- The paper introduces the 2-datapoint reduced density matrix (2RDM) as a novel observable that captures phase transitions by measuring loss covariance in deep learning models.
- It employs spectral diagnostics, including the Spectral Heat Capacity (SHC) and Participation Ratio (PR), to provide efficient and interpretable early warnings of emergent transitions.
- Experimental evaluations across deep linear networks and transformers demonstrate the method's real-time monitoring capabilities and potential for mechanistic insights.
From Density Matrices to Phase Transitions in Deep Learning: Spectral Early Warnings and Interpretability
Introduction and Motivation
This work introduces the 2-datapoint reduced density matrix (2RDM) as a scalable and theoretically grounded observable for diagnosing and interpreting phase transitions during the training of deep neural networks. Drawing an analogy from the 2-electron reduced density matrix in quantum chemistry, the 2RDM constructed from per-sample loss covariances serves to characterize emergent phenomena—such as abrupt capability shifts or qualitative reorganizations in model behavior—via efficient forward passes on a probe set. Importantly, the proposed approach provides not only online detection but also interpretable mechanisms for these transitions, accessible even in large-scale models where conventional approaches are computationally prohibitive.
The 2-Datapoint Reduced Density Matrix
The 2RDM is defined for a probe set {(xi,yi)}i=1n and a sampling distribution ρ over the parameter space as
Cij=Covθ∼ρ[ℓi,ℓj]
with ℓi being the per-sample loss for (xi,yi) at parameter θ.
Two operational variants are analyzed:
- Gaussian 2RDM: Perturbations sampled around θ0 with i.i.d. Gaussian noise.
- Dynamical 2RDM: Covariance estimated over a temporal window of training checkpoints.
Model linearization yields C≈GΣθG⊤, where G is the sample-wise Jacobian of the loss and Σθ is the covariance of the parameter distribution. This decomposition connects the 2RDM with the empirical Fisher and, under Gaussian sampling, shows that the nonzero eigenvalues of ρ0 align with those of the Fisher up to scaling.
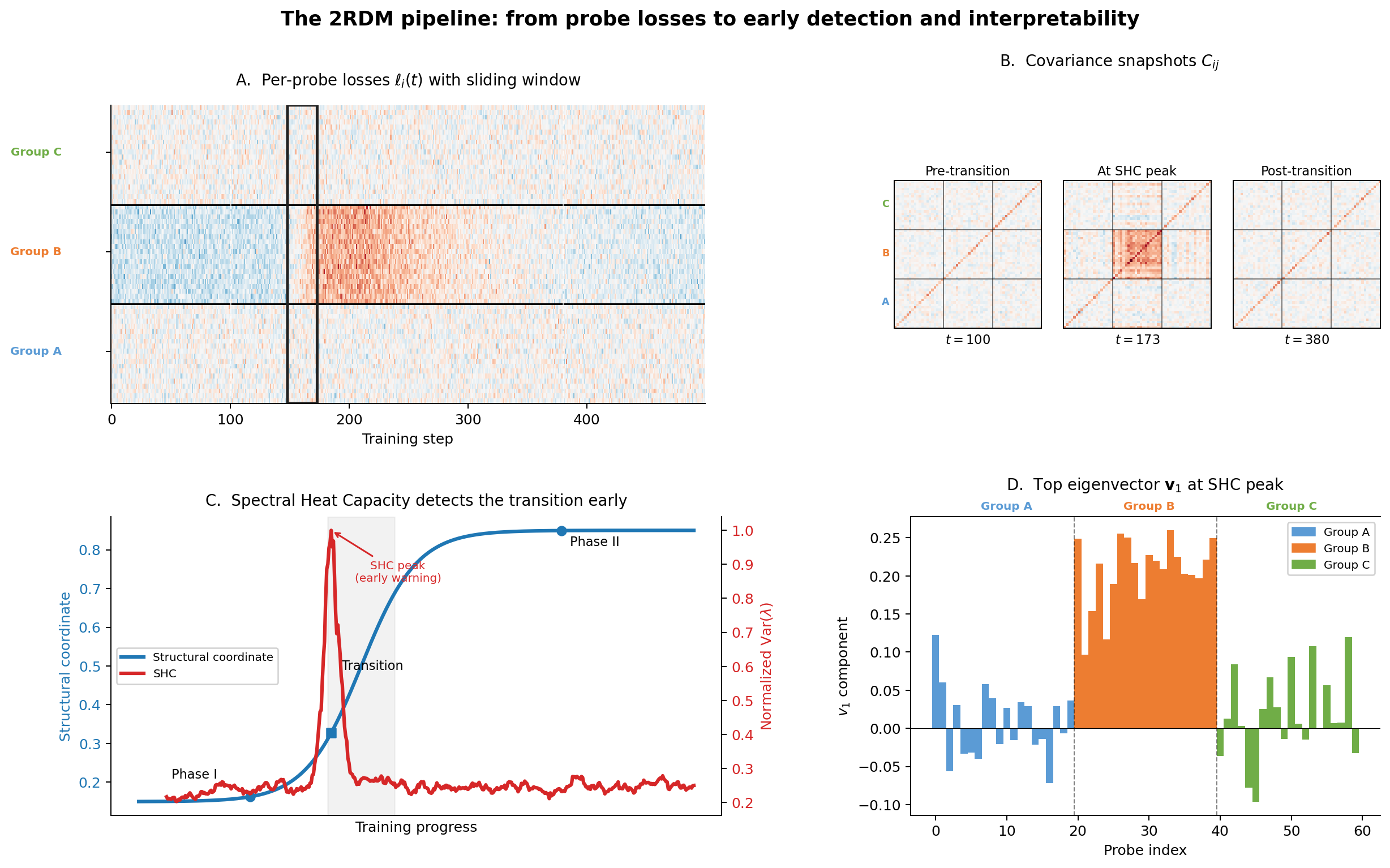
Figure 1: Schematic for 2RDM computation, block structure emergence, and spectral diagnostics during a phase transition.
Spectral Diagnostics: SHC and Participation Ratio
Two primary spectral quantities are derived from ρ1:
- Spectral Heat Capacity (SHC): The variance of the eigenvalues of ρ2. SHC spikes signal the onset of low-dimensional, coherent fluctuations—indicative of a phase transition.
