- The paper introduces GeoCodeBench, the first benchmark to evaluate execution-based synthesis of PhD-level 3D vision code from research papers.
- It measures both general geometric and research-specific coding capabilities, with top models achieving only around 36.6% pass rate.
- The study identifies critical failure modes such as functional errors and context utilization deficits, highlighting challenges in automated scientific code generation.
Execution-Based Assessment of PhD-Level 3D Vision Coding in LLMs
Introduction
The central objective of "Benchmarking PhD-Level Coding in 3D Geometric Computer Vision" (2603.30038) is to rigorously quantify the ability of state-of-the-art LLMs to synthesize correct, research-grade code in 3D geometric vision directly from scientific context. The study introduces GeoCodeBench, the first comprehensive, execution-based benchmark designed to measure this capability through realistic function implementation tasks sourced from recent top-venue papers. GeoCodeBench operationalizes the paper-to-code mapping challenge, systematically dissecting model competency at both general geometric fundamentals and nuanced research-level algorithm synthesis.
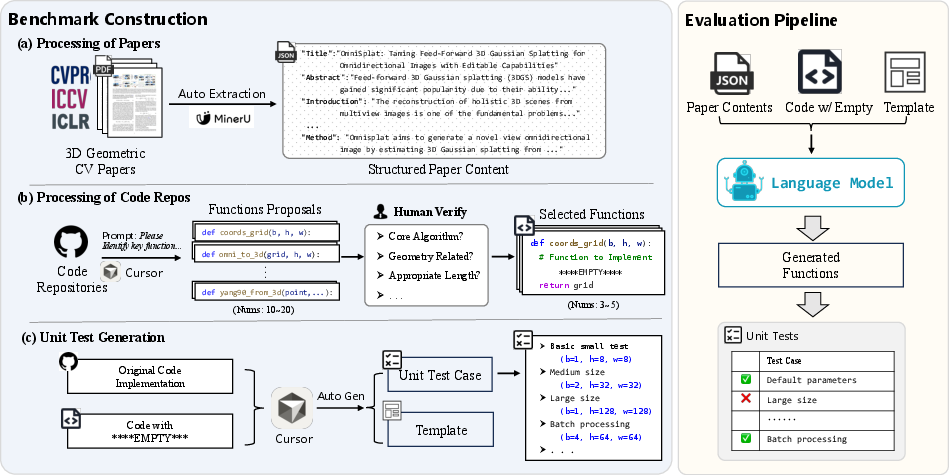
Figure 1: The pipeline underlying GeoCodeBench, from paper and code curation to unit test generation and automatic evaluation.
Benchmark Composition and Methodology
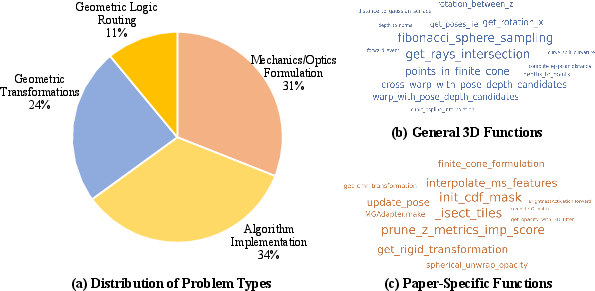
GeoCodeBench consists of 100 fill-in-the-blank function implementation tasks, covering a broad spectrum of the 3D vision domain including Gaussian Splatting, Pose Estimation, SLAM, NeRF, rendering, and physics-based modeling. Each problem instance is constructed by a multi-stage pipeline: paper and repository pair selection from 2025 major conferences (CVPR, ICCV, ICLR) is followed by expert-guided extraction of non-trivial core algorithmic functions. To enforce execution-based criteria, each function is paired with comprehensive unit tests emphasizing geometric edge cases and invariance.
The model input for each benchmark instance includes:
- Structured paper context (as extracted via advanced OCR and section-based parsing),
- Source code with the target function masked,
- A strict code execution template for uniformity.
Pass rates are computed as the average fraction of unit tests successfully passed per task, facilitating unbiased, reproducible scoring.
