- The paper introduces loss gap parity, shifting fairness from absolute loss equality to relative improvement across clients.
- EAGLE employs a regularized objective that penalizes loss gap variance, aligning client performance with their intrinsic task difficulty.
- Empirical results show that EAGLE reduces loss gap variance and boosts worst-case client performance compared to FedAvg and loss parity methods.
Loss Gap Parity for Fairness in Heterogeneous Federated Learning
Motivation and Limitations of Loss Parity
Federated learning (FL) orchestrates collaborative training across decentralized clients, enabling models to harness knowledge from distributed data without direct access to local datasets. In practical settings—such as healthcare, finance, and regulated domains—the default optimization paradigm, FedAvg, focuses on minimizing the mean local client loss, generally weighted by data size. However, this protocol incentivizes clients with larger or more homogeneous datasets, thereby inducing severe fairness issues in heterogeneous environments, as it disregards differences in task complexity and data quality across clients.
Loss parity has emerged as a popular notion to address fairness in FL, targeting equalization of raw local losses across clients. This definition presumes loss comparability and ignores structural heterogeneity. When data distributions, label complexity, or noise characteristics diverge, enforcing loss parity may trigger the "leveling-down" effect: degrading already performant clients without material benefit to the worst-off, and distorting the global optimization landscape (see Figure 1).
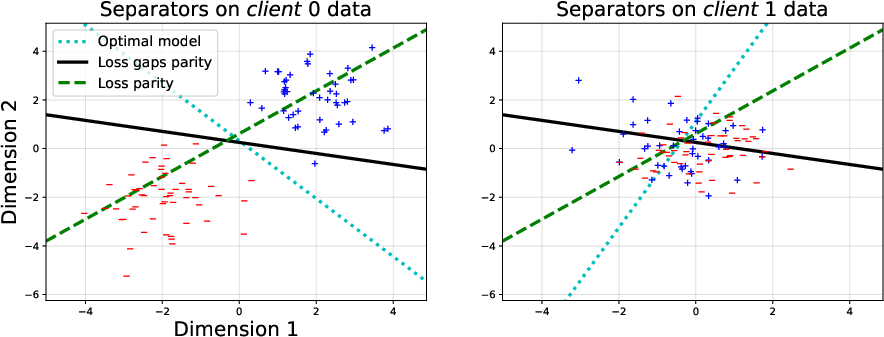
Figure 1: AFL enforces loss parity, worsening performance for clt~0 with easier data, while EAGLE's loss gap parity delivers balanced improvements regardless of intrinsic task difficulty.
Loss Gap Parity: Fairness in Relative Improvement
The authors introduce loss gap parity, advocating fairness in terms of relative improvement. The loss gap for client k is defined as rk(θ)=Lk(θ)−Lk∗, the difference between the loss attained by the global model and the minimal achievable local loss for that client. In heterogeneous settings, enforcing parity in these loss gaps mitigates the leveling-down effect, as it respects the intrinsic difficulty of each client's problem. Here, fairness is defined by similarity in excess risk relative to each client's local optimum, allowing clients with easier tasks to benefit without forcibly aligning their performance downward to match clients with harder data distributions.
Empirically, Figure 2 demonstrates that loss-gap aware methods (EAGLE) effectively allocate benefit across clients, whereas loss-parity-based algorithms (q-FFL, AFL) elevate losses for easier clients with minimal or no concomitant gain for those with complex/noisy data.
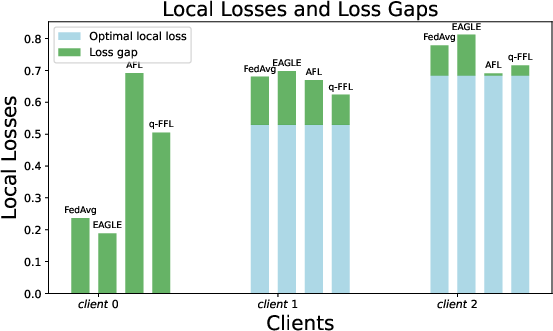
Figure 2: Loss gap parity via EAGLE results in uniform relative improvements; loss parity methods skew optimization toward harder tasks, penalizing clients with separable data.
