- The paper presents SceneTeract, a hybrid framework that integrates VLM-driven semantic task decomposition with detailed, agent-aware geometric verification in 3D scenes.
- It decomposes high-level activities into atomic actions, mapping them to precise geometric predicates such as reachability, navigability, clearance, and visibility tailored to varied user profiles.
- Results from synthetic residential scenes reveal significant accessibility challenges—especially for wheelchair users—highlighting the need for functional, physical reasoning in embodied AI.
SceneTeract: Agentic Functional Affordances and VLM Grounding in 3D Scenes
Motivation and Problem Statement
The assessment of functional affordances within 3D scenes is essential for embodied AI, robotics simulation, and interactive virtual environments. While generative advances have unlocked visually and semantically rich indoor datasets, functional evaluation lags in both research rigor and tooling. Existing metrics are primarily perceptual or 2D-based, neglecting the physically-grounded constraints that determine whether an embodied agent—a human of a specific profile or a robot—can actually perform intended activities given the geometric characteristics of the scene and its physical limitations. Vision-LLMs (VLMs) now display strong commonsense planning ability, but systematic failures arise when physical and geometric feasibility for specific embodiments are required. This paper presents SceneTeract, a hybrid verification framework addressing the gap between semantic reasoning and agent-aware physical feasibility in interactive 3D scenes (2603.29798).
Framework Overview
SceneTeract operates as a modular verification engine, integrating high-level VLM-driven semantic planning with explicit, low-level agent-aware geometric and physical checks. Given a scene, an agent profile, and an activity, SceneTeract decomposes the target task into atomic actions, each mapped to a formalized sequence of geometric feasibility predicates (e.g., reachability, navigability, clearance, visibility), validated in simulation. The architecture is organized into four modules: Scene Manager, Scene Renderer, VLM Client (Semantic Planner), and Geometric Verifier, which communicate over a triplet of task, agent, and scene inputs.
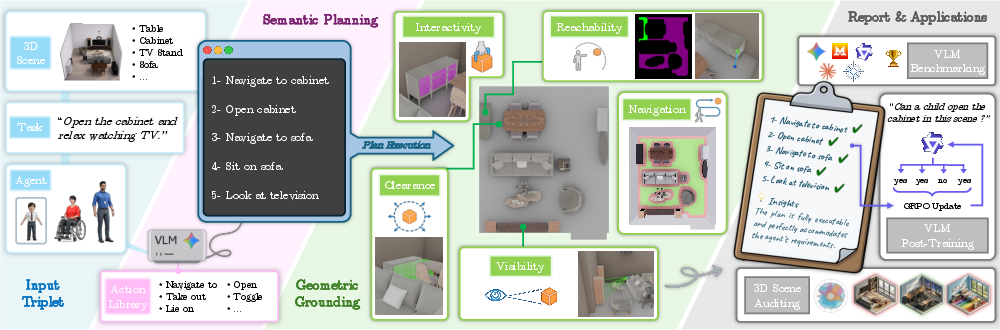
Figure 1: SceneTeract system overview with activity decomposition, agent-conditioned verification, and downstream applications.
The framework supports multiple downstream applications: (1) auditing synthetic 3D environments for agent-dependent accessibility, (2) benchmarking frontier and open-source VLMs on embodied physical reasoning, and (3) providing reward signals for the functional post-training of VLMs.
Agent-Conditional Decomposition and Verification
High-level activities are decomposed by VLMs into closed-vocabulary atomic actions (mobility, contact, handling, perception), each paired with a scene object. Each action is mapped to an ordered checklist of geometric predicates, forming the backbone of the grounding process: is_navigable_to (connectivity on the agent-specific occupancy map), is_reachable (3D proximity under manipulator kinematics), is_interactable (functional part access), has_clearance (volumetric articulation space), and is_visible (line-of-sight considering occlusions).
A principal innovation is the explicit parameterization of the agent profile: body width, reach radius, height, vision parameters, posture, and mobility constraints (e.g., wheeled vs. walking). This enables the framework to make fine-grained, profile-sensitive judgments: e.g., a child, adult, and wheelchair user yield non-trivially distinct affordance maps over the same geometric scene.
