- The paper demonstrates that independent aggregation via the Hybrid Confirmation Tree (HCT) increases decision accuracy by up to 6.6%, outperforming traditional AI-advisor models.
- The HCT method collects independent decisions from both humans and AI, using a secondary human tiebreaker to correct errors from correlated judgments.
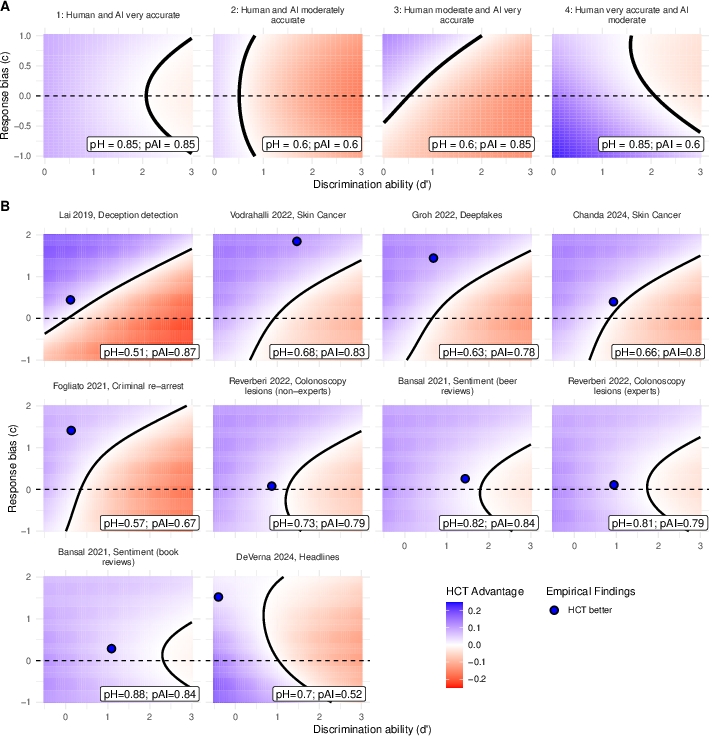
- Signal Detection Theory analysis reveals that limited human discrimination and suboptimal response bias underpin the advantages of independent aggregation over advice-taking.
Independent Human-AI Aggregation Surpasses Sequential Advice-Taking
Introduction
This paper rigorously compares two fundamentally distinct paradigms for operationalizing human-in-the-loop AI in decision-making: the dominant AI-as-advisor protocol, where humans conditionally accept or reject recommendations from an AI, versus the Hybrid Confirmation Tree (HCT) protocol, where AI and human decisions are elicited independently and, in case of disagreement, arbitration is delegated to a second human. Leveraging ten datasets spanning high-stakes applications (medical diagnostics, recidivism prediction, political misinformation, etc.), the authors demonstrate that the HCT systematically surpasses the traditional AI-as-advisor scheme, irrespective of the availability of XAI explanations or varying operator expertise. Theoretical analyses using Signal Detection Theory (SDT) elucidate why even explainable advice underperforms compared to independent aggregation: human inability to reliably discriminate correct from incorrect AI advice and suboptimal advice uptake (response bias).
Methodology and Experimental Framework
The HCT procedure involves the following sequence: collect initial decisions independently from both a human and an AI; if their responses concur, this consensus is enacted; in cases of disagreement, a second human “tiebreaker” determines the final outcome. In contrast, the AI-as-advisor approach presents the human with AI advice, allowing them to update their decision accordingly or disregard the suggestion. Datasets comprised 41k+ human decisions, covering medical, forensic, and social cognition tasks, with independent test sets containing human-only, AI-only, and advice conditions for direct protocol comparison. Multiple datasets also include “explainable-AI” treatments, providing not only recommendations but also model-generated explanations.
