- The paper demonstrates that ScaledGD achieves optimal O((n1+n2)r) sample complexity and logarithmic iteration convergence independent of the condition number using a novel decoupling technique.
- The method leverages refined spectral initialization and virtual sequence decoupling to overcome non-convexity limitations in recovering general (non-PSD) low-rank matrices.
- Numerical experiments confirm that ScaledGD outperforms vanilla and Riemannian GD in both iteration count and runtime, especially under ill-conditioning.
Scaled Gradient Descent for Ill-Conditioned Low-Rank Matrix Recovery
Introduction and Problem Setting
The paper "Scaled Gradient Descent for Ill-Conditioned Low-Rank Matrix Recovery with Optimal Sampling Complexity" (2604.00060) provides an in-depth analysis of non-convex optimization for low-rank matrix recovery, targeting fundamental algorithmic limitations encountered in existing methods. The recovery problem is to reconstruct an unknown rank-r matrix X∈Rn1×n2 from m≪n1n2 linear measurements of the form y=A(X). This setting unifies various learning and signal processing tasks, with prior convex and non-convex solutions reaching strong but incomplete theoretical guarantees.
Gradient descent (GD) on a factorized parameterization, X=LR⊤, is computationally appealing but achieves suboptimal sample complexity O((n1+n2)r2) and iteration complexity scaling linearly with the condition number κ of X. Existing preconditioned (scaled) GD methods remedy the condition number dependence in convergence, attaining O(log(1/ϵ)) iteration complexity, but they do not break the suboptimal r2 scaling in sample complexity. Meanwhile, recent advances demonstrate information-theoretic optimal X∈Rn1×n20 sample complexity for GD in the positive semidefinite (PSD) setting, but at the cost of even worse iteration complexity, X∈Rn1×n21, and with limited applicability to general matrices.
Main Theoretical Contributions
The primary contribution of the paper is a rigorous analysis showing that the Scaled Gradient Descent (ScaledGD) algorithm achieves both optimal sample complexity X∈Rn1×n22 and fast, condition-number-independent iteration complexity X∈Rn1×n23 for general (asymmetric and non-PSD) low-rank matrix recovery under Gaussian design. This is enabled by a refined decoupling technique based on virtual sequences, extending and improving on earlier work limited to the PSD case or with higher per-iteration complexity.
Specifically, the authors prove that, with X∈Rn1×n24 Gaussian measurements and suitable spectral initialization, ScaledGD converges as
X∈Rn1×n25
uniformly over all X∈Rn1×n26, with X∈Rn1×n27 absolute constants and step size X∈Rn1×n28 independent of X∈Rn1×n29. The analysis crucially leverages a virtual sequence construction—a family of auxiliary iterates decoupled from the data matrices used in each update—which enables tight operator-norm control and circumvents the traditional limitations of RIP-based bounding in non-convex settings.
This formally establishes that ScaledGD matches the optimal sample complexity of convex (nuclear norm) methods while retaining the computational efficiency and flexibility of factorized non-convex optimization. Unlike prior approaches, the result holds for general low-rank matrices, not just PSD ones, and achieves convergence rates independent of the underlying conditioning.
Numerical Results
The paper presents a series of numerical experiments comparing ScaledGD, vanilla GD, and Riemannian GD (RGD) in both well-conditioned and ill-conditioned regimes. The experiments show that ScaledGD not only achieves faster convergence per iteration but also matches or exceeds the practical efficiency of RGD, while outperforming standard GD as the condition number increases.
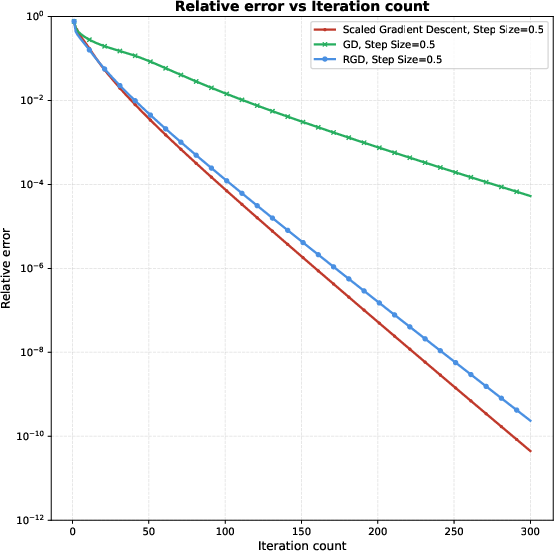
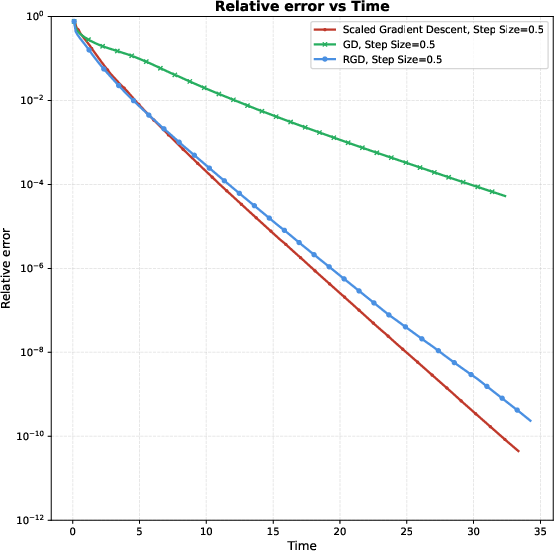
Figure 1: Relative error trajectories for ScaledGD, GD, and RGD versus iteration count (left) and versus runtime (right) for m≪n1n20, m≪n1n21, m≪n1n22, and m≪n1n23.
