- The paper introduces ATP, a novel framework enabling MLLMs to autonomously plan and interleave text with context-relevant images for visual-critical tasks.
- The paper operationalizes ATP-Bench with 7,702 QA pairs, hybrid sourcing of visual assets, and multi-stage human curation to ensure precise tool invocation.
- Experimental findings reveal significant variance in tool coordination, with Gemini 3 Pro excelling while exposing planning deficiencies in complex visual domains.
Motivation and Paradigm Shift
The integration of interleaved text-and-image generation within Multimodal LLMs (MLLMs) has advanced the expressiveness and efficiency in communication for various user-centric tasks. While current frameworks either focus on image generation (via diffusion or autoregressive approaches) or retrieval-augmented mechanisms (citing existing visual assets), they largely treat factuality and creative synthesis as mutually exclusive, failing to address scenarios necessitating seamless orchestration of multiple visual tools within an answer. The ATP-Bench paper introduces Agentic Tool Planning (ATP) as a core competency for next-generation MLLMs, requiring models to decide autonomously when, where, and which set of visual tools to invoke—a paradigm targeting the synthesis of responses that tightly interleave text with context-relevant images for visual-critical queries.
Construction of ATP-Bench
ATP-Bench operationalizes agentic tool planning via a high-coverage benchmark featuring:
- 7,702 QA pairs (1,592 VQA), eight topical categories (Academic, Manual, Recipe, Fashion, Renovation, Product, Travel, Encyclopedia), and 25 fine-grained visual intents.
- Hybrid sourcing: Both reference (in-context) and generative imagery (diffusion, search, edit, code) are systematically integrated, grounding queries in realistic multimodal user scenarios.
The benchmark's data pipeline couples domain-specific document/image curation, automated prompt-driven synthesis of queries and responses (Gemini 2.5 Pro), and rigorous multi-stage human verification—the queries and tool calls are annotated for unambiguity, visual criticality, and placement fidelity.
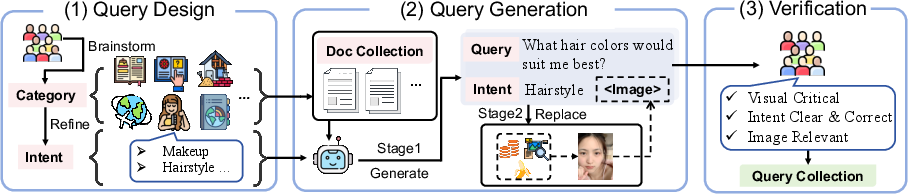


Figure 1: The ATP-Bench query collection pipeline ensures each sample meets visual-criticality and grounding requirements via layered model and manual curation.
Ground truth responses are constructed in three controlled steps: (i) factual textual answer generation, (ii) proactive visual gap identification and tool call insertion with strict criteria for necessity and semantic proximity, (iii) fine-grained human review for parameter accuracy, placement, and tool selection.
ATP-Bench requires models to orchestrate five tool types:
- Reference: Cite existing images from context.
- Diffusion: Generate conceptual or illustrative images.
- Search: Retrieve real-world visuals via engines.
- Edit: Apply localized modifications to existing images.
- Code: Produce data-driven diagrams or visualizations.
Evaluation shifts from traditional reference-matching toward probing the plan quality of tool use. The proposed Multi-Agent MLLM-as-a-Judge (MAM) system utilizes three LLM-based agents:
- Precision Inspector: Assesses each tool-call for necessity, capability boundary, parameterization, and format, scoring failures in appropriateness or execution.
- Recall Inspector: Identifies missed visual opportunities not covered by tool invocations.
- Chief Judge: Synthesizes a holistic 0–100 score based on multi-dimensional performance, robust to ambiguous tool capability boundaries and volatile backend execution.
Experimental Findings
ATP-Bench exposes substantive weaknesses across 10 SOTA MLLMs. The key insights:
- Limited Coherent Planning: Most models exhibit deficiencies in generating interleaved plans, notably in task categories such as Travel and Renovation, where visual grounding is critical and tool coordination is nontrivial.
- Gemini 3 Pro Outperforms Peers: Gemini 3 Pro consistently achieves the highest Final Score (79.88), Success Rate (81.77%), and lowest Missed Images (0.49), particularly excelling in categories with complex tool orchestration.