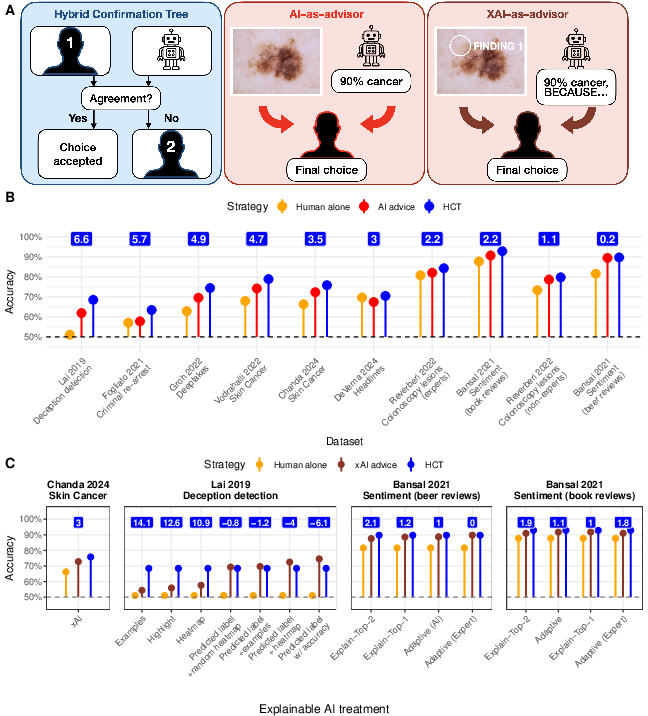
Figure 1: Workflow of the HCT versus the sequential AI-as-advisor model and corresponding mean accuracy across datasets, highlighting the consistent improvement from HCT.
Empirical Results
Across all ten datasets, the HCT outperformed the AI-as-advisor approach with improvements ranging from 0.2 to 6.6 percentage points (mean improvement: 4.5 points, 95% HDI 3.7–5.3). Crucially, these advantages were robust to task type, base rates, and participant expertise, as demonstrated by further stratification on human baseline performance. More notably, even when the AI-advisor was augmented with explanations (XAI), the HCT maintained a performance edge in 11 out of 16 settings. The only notable HCT deficits occurred in settings where unaided human performance was at or near chance, in which case the value of independent aggregation collapses due to tiebreaker unreliability.
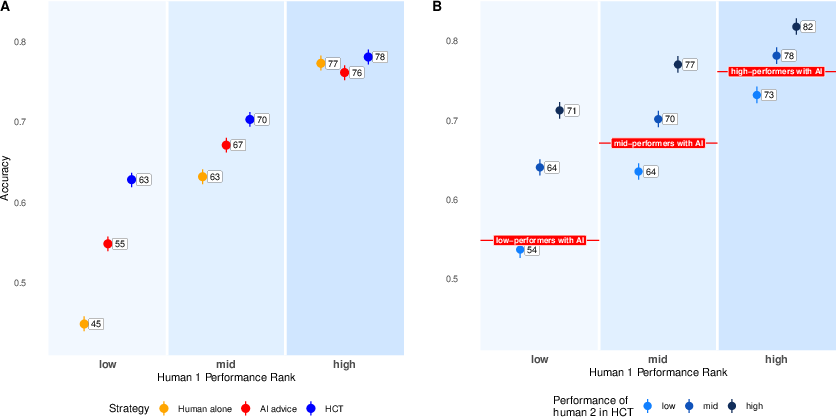
Figure 2: HCT, AI-as-advisor, and unaided human performance as a function of individual baseline human accuracy and the expertise rank of the tiebreaker.
The accuracy improvement from HCT traces to its mechanism: cases of human-AI disagreement, which occurred in 20–49% of trials depending on dataset, are more likely to be resolved correctly by an independent tiebreaker than by an advice-taker weighing an opposing (but correct) AI suggestion. When the AI was correct, HCT aggregated to the correct choice 71% of the time versus 34% uptake in the advice scenario. However, when the AI was wrong, advice-takers more often rejected erroneous advice compared to HCT tiebreakers.
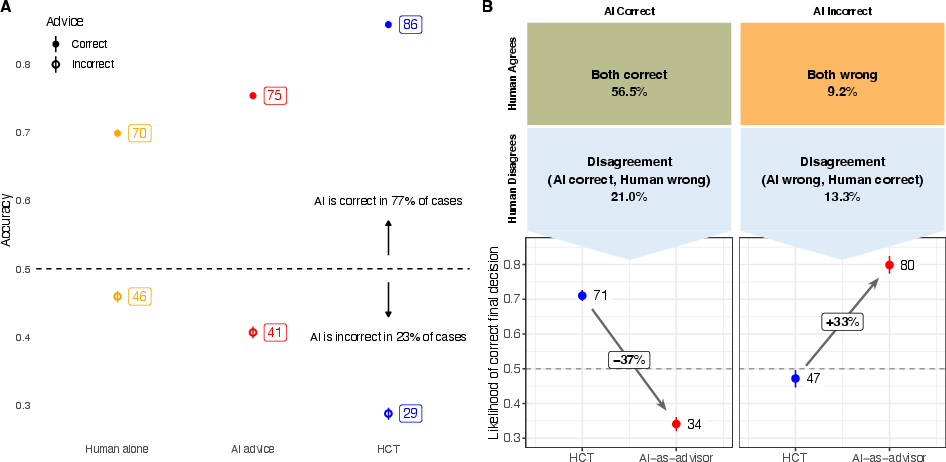
Figure 3: Comparison of HCT and AI-as-advisor accuracy contingent on whether the AI provides correct or incorrect recommendations; bottom panels analyze performance specifically for disagreement cases.