- Participation Ratio (PR): Defined as ρ3. The PR quantifies the effective dimensionality of the transition; that is, the number of modes participating in the fluctuation.
Both metrics are cheap to compute relative to alternatives that require gradient or Hessian information, and they provide complementary perspectives: SHC is most sensitive to low-dimensional, anisotropic transitions, while PR diagnoses the collective dimensionality of reorganizing modes.
Mechanistic Interpretability via Eigenvectors
A distinctive virtue of the 2RDM is the direct interpretability of its leading eigenvectors. The top eigenvector ρ4 highlights which probe samples experience correlated loss fluctuations during a transition, enabling attribution of emergent behaviors to specific data modalities, algorithmic features, or semantic groups. When a canonical basis is available (e.g., Fourier or semantic categories), ρ5 can be further analyzed for mechanistic insights.
Experimental Evaluations
Four archetypal phase transitions are examined:
Deep Linear Networks – Silent Alignment
In deep linear networks (DLN), the SHC and PR spike concurrently at the moment of mode-wise silent alignment, confirming that the 2RDM tracks first-order (nucleation-like) transitions reliably. The PR remaining ρ6 throughout each mode's transition corroborates the singular-mode dynamics described in analytic results.
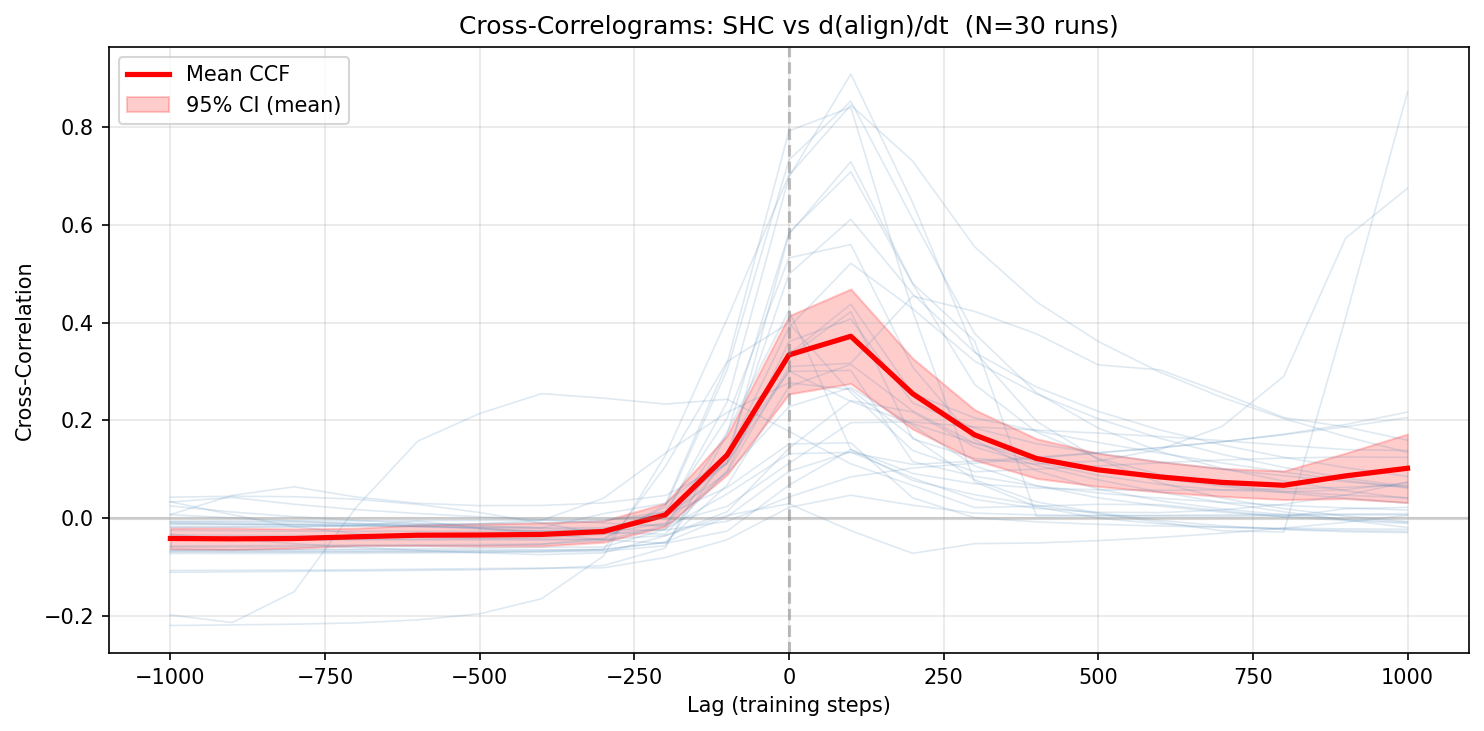
Figure 2: Average lag between the SHC spike and mode alignment in DLN training; minimal lag indicates accurate detection alignment.
