Terminal Agents Suffice for Enterprise Automation
Abstract: There has been growing interest in building agents that can interact with digital platforms to execute meaningful enterprise tasks autonomously. Among the approaches explored are tool-augmented agents built on abstractions such as Model Context Protocol (MCP) and web agents that operate through graphical interfaces. Yet, it remains unclear whether such complex agentic systems are necessary given their cost and operational overhead. We argue that a coding agent equipped only with a terminal and a filesystem can solve many enterprise tasks more effectively by interacting directly with platform APIs. We evaluate this hypothesis across diverse real-world systems and show that these low-level terminal agents match or outperform more complex agent architectures. Our findings suggest that simple programmatic interfaces, combined with strong foundation models, are sufficient for practical enterprise automation.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper asks a simple question: Do we really need complicated AI “agents” that click around websites or use lots of custom tools to automate work at companies, or is a much simpler approach enough? The authors argue that a coding agent that uses only a terminal (a place to type commands) and a filesystem (to save files) can do many real company tasks by talking directly to the software’s APIs—and often do it better, cheaper, and more reliably.
What did the researchers want to find out?
They wanted to test, in plain terms:
- Which is better for automating work in company software: an agent that clicks through web pages like a human, an agent that uses a set of pre-made tools, or a simple coding agent that talks directly to the software’s API?
- Does reading official documentation help the agent?
- Can the agent “learn” over time by saving tips and small scripts it discovers (what they call “skills”)?
How did they test their ideas?
They compared three kinds of agents on real tasks inside three popular kinds of enterprise software:
- ServiceNow (IT helpdesk and workflows)
- GitLab (software development and issues)
- ERPNext (business operations like invoices and orders)
They made the agents solve the same sets of tasks, like finding a record, updating something, or completing a small workflow. Each agent used the same AI “brain” (a LLM) so the only difference was how they interacted:
- Web agent: browses and clicks in a browser like a human.
- Tool-augmented agent: uses a fixed set of pre-built tools (buttons) provided by a framework called MCP.
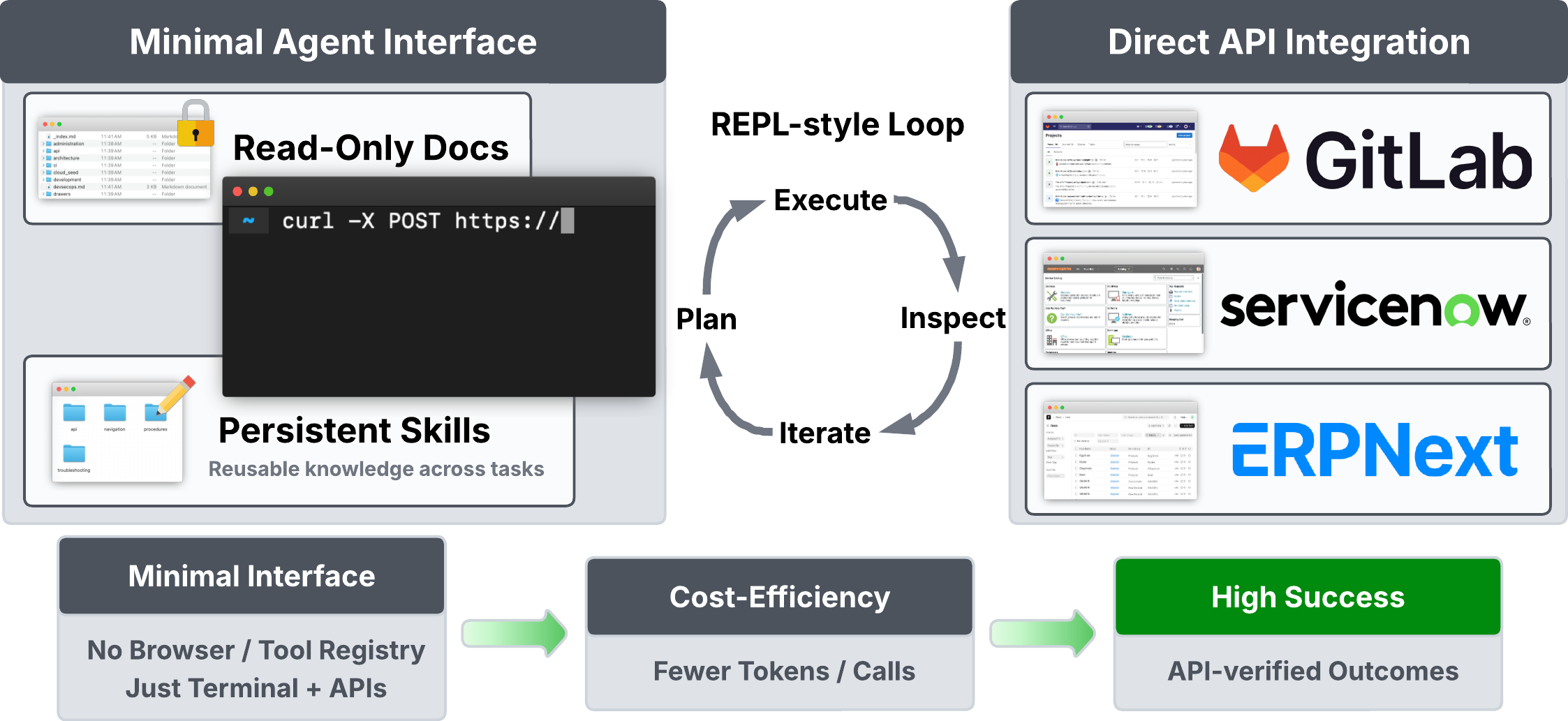
- Terminal agent (their focus): types commands and writes small scripts to talk directly to APIs; it can also save files and read local docs.