The EAGLE Algorithm: Regularized Optimization for Loss Gap Parity
EAGLE augments the standard federated objective with a regularization term penalizing the variance of loss gaps across clients:
F(θ)=K1k=1∑KLk(θ)+V({rk(θ)}k=1K)
The regularization parameter λ governs the fairness–utility trade-off. For practical deployment, EAGLE employs a reweighted gradient scheme, where client updates are scaled by weights derived from current loss gap disparities, periodically communicated and normalized to stabilize optimization. The algorithm assumes proxies for optimal local losses (Lk∗), estimated via local validation or pre-training.
EAGLE converges to stationary points under non-convexity, with explicit bounds on convergence rate and a formal characterization of induced utility loss as a function of client heterogeneity Γ and regularization intensity λ. For low heterogeneity or small λ, the penalty on global utility remains negligible.
Empirical Analysis: Synthetic and Real-World Benchmarks
Experiments validate EAGLE on synthetic data, EMNIST, and DirtyMNIST, comparing against FedAvg, q-FFL, and AFL across both linear and convolutional models. Data splits are parametrized for heterogeneity via Dirichlet allocation (α), enabling rigorous exploration across FL regimes. Figure 3 quantifies variation in optimal local losses as heterogeneity escalates (α→0).
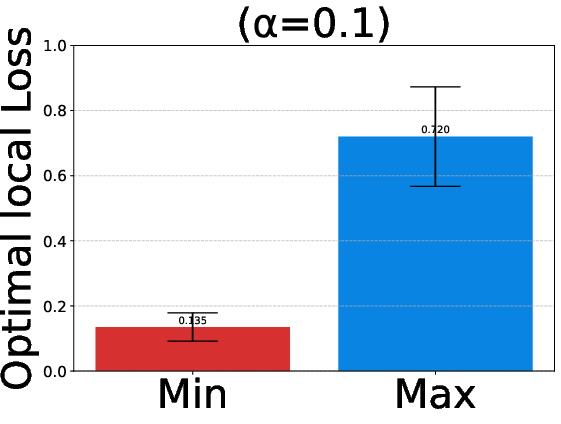
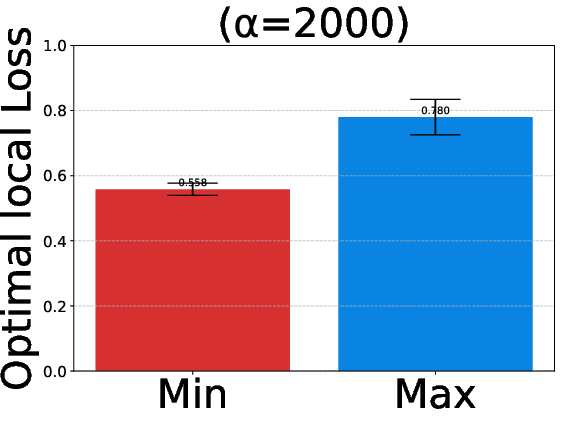
Figure 3: EMNIST heterogeneous splits yield wide dispersion in optimal local losses; homogeneous splits converge to tighter ranges.
EAGLE consistently achieves lower variance in loss gaps, with substantial improvement for worst-off clients. Figure 4 on CNN models for non-IID data illustrates marked reduction in loss gap variance under EAGLE compared to baselines.
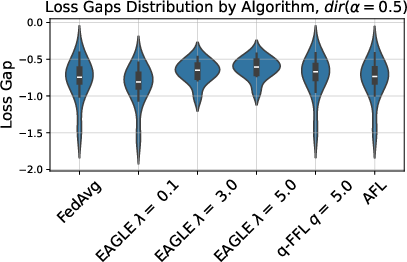
Figure 4: In highly heterogeneous settings, EAGLE tightens loss gap variance and lifts the worst-performing client.