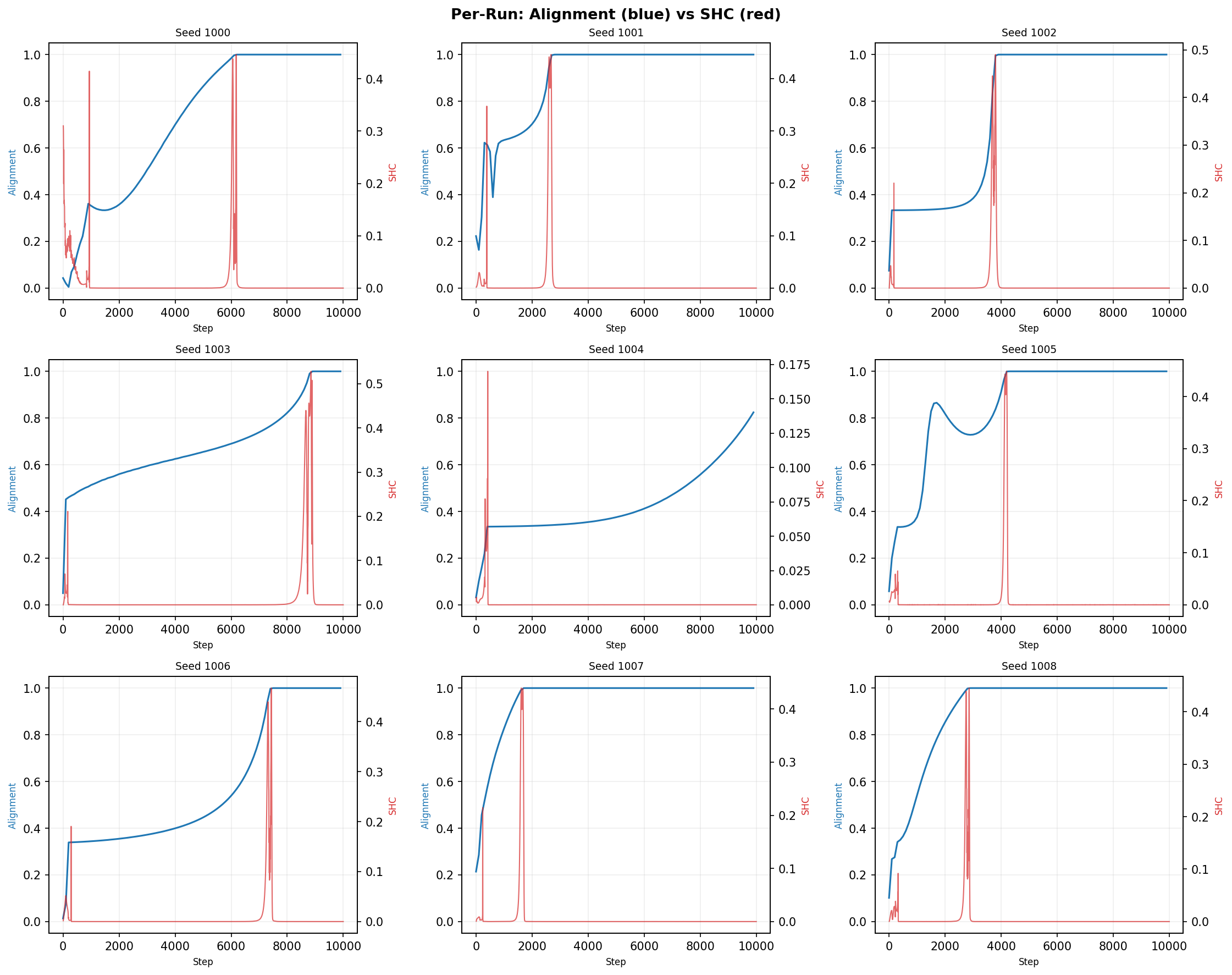
Figure 3: Example DLN training runs; spikes in SHC temporally align with silent alignment events.
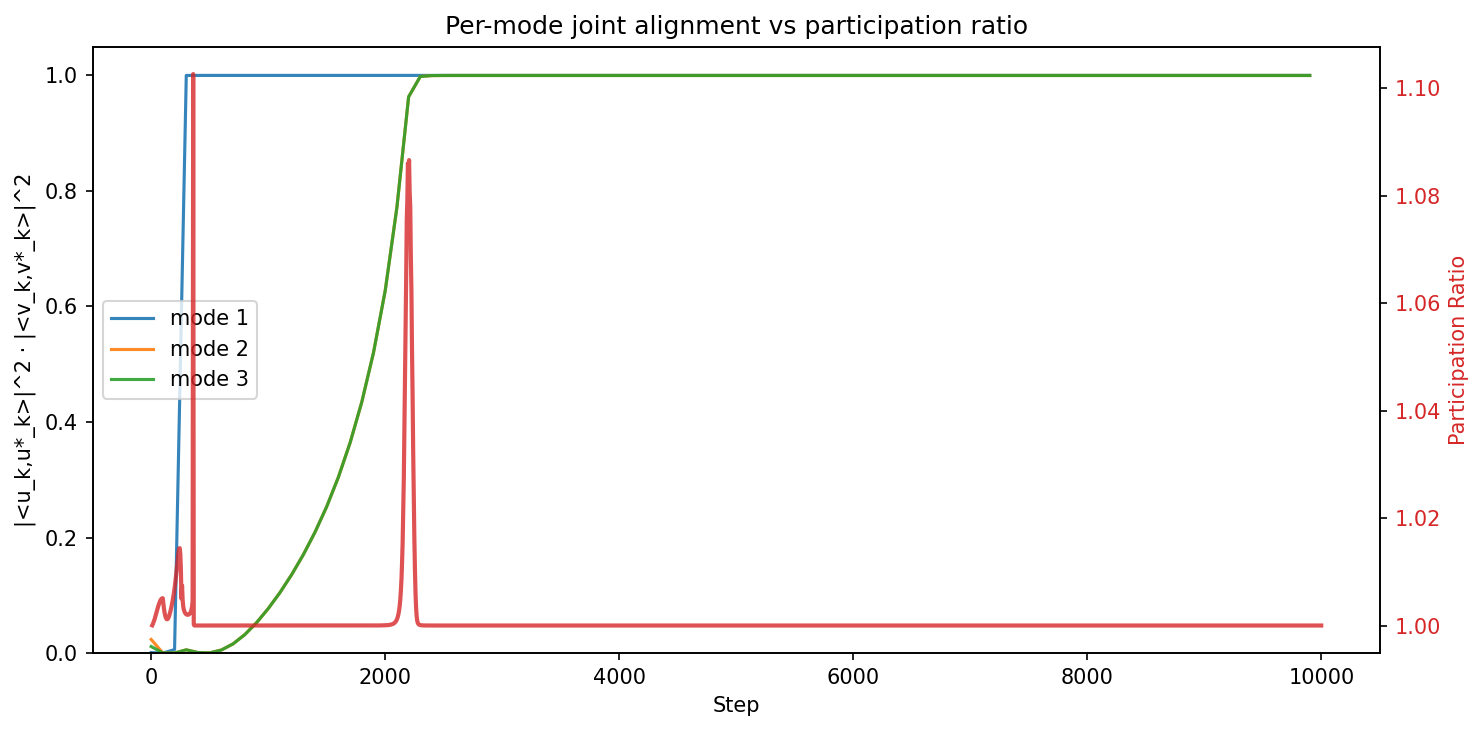
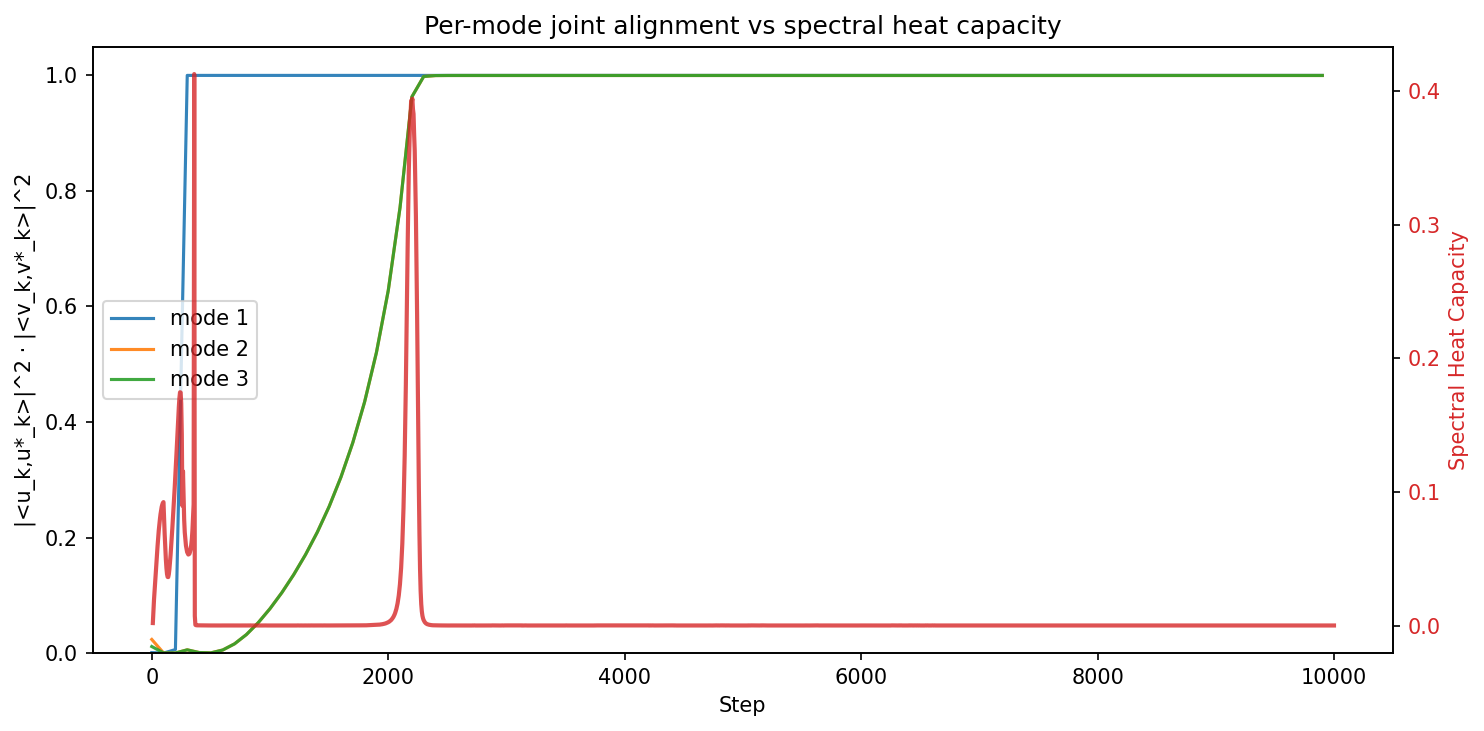
Figure 4: Temporal evolution of alignment and the participation ratio during DLN training.
In the emergence of induction heads, SHC detects and anticipates the critical instantiation of the head mechanism