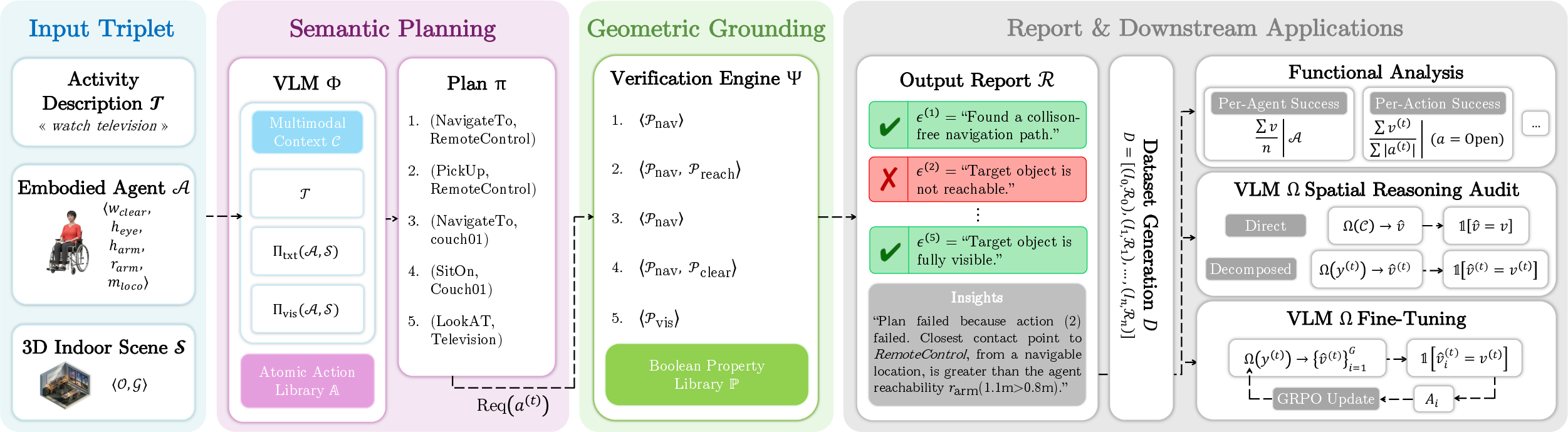
Figure 2: SceneTeract pipeline with task decomposition and property-based geometric verification.
Diagnostic reports produced by SceneTeract detail failure/success at each action and property level, providing interpretable, actionable traces and facilitating systematic analysis of scene deficiencies or model errors.
Large-Scale Functional Auditing of Synthetic Scenes
SceneTeract is deployed on 1,132 residential scenes (3D-FRONT dataset), ∼3,400 scene-task-agent triplets, and three divergent agent profiles: Adult, Child, Wheelchair User. Results establish that visual plausibility does not guarantee functional validity—task-level success rates are modest: 59% (Adult), 66% (Child), and only 42.5% (Wheelchair User). Wheelchair users consistently encounter restrictive navigation, and cluttered or poorly articulated spaces disproportionately hamper clearance, with is_navigable_to and has_clearance as primary failure modes.
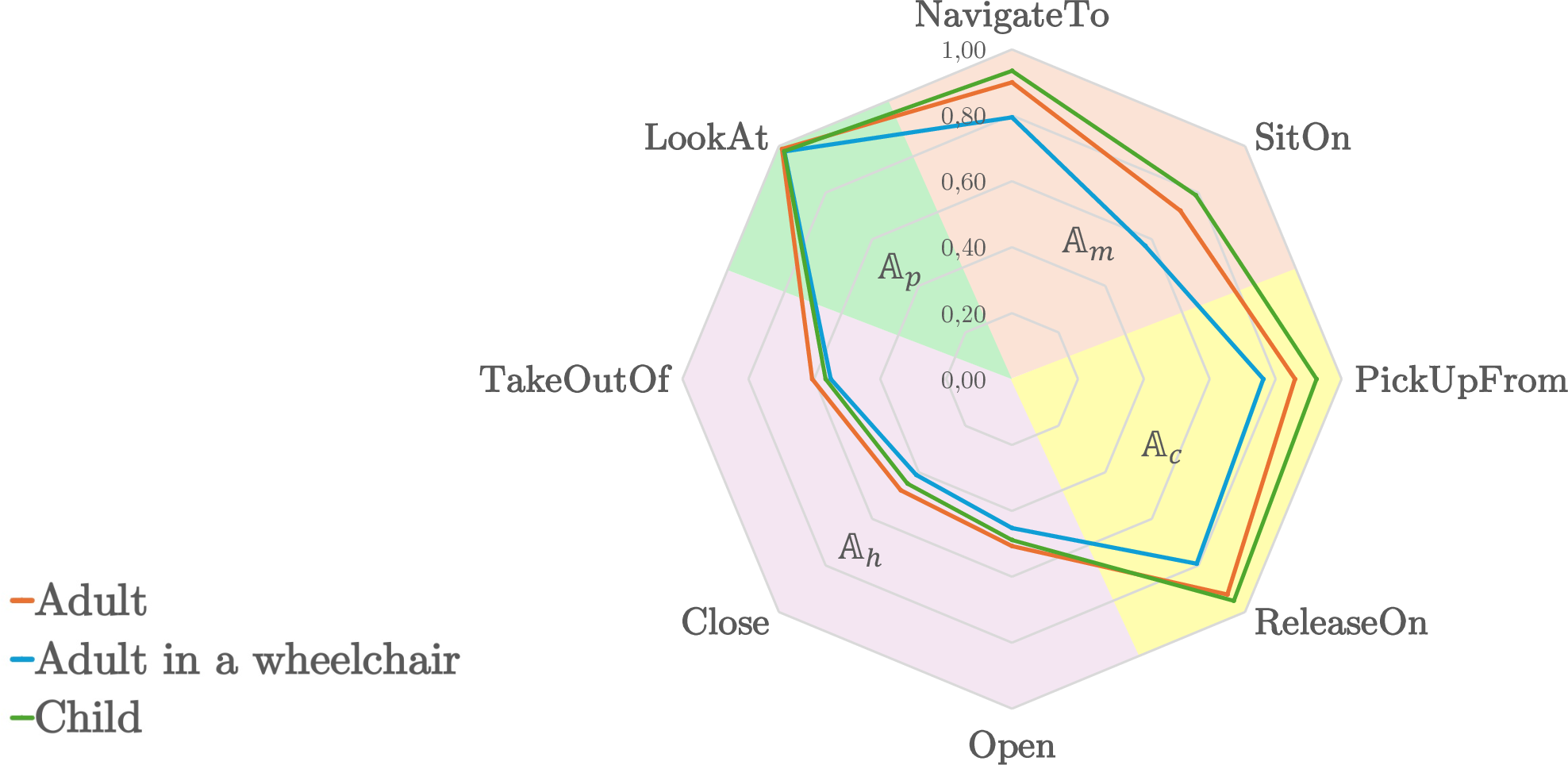
Figure 3: Left—Success rates for tasks and properties by agent type highlight accessibility failure; Right—Spider chart visualizes per-action bottlenecks.
SceneTeract identifies not only global failures but precise geometric causes (e.g., unreachable objects due to occlusion, insufficient manipulation space, disconnected navigation components). These diagnostics offer actionable insight for design and synthesis feedback in scene generation pipelines.