GeoCodeBench defines a two-level taxonomy:
Comparative Model Evaluation
Eight leading LLMs, spanning both proprietary (e.g., GPT-5, Claude-Sonnet-4.5, Gemini-2.5-Pro) and open-source (Qwen3-Coder-480B, DeepSeek-R1, Llama-3.1-405B-Instruct) paradigms, were evaluated. The analysis yields several instructive findings:
- Maximum Pass Rate: The overall best model, GPT-5, achieves only a 36.6% pass rate, signaling a substantial performance gap with respect to reliable, automation-ready 3D coding.
- Category Disparity: While scores for General 3D Capability peak at ~42.8% for the top model, Research Capability remains notably lower (~29.1%), underlining the complexity of paper-specific procedural synthesis.
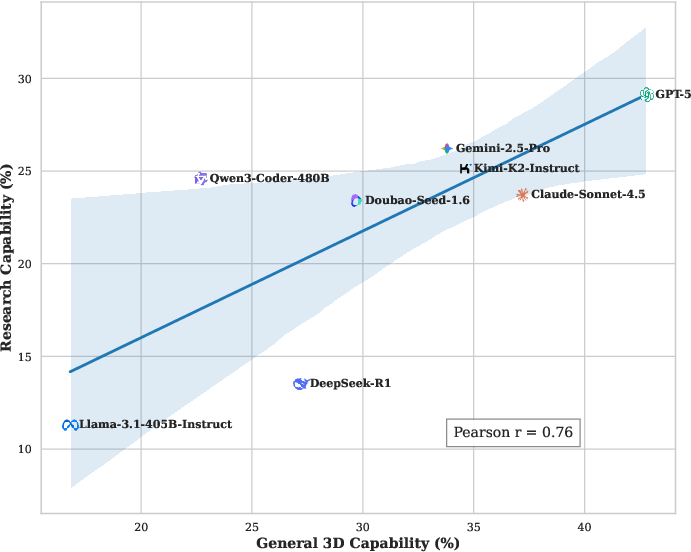
Figure 4: Quantitative comparison of general geometric versus research-specific capability for major LLMs, demonstrating a pervasive gap in advanced implementation performance.
- Creative Correctness: Instances were observed where models generated implementations distinct from the ground-truth, yet still mathematically correct and passing all tests (e.g., solving epipolar distance with different but equivalent formulations).

Figure 5: Case study demonstrating creative correctness—distinct, mathematically equivalent, and validated approaches by different LLMs to the same core function.
- Consistent Failure on Simple Tasks: Even the strongest models were unable to implement extremely simple yet nonstandard functions when the correct behavior was defined procedurally within a research context, signifying brittle transfer from theoretical understanding to domain-specific logic.

Figure 6: Illustration of universal failure among LLMs on a short, conceptually simple event-accumulation function, emphasizing limitations in reliably synthesizing procedural scientific code.
Diagnosis of Failure Modes
GeoCodeBench reveals pervasive and repeatable model failure patterns:
- Functional Errors: Dominant failure mode, comprising incorrect algorithm implementation despite syntactically valid code.
- Shape and Type Mismatches: High frequency of dimension and data structure misunderstandings, crucial for geometric computing.
- Context Utilization Deficit: More paper context (full text) does not uniformly improve model accuracy; method-section-only context often outperforms longer input, especially on research-oriented tasks.
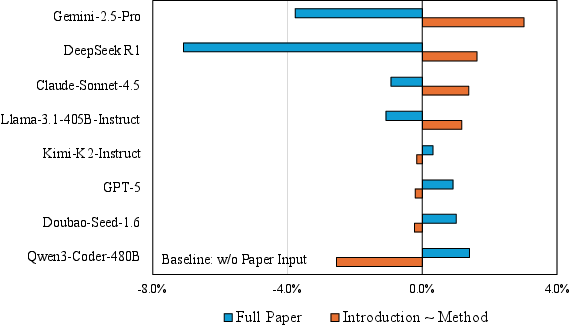
Figure 8: Overall performance as a function of paper length: providing the full paper does not systematically enhance the models' solution correctness relative to concise method-focused context.