before behavioral scores change, with PR signaling the dimensionality of the rearrangement. Importantly, the top eigenvector’s support is highly correlated with sequences benefiting from the induction circuitry, confirming interpretability and specificity.
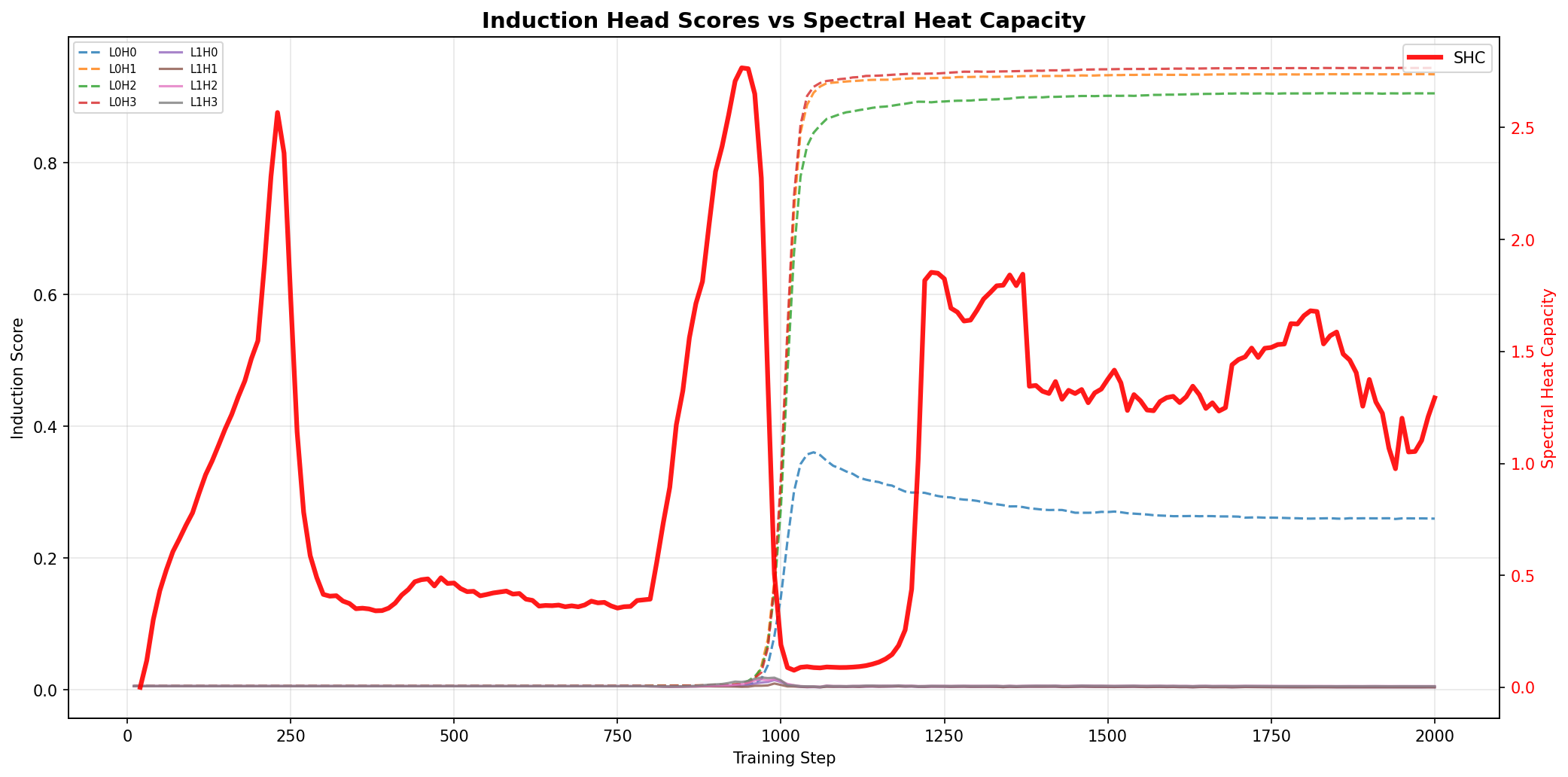
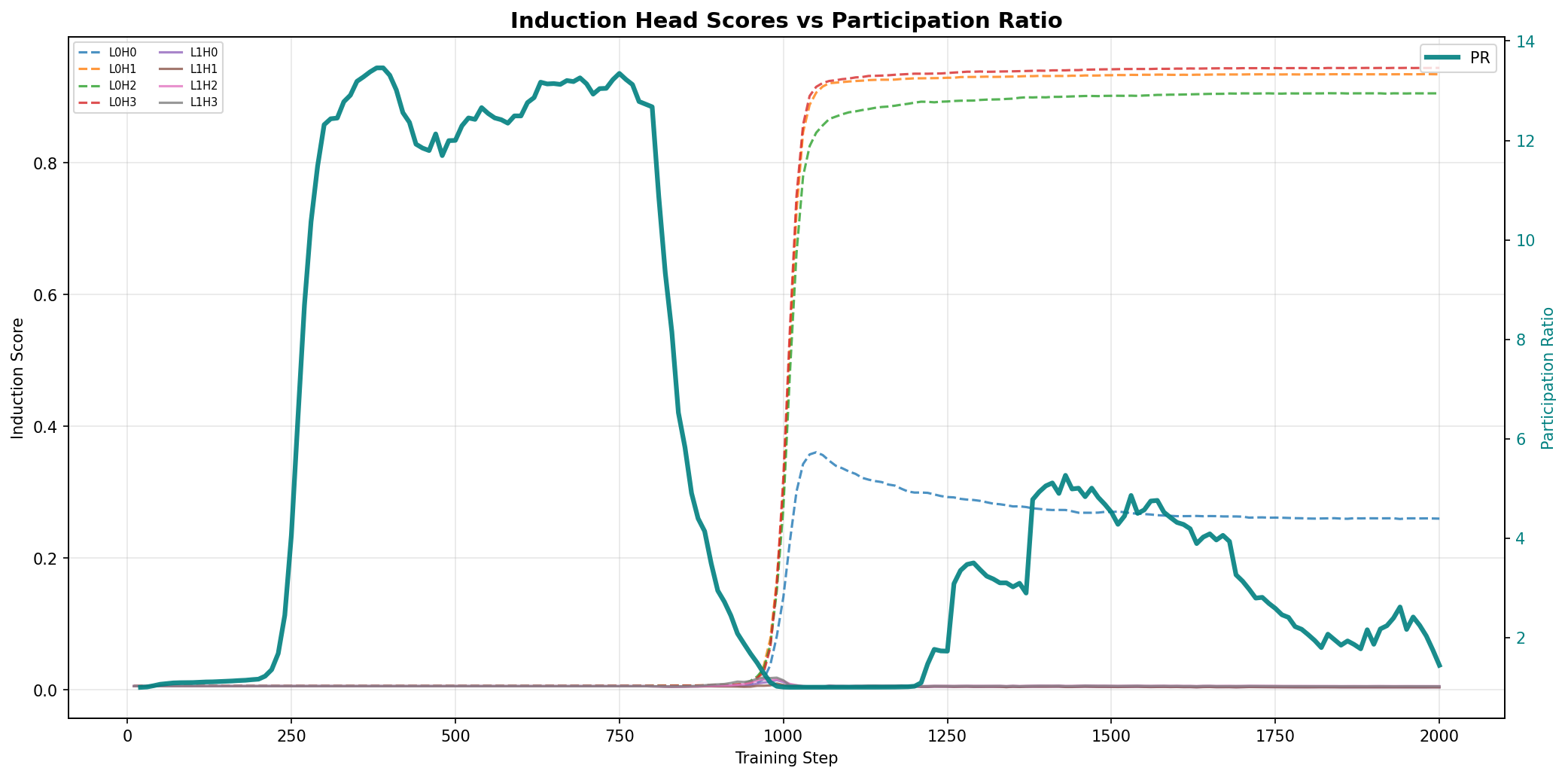
Figure 5: SHC versus induction head scores during transformer training, emphasizing the SHC’s predictive power.
Grokking: Modular Arithmetic Phase Transition
For "grokking," both train and test block SHC reveal distinct spikes: one associated with training accuracy increase, and another with generalization. Fourier analysis of ρ7 demonstrates that the phase transition is tied to alignment with group-theoretic structure (dominant Fourier modes) in test data, differentiating memorization from generalization.