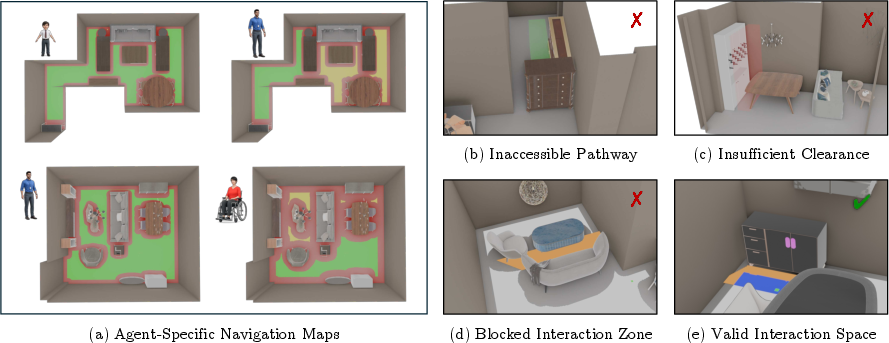
Figure 4: Exemplary detected failure cases: navigation bottlenecks, clearance violations, articulation infeasibility, and reach/connectivity conflicts.
VLM Auditing: Bridging Semantic and Physical Reasoning
State-of-the-art VLMs (Gemini-3-Flash, Claude Sonnet, Qwen3, Gemma3, Ministal3, etc.) are benchmarked using SceneTeract’s fine-grained geometric labels as ground truth at two abstraction levels: holistic task-level and action-level judgments. In holistic mode, all models exhibit systematic overestimation and frequent physical hallucinations (high FP rates, MCC near zero). Decomposition and atomic-level assessment significantly improves accuracy, lowering false positives and increasing MCC. Notably, Gemini models demonstrate the largest decomposition gains, while Claude models display high self-consistency. Embodiment bias persists: performance disparities across agent types are substantial, even in strong VLMs.
Reward-Based Improvement of Functional Reasoning
SceneTeract's diagnostic traces are repurposed as reward signals for reinforcement post-training of VLMs using Group Relative Policy Optimization (GRPO) with LoRA on a lightweight Qwen3-VL-4B-Instruct backbone. This targeted alignment demonstrably strengthens physically-grounded functional reasoning:
- Decomposed MCC increases by over 2x.
- FP rate sharply reduced (22.8% to 14.1%).
- Inclusivity gap across agent profiles is minimized.
