- The paper introduces a unified framework that integrates quantization via clustering with LLVM-based GEMV replacement to compile code LLMs into lightweight executables.
- It employs product-quantization inspired techniques to reduce model bitwidth while bounding errors and leverages automated compiler passes to substitute naïve GEMV operations with optimized BLAS calls.
- Empirical evaluations reveal up to 10.5× speedup and significant memory reduction, enabling practical inference on commodity devices without GPUs.
Compiling Code LLMs into Lightweight Executables: Program-Level Optimization for Efficient On-Device Deployment
Large code-oriented LLMs, such as Code Llama, MagicCoder, and OpenCodeInterpreter, are widely adopted for various software engineering tasks, primarily through cloud-deployed inference. However, this paradigm presents persistent challenges: privacy risks from code and data transmission, variable network latency, dependency on connectivity, and high resource requirements for on-device execution. Most commodity devices lack high-performance accelerators or sufficient DRAM to host multi-billion parameter models using naive implementations. While quantization and distillation-based compression can reduce model size, they are generally disconnected from the structure of the inference program, missing further efficiency gains at the code execution level.
The paper introduces \tool, a pipeline that compiles code LLMs into lightweight executables optimized for resource-constrained devices. The framework consists of two tightly coupled phases: (1) model weight quantization via clustering and bit-packing, and (2) compilation-time optimization that systematically rewrites inefficient GEMV (general matrix-vector multiplication) operations into highly optimized BLAS library calls.
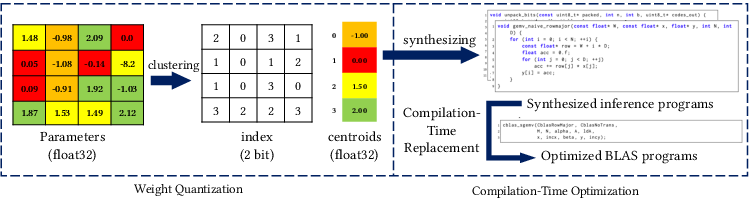
Figure 1: Overview of \tool's two-phase optimization framework, coupling quantization and compilation-level GEMV acceleration for substantial memory and latency reductions.
Phase 1 compresses floating-point weight matrices into low-bitwidth centroid indices, significantly lowering the memory footprint. Phase 2 infers GEMV patterns in C/C++ inference code and replaces them through automated LLVM passes with architecture-tuned GEMV routines from standard BLAS libraries.
Model Quantization via Clustering and Bit-Packing
The quantization methodology is inspired by product quantization techniques but is adapted for the demands of LLM deployment, emphasizing error-bounded approximation and hardware compatibility. Weights in each layer are sorted and clustered (using a variant of K-Means targeting equal cluster populations, minimizing weighted L1 error). Centroids are then computed and each weight is represented by a compact centroid index, enabling significant bitwidth reduction (e.g., 3 bits for 8 centroids per layer), and all indices are efficiently serialized into a compact bit-packed stream. This maintains negligible accuracy loss, as the quantization error is provably bounded by the centroid assignment, allowing theoretical guarantees on GEMV output magnitude.
During inference, the bit-packed weights are efficiently unpacked and centroids are lazily reconstructed, ensuring that the computational pipeline is not bandwidth-limited by redundant data movement. This error-aware quantization with centroid lookup minimizes the tradeoff between compression and loss, outperforming simple int8 quantization as shown in the reported evaluations.
Compiler-Level Optimization: Automating GEMV Replacement
A central contribution of the pipeline is the integration of an LLVM IR pass that automates the identification and replacement of naively-implemented GEMV code sections. Rather than relying on ad-hoc pattern matching, the pass uses custom matchers extending LLVM's PatternMatch API, robustly detecting GEMV idioms independent of loop unrolling, induction variable usage, or memory access layout. The compiler checks legality through dependence analysis and infers memory layout (row-major vs. column-major), ensuring that code transformations are safe.