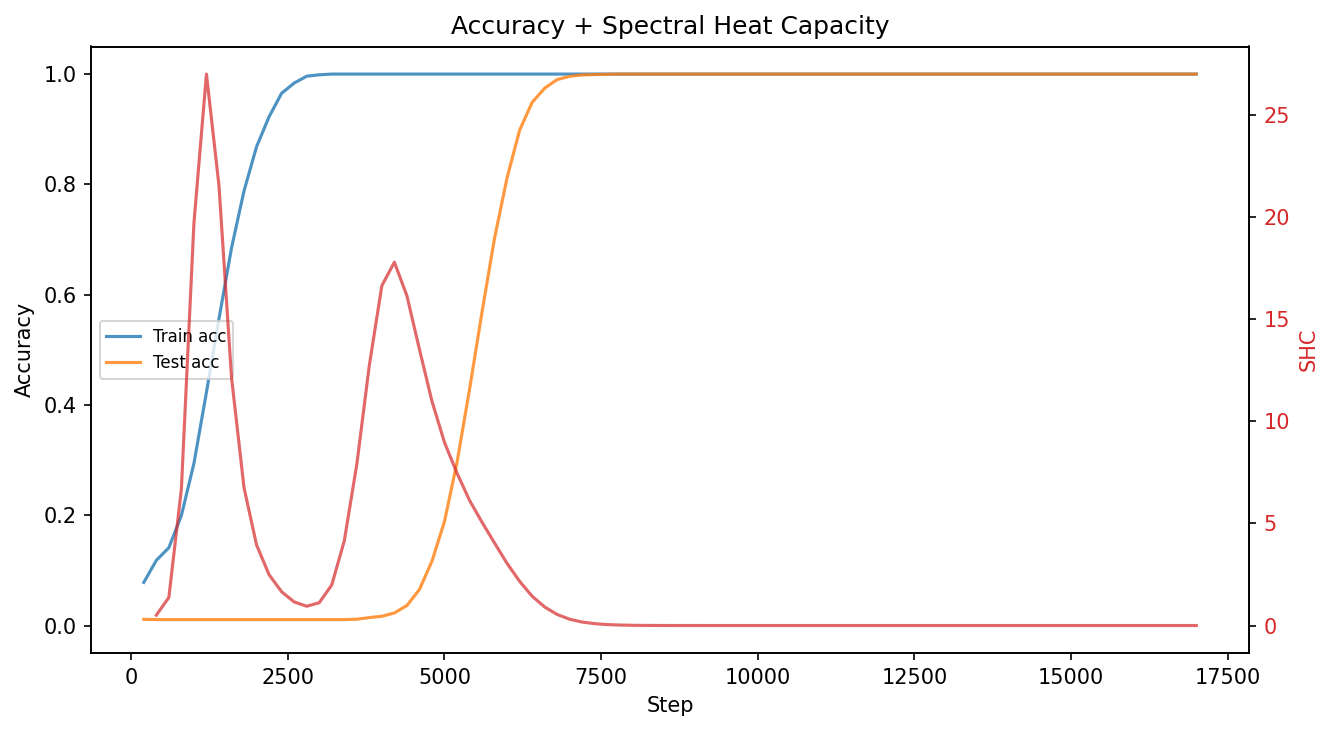
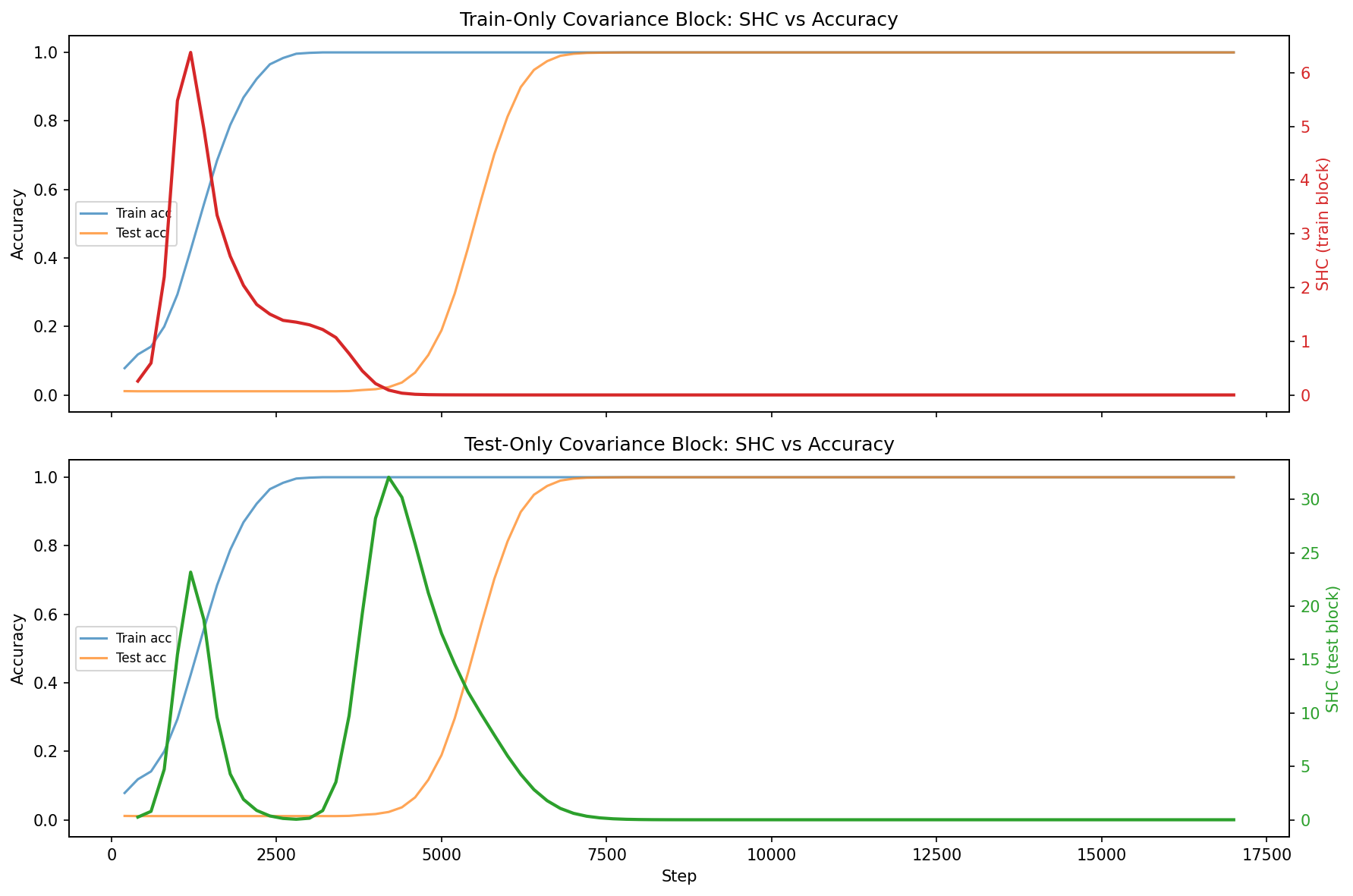
Figure 6: SHC trajectories for both train and test data against accuracy, illustrating the correspondence between SHC spikes and phase transitions.