This establishes a scalable, high-fidelity protocol for distilling geometric constraints into reasoning models, not only for inspection but for direct improvement of embodied semantic planners.
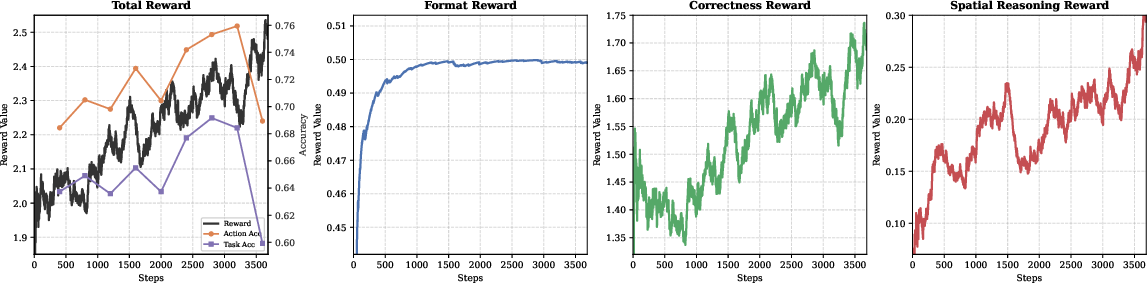
Figure 6: Training dynamics under GRPO—reward maximization tracks improved test-set accuracy; reward hacking risk underscores need for careful validation.
Theoretical and Practical Implications
SceneTeract delivers a hybrid architecture that couples flexible, open-ended VLM-based semantic task decomposition with formal, agent-specific geometric verification. This supports a paradigm shift from perception-first to functionality-centric evaluation in synthetic 3D environments, providing a rigorous foundation for accessible-by-design generation. SceneTeract exposes systemic limitations in current VLM architectures for grounding high-level semantic plans in physical reality; its use as a reinforcement signal enacts meaningful advances in multimodal model spatial grounding.
Practically, the framework can be immediately integrated into pipelines for auditing synthetic scene accessibility, robotic task planning, and VR/game environment generation where functional validity for diverse users is critical. Theoretically, results reveal that semantic competence in contemporary models is not sufficient for reliable embodied AI—the explicit incorporation of geometric constraint supervision is necessary.
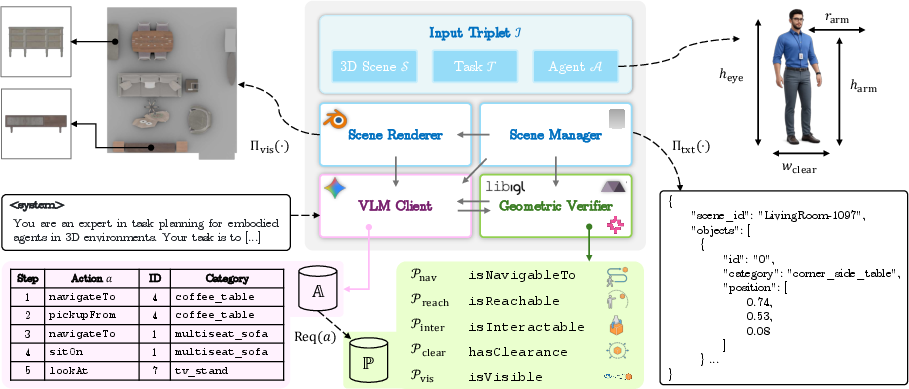
Figure 7: Modular implementation: Scene Manager, Renderer, VLM Planner, and Geometric Verifier interoperate over explicit agent/scene/task triplets.
Future Directions
The current instantiation focuses on static geometric snapshots without modeling temporal or dynamic environment updates. Extensions should address dynamic interaction, closed-loop synthesis, and on-the-fly correction in active planning contexts. SceneTeract’s modularization suggests natural generalization to iterative design feedback loops in generative modeling (e.g., scene RLHF), or as a scalable agent-centric critic in continuous embodied simulation and robotic control. Improved ergonomic and cognitive modeling of user capabilities, as opposed to geometric proxies alone, is a crucial direction for real-world deployment.
Conclusion
SceneTeract represents a standardized, open toolkit for bridging the still-significant gap between semantic plausibility and physically-constrained, agent-aware functional validity in 3D scene understanding. The framework unlocks new avenues for both assessment and functional alignment of VLMs and strengthens the methodological core of embodied AI evaluation routines. Its applicability spans scene synthesis, inclusive environment auditing, physically-grounded plan validation, and reinforcement-guided model improvement. Bridging perception and physical reality via integrated geometric reasoning is now demonstrably necessary and tractable for embodied scene understanding.