Signal Detection Theory Analysis
The authors formalize AI-advice uptake as a classical SDT discrimination task. The key parameters are discrimination ability (d')—the extent to which humans distinguish correct/incorrect advice—and response bias (c), indicating general advice uptake tendency. The SDT model reveals:
The empirical projection demonstrates that for all observed data configurations, human discrimination/bias parameters fall in the region favoring HCT over advice-taking. The SDT instantiation generalizes to the XAI-as-advisor variant, with no systematic increase in discrimination ability or shift in bias toward greater advice usefulness.
Theoretical Implications and Cost-Benefit Considerations
The advantage of independent aggregation aligns with classic findings in the “wisdom of crowds” and statistical aggregation, in which independence of error is critical to ensemble improvement. Sequential exposure (as in advice paradigms) induces correlated judgment and social influence, leading to suboptimal exploitation of information diversity and increased “herding” and automation bias. The HCT sidesteps these pathologies, making it particularly robust under conditions of miscalibrated or unpredictable advice-taker behavior.
An apparent drawback of the HCT is cost: in up to half of cases, a second human is required to arbitrate. However, the authors emphasize that tiebreakers can be reserved for experts, concentrating resources where they add maximal value without necessitating redundant effort in easier instances, thus optimizing expert labor allocation.
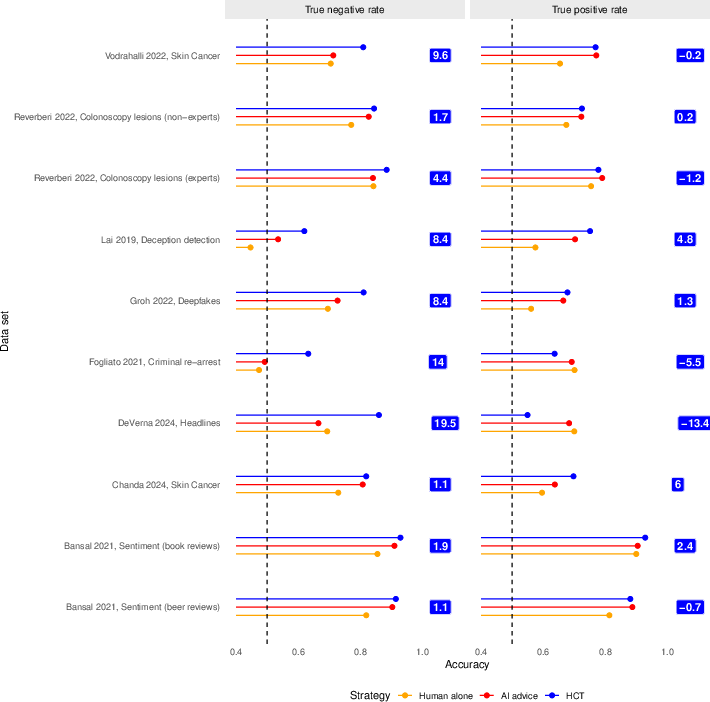
Figure 5: Dataset-wise comparison of true positive/true negative rates, with HCT improvements highlighted.

Figure 6: Relative performance of HCT and human-with-advice protocols against AI alone; positive values indicate the hybrid surpasses either constituent.
Broader Significance and Future Directions
The work has several key ramifications:
- In domains where human–AI complementarity is sought (e.g., clinical decision support, risk assessment), replace sequential advice-taker workflows with aggregation architectures that preserve independence.
- XAI is not, in itself, sufficient to resolve the primary deficit in advice-taker discrimination.
- Future hybrid intelligence research should further explore dynamic allocation of arbitration roles (possibly match tiebreaker to case difficulty or risk), and the integration with algorithmic weighting/selection approaches from crowd wisdom and ensemble prediction literatures.