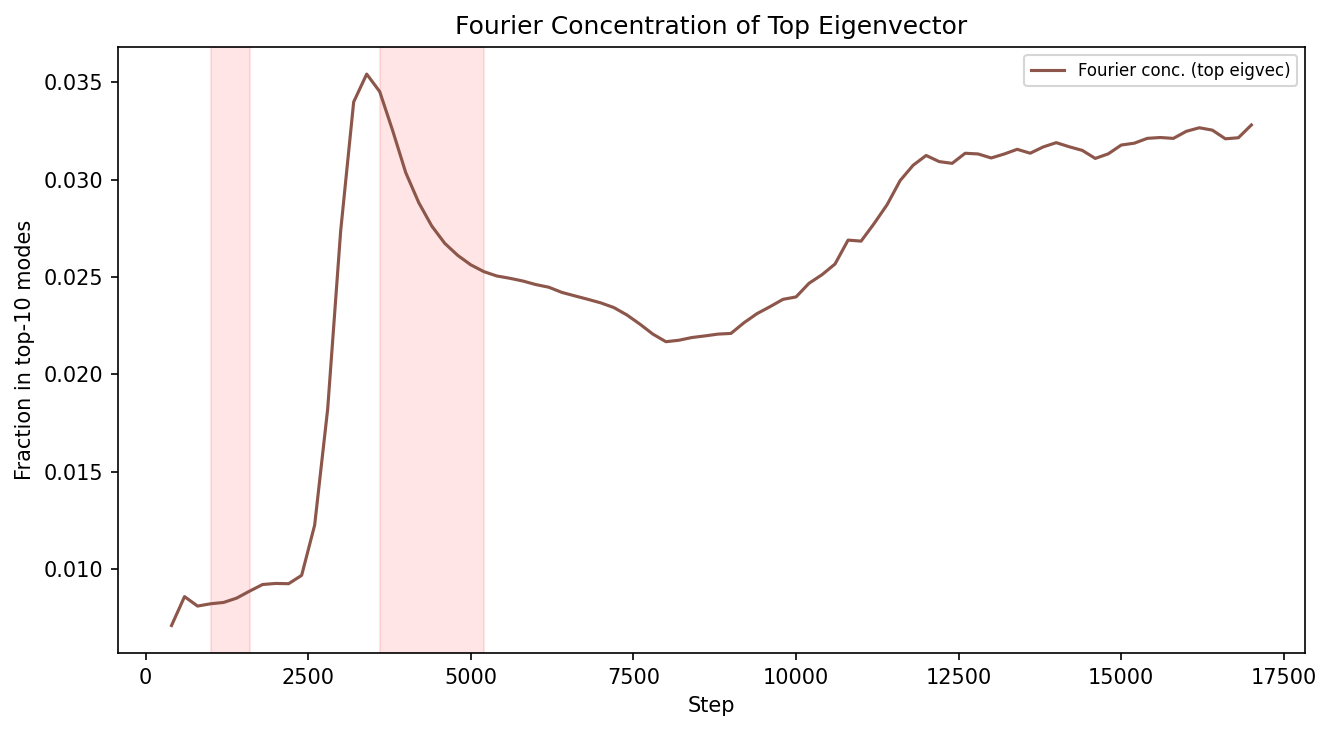
Figure 7: Concentration of Fourier modes in the top eigenvector during grokking, revealing alignment with algebraic structure at transition.
Emergent Misalignment in LLMs
Applying the Gaussian 2RDM to a Qwen 2.5-based LLM fine-tuned with misalignment-inducing data, SHC localized on alignment probe categories reveals early structural shifts before full behavioral emergence. The variance signal is highly localized in probes tied to alignment, not in benign capabilities or unrelated categories—providing a fine-grained diagnostic of incipient misalignment.
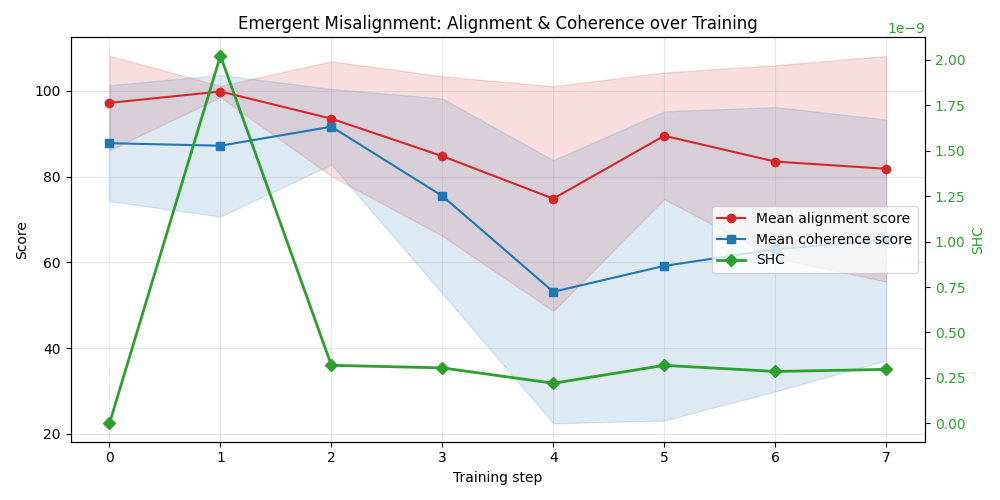
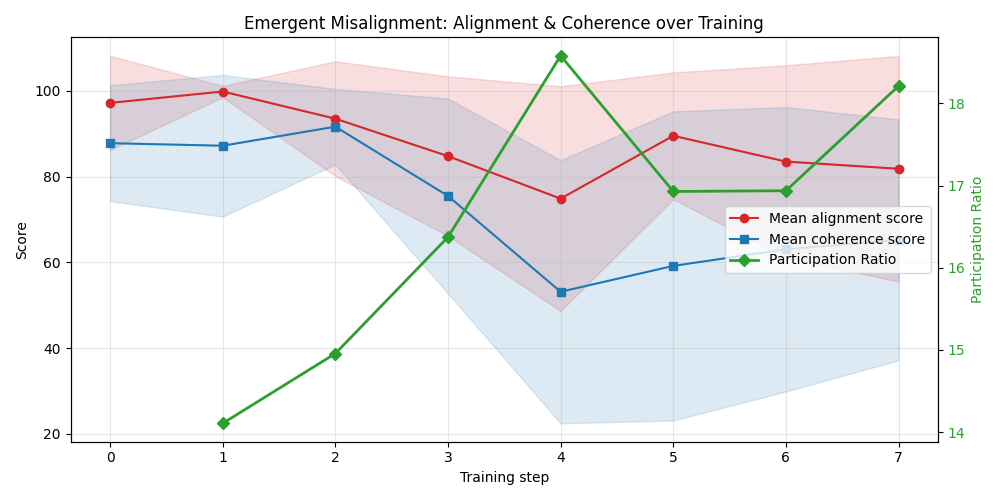
Figure 8: SHC and misalignment scores over early fine-tuning steps, highlighting early internal reorganization.