- Behavioral Variance: Distinct tendencies are observed in tool call frequency and selection. Top-tier models (e.g., Claude Sonnet 4.5, Grok-4.1) employ intermediate call counts, balancing coverage with precision. In contrast, open-source models like LLaMA-3.2-11B either substantially under-call (leading to missed images) or generate malformed tool calls (low success rates).
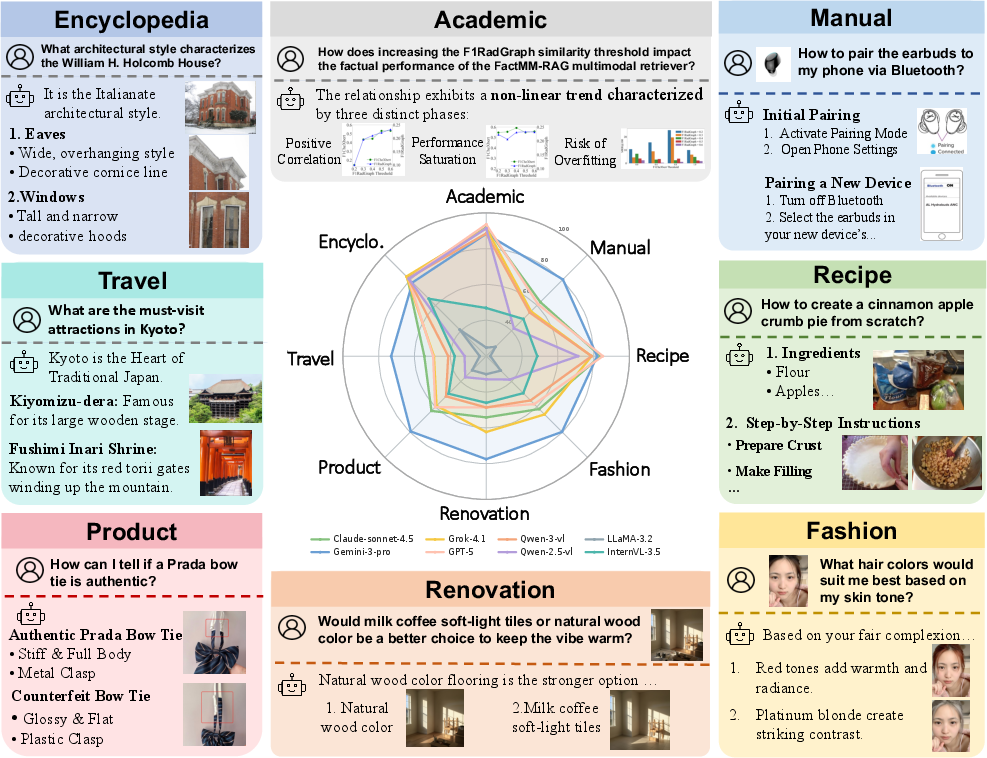
Figure 2: ATP-Bench task categories and examples signal the diversity of visual-critical intents that challenge current MLLMs' planning and integration capabilities.
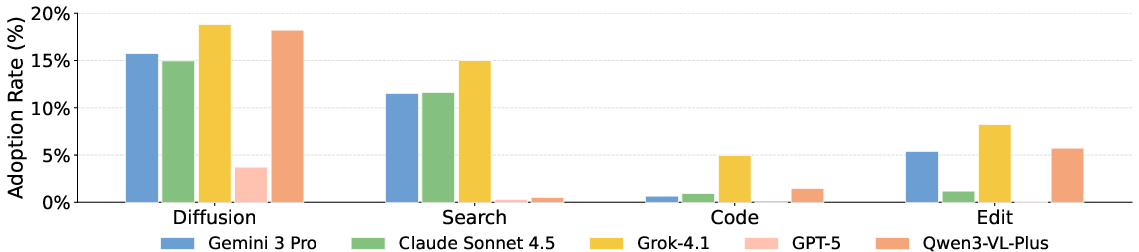
Figure 3: Differential Tool Adoption Rates highlight the variety of generation, search, edit, and code tool usage strategies; reference is omitted due to its near-universal dominance.