- Independent aggregation not only optimizes accuracy, but also guards against cognitive deskilling, automation-induced overreliance, and the homogenization of collective outputs, which are rising concerns amidst pervasive LLM deployment.
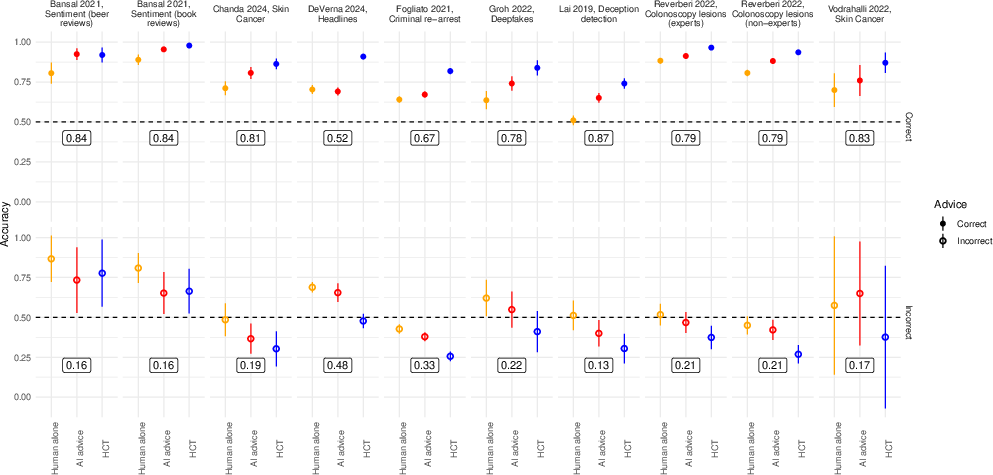
Figure 7: Overall mean accuracy (with CIs) by method, stratified on AI correctness—visualizes tradeoffs when the AI is right versus wrong.
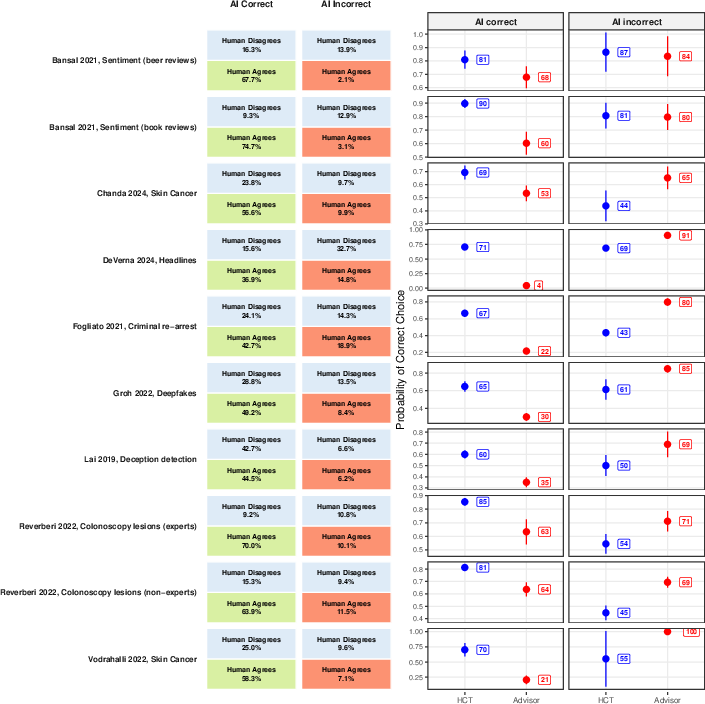
Figure 8: Human-AI (dis)agreement outcomes, showing method-dependent conditional probabilities.
Conclusion
By experimentally and analytically contrasting independent aggregation (HCT) with the AI-as-advisor model, this study identifies the critical limitations of sequential advice-taking due to bounded human discrimination and suboptimal bias settings. Independent judgment preservation confers a systematic, robust accuracy improvement, which persists across tasks, expertise levels, and even in the presence of XAI. These findings provide compelling evidence to restructure human-AI hybrid workflows, especially in high-impact decision-making, toward protocols that institutionalize independence and aggregate via structured arbitration. This paradigm not only enhances accuracy but also maintains the diversity and resilience of human-AI collective intelligence.