As visualized above, ScaledGD demonstrates superior convergence profiles, both in iteration-wise and time-wise metrics.
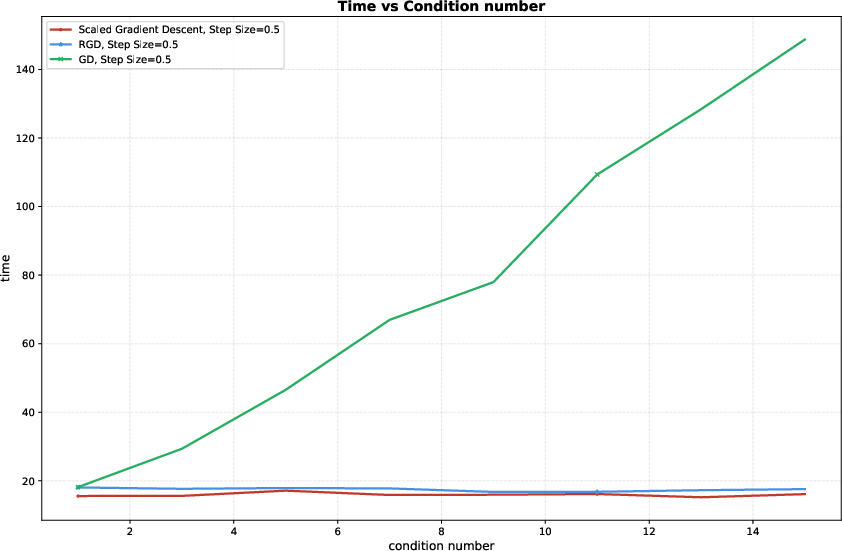
Figure 2: Computational cost of different algorithms under varying condition numbers m≪n1n24; ScaledGD and RGD show stable cost, while GD scales poorly as m≪n1n25 increases.
The robustness of ScaledGD to ill-conditioning is quantitatively established: its runtime to high-accuracy recovery remains nearly flat as m≪n1n26 increases, in stark contrast to the linear increase exhibited by vanilla GD.
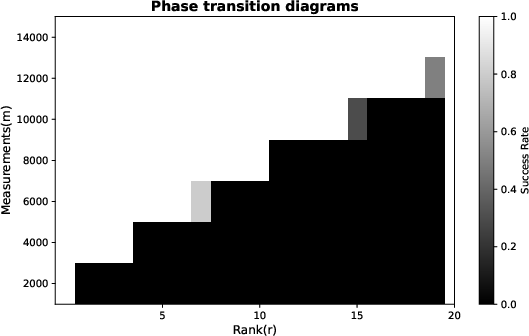
Figure 3: Phase transition diagram over number of measurements m≪n1n27 and target rank m≪n1n28; the linear dependency of the success threshold on m≪n1n29 confirms the theoretically predicted sample complexity.
The phase transition boundary matches the predicted y=A(X)0 dependence, validating the optimality of the proved sample complexity in practice.
Implications, Limitations, and Future Directions
This work decisively addresses two major obstacles in non-convex low-rank matrix recovery: suboptimal sample complexity due to factorization and slow convergence for ill-conditioned solutions. By demonstrating that ScaledGD, coupled with a careful spectral initialization and decoupling argument, simultaneously achieves optimal sample and iteration complexities, it narrows the theoretical gap with convex approaches while remaining computationally scalable.
The result further dismisses the folklore that information-theoretic sample optimality is necessarily accompanied by slower convergence in non-convex regimes. The removal of the PSD restriction expands applicability to a wide class of problems in signal processing, machine learning, and beyond.
However, the analysis retains an explicit y=A(X)1 dependence in the required number of measurements, similar to prior non-convex methods. In contrast, convex optimization can reach sample complexity independent of y=A(X)2. Bridging this remaining gap—potentially via improved initialization or more sophisticated regularization—remains an open avenue. Similarly, adaptation of the proof to random or small-norm initialization (more common in practice), and extension to overparameterized regimes where the search rank exceeds the true rank, present interesting directions for future research.
Conclusion
The paper rigorously establishes that Scaled Gradient Descent achieves both information-theoretic sample optimality and rapid, condition-number-independent convergence for general low-rank matrix recovery under Gaussian measurements. Its analytic innovations—particularly decoupling via virtual sequences—resolve longstanding theoretical limitations in non-convex matrix optimization, as substantiated by numerical experiments confirming both efficiency and robustness to ill-conditioning. The work signals the practical efficiency of scalable non-convex algorithms even at theoretical limits, while motivating further advances to eliminate residual condition number dependence in sampling and explore more general initialization schemes.