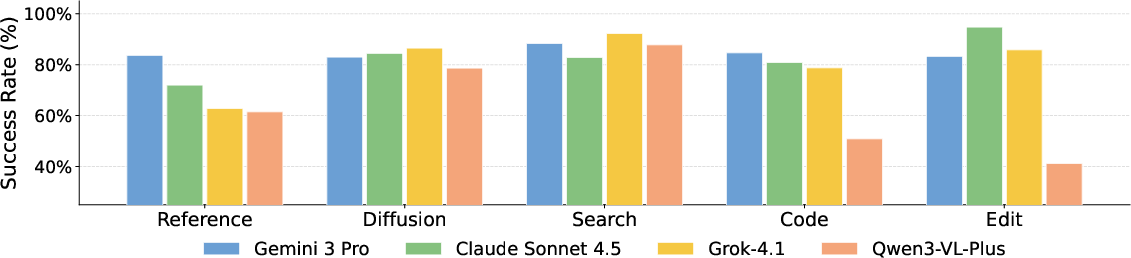
Figure 4: Success Rates per tool and model indicate robust execution for search and diffusion while edit and code see degraded reliability, especially in open-source settings.
Ablations further reveal that in-context few-shot demonstrations materially enhance high-capacity model performance on tool planning and visual coverage, but offer marginal improvement for weaker baselines, underscoring the primacy of underlying instruction-following architecture.
Evaluation robustness is strongly validated, with human-MLLM agreement exceeding 85% for tool necessity/recall and ~89% Spearman correlation between MAM and end-to-end human scores, emphasizing the reliability of the proposed agentic metric.
Theoretical and Practical Implications
ATP-Bench and its MAM evaluation system instantiate a new paradigm for multimodal agent benchmarking, reframing task success from output matching to structural tool orchestration. This approach decouples model planning capability from backend execution, systematically measuring agentic intent, visual necessity reasoning, and proactive multimodal enhancement—the competencies foundational for generalist tool-using agents.
Practically, the benchmark provides actionable diagnostics for model weaknesses: e.g., parameter misalignment (img_index errors), unnecessary/prolific tool calls (semantic vacuity), and tool boundary confusion (diffusion vs. search ambiguity). The behavioral analysis across models, categories, and tools illuminates where new architectural augmentations, pretraining protocols, or prompt strategies are most needed.
The findings indicate that despite overall SOTA multimodal advances, task-optimal agentic tool planning remains a significant open problem—most models struggle on complex interleaved reasoning and miss non-trivial fractions of visual gaps. These results encourage future work in model architecture (structured memory for plan formation, robust format grounding), richer tool libraries (beyond text-image, e.g., audio, video), and advanced meta-cognitive strategies for agentic model supervision.
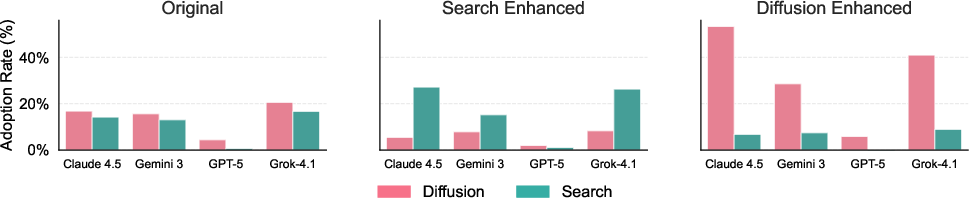
Figure 5: Tool boundary manipulation via prompt enhancement demonstrates the sensitivity of tool selection (e.g., search vs. diffusion) to capability framing, emphasizing the model’s adaptive tool selection based on task context.
Conclusion
ATP-Bench advances the study of multimodal LLMs by crystallizing the challenge of agentic tool planning—unifying retrieval, generation, edit, and code within coherent, visually grounded responses. The combination of a richly annotated benchmark and model-agnostic evaluation provides a rigorous standard for quantifying and dissecting MLLM agentic behavior. The results uncover both significant deficiencies and points of progress, offering a blueprint for future research toward modular, tool-using AI that natively exploits the synergies between factuality and creativity in complex multimodal settings (2603.29902).