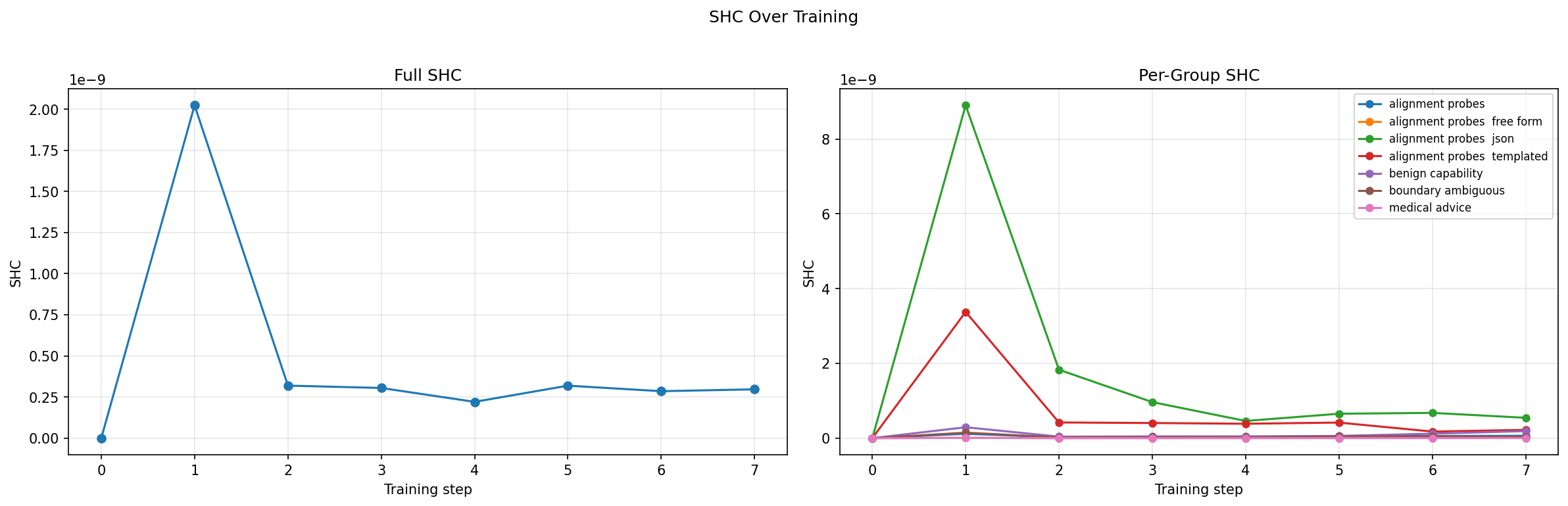
Figure 9: Decomposition of total variance across probe groups; only alignment-focused probes exhibit increased variance during transition.
Theoretical Analysis
Formally, the SHC is shown to act as an early-warning statistic for second-order transitions, rigorously tracking critical slowing down along reorganizing directions. For first-order transitions, SHC aligns with the event itself, revealing abrupt landscape reorganization. The PR further discriminates between low-rank and distributed transitions, while eigenvector structure (and groupwise decompositions of ρ8) elucidates which probe subspaces and data categories drive observed phenomena.
Computational and Practical Considerations
An online 2RDM protocol is computationally efficient, requiring only ρ9 forward passes per evaluation step for a probe set of size Cij=Covθ∼ρ[ℓi,ℓj]0. Covariance computation is Cij=Covθ∼ρ[ℓi,ℓj]1 for window size Cij=Covθ∼ρ[ℓi,ℓj]2, and diagnosis can be restricted to periods signaled by SHC spikes to further reduce overhead.
Optimal probe set design—akin to basis selection in quantum chemistry—remains an open problem; however, experimental evidence demonstrates the utility of both random and targeted sampling strategies. The method is robust to training scale and model size, as no backward or second-order derivatives are required.
Implications and Future Directions
This framework provides a computationally-accessible, interpretable, and theoretically-justified basis for real-time monitoring of phase transitions in training. Beyond serving as a diagnostic, the interpretability of 2RDM eigenvectors opens prospects for mechanistic interventions and ablation studies—for example, identifying modes contributing to undesirable transitions (e.g., misalignment) and designing targeted regularization or curriculum adjustments accordingly.
Key avenues for future development include systematic strategies for probe set selection and active submatrix diagnostics, integration with causal/gradient-based attribution for directionally decomposing emergent dynamics, and extending the method to non-stationary or curriculum-based training protocols.
Conclusion
The 2-datapoint reduced density matrix and its spectral properties constitute a powerful framework for detection, analysis, and mechanistic interpretation of phase transitions in deep learning. Through an overview of concepts from statistical physics, quantum chemistry, and information theory, this approach reifies the connection between geometric loss landscape statistics and emergent learning phenomena. The interpretive and practical advantages detailed here suggest paths forward in both basic research (e.g., structure of learning dynamics) and in risk mitigation for real-world AI systems.
Reference: "From Density Matrices to Phase Transitions in Deep Learning: Spectral Early Warnings and Interpretability" (2603.29805)