Synthetic data analysis reveals that enforcing loss parity (AFL, q-FFL) biases optimization toward clients with difficult data, substantiated by Figure 5 and Figure 6, which depict underlying data distributions and evolution of local losses, respectively.
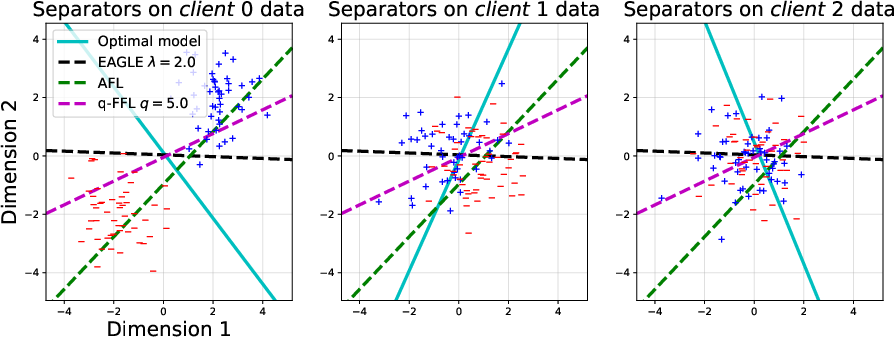
Figure 5: Rotations and synthetic distribution create misaligned optimal separators and conflicting gradient directions.
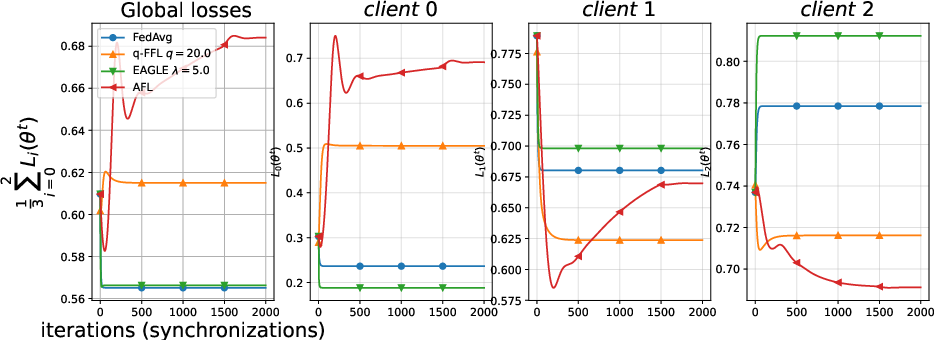
Figure 6: AFL/q-FFL drive up losses for clt~0, failing to balance clt~1 and clt~2; EAGLE achieves equitable excess risk.
Implications and Limitations
EAGLE provides robust fairness guarantees for FL in heterogeneous environments, particularly cross-silo settings where client data sources exhibit structural diversity. By prioritizing loss gap parity, it aligns the fairness objective with practical desiderata—relative improvement—rather than absolute loss equality. This formulation circumvents known pitfalls of loss parity-driven "leveling down", supports controlled fairness–utility trade-offs, and theoretically accounts for the impact of data heterogeneity.
Practically, EAGLE’s reliance on accurate estimation of rk(θ)=Lk(θ)−Lk∗0 and continuous client participation limits applicability in cross-device FL with intermittent communication and limited data. Furthermore, hyperparameter selection for rk(θ)=Lk(θ)−Lk∗1 is critical: excessive regularization ultimately sacrifices overall utility in favor of strict parity, a behavior observed in empirical analysis. These caveats highlight the need for adaptive and scalable proxies for local optimality and dynamic regularization.
Conclusion
This paper introduces loss gap parity as a principled fairness criterion for FL, departing from loss parity in heterogeneous environments. The EAGLE algorithm operationalizes this via regularized optimization, providing both theoretical convergence guarantees and empirical evidence of improved fairness across clients. The approach addresses salient limitations of prior methods, specifically the leveling-down effect, and advances foundations for distributive justice in collaborative FL. Future directions include adaptive estimation of local optima, scalable deployment in cross-device settings, and automated regularization tuning to balance fairness and global utility (2603.29818).