT’s code updates preserve alignment between quantized and collaborative embeddings, offering both drift adaptation for semantically evolving items and identifier stability for stationary items. Visualization of assignment and embedding structures confirms selective reassignment for drifted items, supported by t-SNE projections.
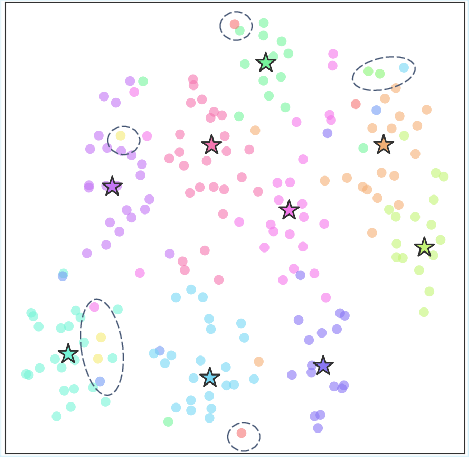
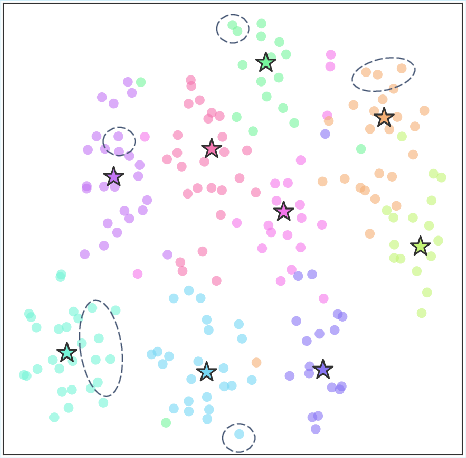
Figure 4: Under a frozen tokenizer, code assignments cannot adapt to semantic drift, resulting in misaligned clusters.
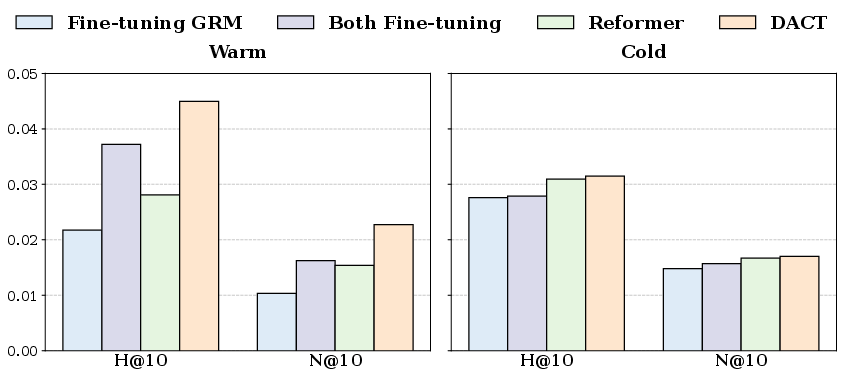
Figure 5: DACT achieves competitive or best performance on both warm (seen) and cold (new) items, unlike baselines that target only one subset.
Hyperparameter Sensitivity and Efficiency
Sensitivity analysis verifies optimal performance for intermediate values of stability and drift adaptation weights. Efficiency benchmarks reveal DACT’s GRM update process is consistently faster than baselines involving full retraining, confirming real-world practicality.

Figure 6: Performance of DACT as a function of key hyperparameters on Tools, illustrating optimal stability-plasticity trade-off values.
Theoretical and Practical Implications
DACT operationalizes drift-awareness in continual tokenization, enabling explicit separation of items that require semantic adaptation from those whose token aliases should remain stable. This provides a formal mechanism for reducing unnecessary identifier churn—a critical factor for maintaining legacy compatibility, embedding reusability, and minimizing the computational cost of downstream GRM fine-tuning. The strategy is extensible to other hierarchical quantization/tokenization architectures and may be generalized to alternative forms of collaborative drift (e.g., user segmentation, temporal context augmentation).
Conclusion
DACT is an effective and computationally efficient continual tokenization strategy for generative recommenders that operate under collaborative drift. By leveraging joint drift identification and differentiated update policies, DACT enables dynamic adaptation to the evolution of both item and interaction landscapes while avoiding the disruptive effects of naive token reassignments. Empirical results across datasets and GRM backbones validate the approach, positioning DACT as a scalable solution for long-life generative recommender deployments. Future work may extend this paradigm to larger-scale corpora and hierarchical or multi-modal collaborative signal integration.