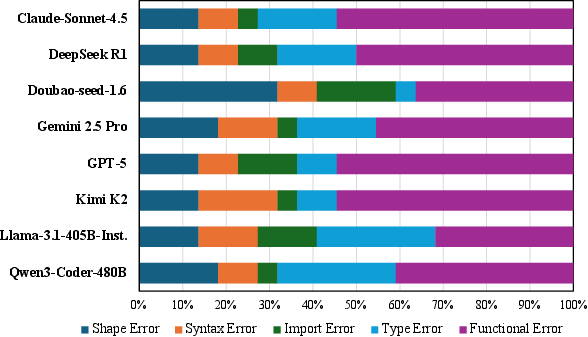
Figure 7: Distribution of prevalent error types in failed solutions across models, underscoring the predominance of functional reasoning failures.
In-Depth Case Studies
GeoCodeBench provides high-resolution analysis of model behavior through targeted case studies:
- Semantics Drift: LLMs default to generic textbook definitions (e.g., Mahalanobis radius for Gaussian surfaces), disregarding subtle but crucial research-specific semantics.
- Representation Inconsistency: When dealing with degenerate geometric cases (e.g., Bezier lines), models often fail to preserve representation invariants critical for downstream processing.
- Interface Misalignment: Notable discrepancies in physical parameter conventions (e.g., GGX BRDF roughness), reflecting difficulty in mapping textual scientific specifications to robust code.
- Area Weighting Loss: LLMs discard area weighting and robustness clauses (e.g., during mesh normal computation), leading to plausible yet regression-inducing code in real pipelines.
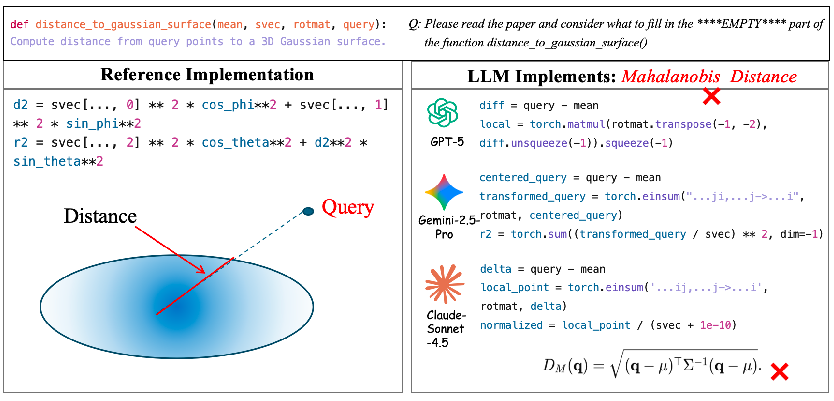
Figure 9: Case where LLMs incorrectly implement a distance metric—choosing the general Mahalanobis approach rather than the physically correct surface distance.

Figure 2: Failure in De Casteljau splitting—LLM misses encoding conventions for straight-line degeneration, resulting in incompatible outputs.
Practical Implications and Future Outlook
GeoCodeBench firmly establishes that current LLMs are not yet dependable for the fully automated synthesis of advanced 3D vision code from scientific papers. The inability to robustly translate high-level geometric descriptions into functionally correct and semantically aligned code imposes clear limits on near-term applicability for autonomous research code generation and scientific agent development.
The critical insights surfaced by GeoCodeBench—especially the execution gap in research-oriented tasks—suggest multiple directions:
- Model Architecture: Bridging symbolic geometric reasoning with procedural program synthesis warrants architectural innovations supporting compositional abstraction and explicit logic routing.
- Training Paradigms: Addressing domain-specific procedural generalization may require targeted curation of long-context scientific datasets and direct optimization for execution-grounded pass rates.
- Benchmark Extension: GeoCodeBench’s scalable construction pipeline allows continuous adaptation, feeding new research trends and providing a longitudinal measure of progress toward credible scientific automation.
Conclusion
GeoCodeBench is the first benchmark to evaluate LLMs’ ability to implement executable, PhD-level 3D geometric computer vision code, directly from research paper context. Its methodology exposes a large, quantifiable gap between general geometric knowledge and robust research algorithm synthesis in state-of-the-art LLMs. The benchmark is both a diagnostic and a catalyst, highlighting the necessity for new model capabilities and research pipelines if trustworthy, automated scientific code generation is to become a reality.
(2603.30038)