Once GEMV code is matched and verified, it is replaced by calls to highly optimized BLAS routines (e.g., cblas_sgemv for single-precision inference), thereby exploiting platform-level vectorization, cache blocking, and hardware-accelerated FMA instructions. This approach completely eliminates manual kernel optimization, delivering portable and maximal performance improvements across target CPUs.
Empirical Results: Code LLMs on Commodity CPUs
The pipeline is evaluated on Code Llama-7B, MagicCoder-CL-7B, and OpenCodeInterpreter-CL-7B across HumanEval+ and MBPP+ code generation benchmarks, with deployment on a consumer-grade Apple M2 CPU. The framework achieves:
- Up to 10.5× speedup and 6.4× memory reduction versus full-precision naive inference
- Substantially better performance and accuracy than int8 quantization (up to 2.2× throughput, 1.6× further memory savings, and up to 6.96% higher pass@1 accuracy)
- Negligible degradation in pass@1 code generation accuracy under 3-bit quantization: average loss is only 0.27%
- Energy efficiency improvements matching latency gains (up to 10.5× less energy per token generated)
Ablation analysis confirms that quantization alone provides memory reduction but introduces minor overhead during centroid lookup, while BLAS-only replacement accelerates computation without reducing memory footprint. Only their combination yields synergistic benefits (exceeding the sum of individual improvements), as quantization mitigates memory bandwidth bottlenecks and GEMV substitution exploits compute and cache locality.
Sensitivity, Generality, and Comparisons with Alternative Approaches
Analysis of different quantization bitwidths reveals diminishing returns past 3 bits for code LLMs: further reducing quantization error (ε) does not tangibly improve functional accuracy, but incurs linear increases in memory/energy cost. The framework outperforms state-of-the-art quantization (AWQ, GPTQ) in CPU contexts because such methods rely on custom GPU kernels or require dequantization overhead, neutralizing their theoretical efficiency. \tool's design—marrying quantization with corresponding inference kernel substitution—ensures that performance gains in storage directly translate to execution speed, a property missing from purely model-level approaches.
The pipeline generalizes across Transformer-based model families, including those with different attention and FFN architectures (e.g., Qwen, LLaMA, TinyLLaMA), and across domains outside code (e.g., general-purpose LLMs).
Implications and Theoretical Impact
The integration of model quantization, program-level synthesis, and compiler optimization in a unified deploy-time pipeline has significant practical and theoretical consequences:
- Practical Deployment: Enables on-device inference of multi-billion parameter LLMs on laptops/desktops without requiring GPUs or datacenter-class DRAM, directly addressing barriers to privacy, energy footprint, and end-user latency.
- Software Engineering Tools: Fosters the development of responsive, privacy-preserving code completion, linting, and analysis tools integrated into developer IDEs, lowering TCO and environmental impact.
- System Design: Demonstrates the importance of jointly optimizing model and execution—compression and program transformation should not occur independently, as the overall deployment efficiency is non-additive.
- Green AI and Sustainability: Offers an effective method towards more sustainable LLM serving by reducing not only energy consumption but also requirements for hardware upgrades, indirectly lowering global AI carbon emissions.
Prospects for Future Research
Extensions include broadening support for alternative inference backends (e.g., llama.cpp, TensorFlow), optimizing additional hardware-specific kernels beyond GEMV (e.g., attention, batched matmuls), and extending the compiler pipeline to multimodal and encoder-decoder architectures. Another important direction is dynamic precision adaptation—leveraging quantified error bounds to variably adjust bitwidth depending on criticality or input characteristics in production environments.
Conclusion
The work presents a rigorous framework that bridges the gap between high-level model compression and low-level inference optimization for code LLMs deployed on commodity hardware. By co-designing quantization schemes and compiler-managed code transformation, the approach sets a new state-of-the-art in practical LLM deployment efficiency, establishing a model for future advances in efficient, sustainable, and private AI-powered software development tools (2603.29813).