They measured:
- Success rate: What percent of tasks did the agent complete correctly?
- Cost: How much AI “thinking” did it use (token cost), which is a good proxy for money and time.
What did they discover?
In short: the simple terminal agent usually matched or beat the others and did it at much lower cost.
Here’s what happened across many tasks and several top AI models:
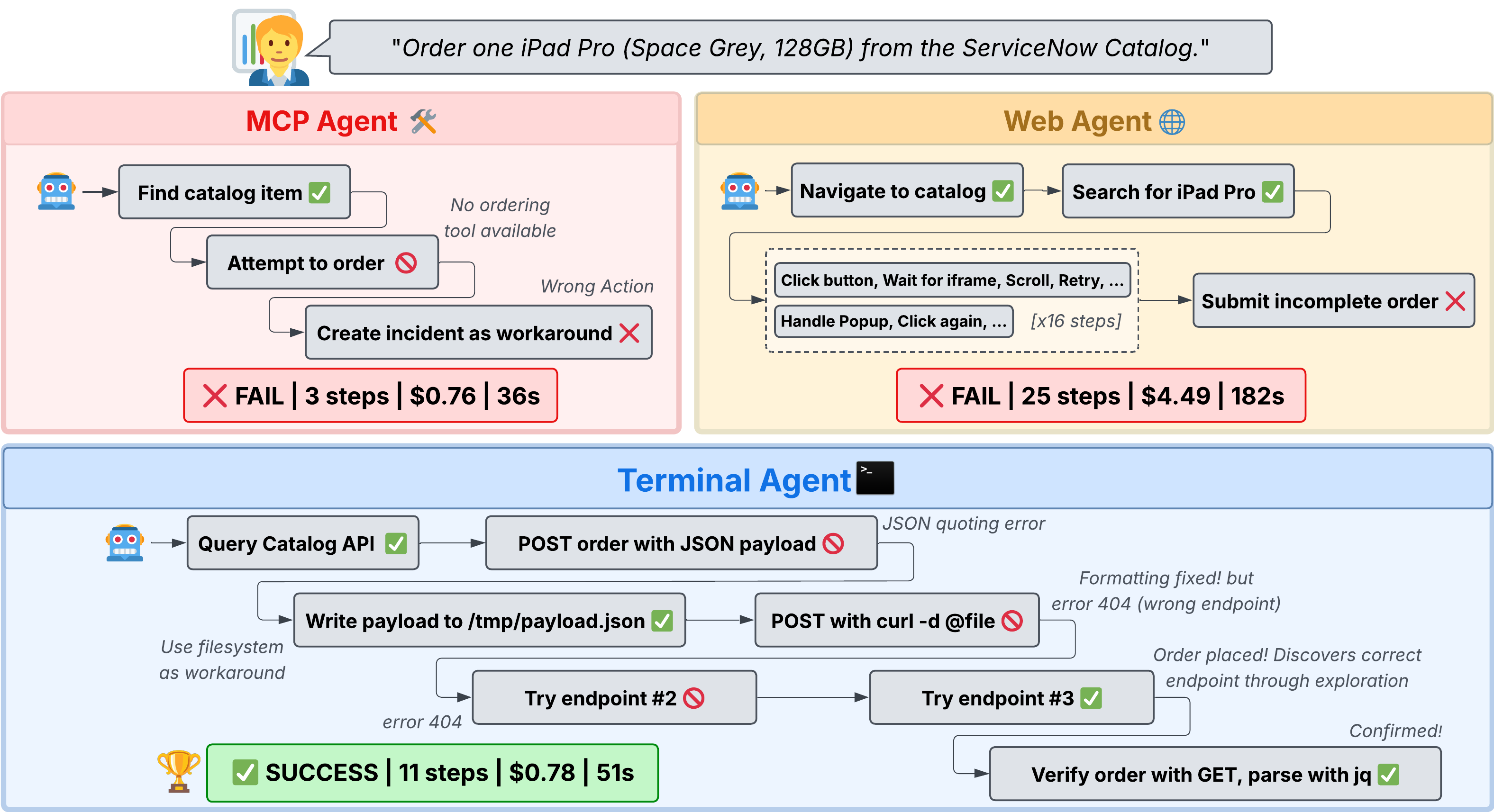
- Tool-augmented agents (pre-made tools) struggled most. They were cheap to run but had the lowest success. Reason: the tools didn’t cover everything real tasks needed, or were too rigid.
- Web agents (clicking through the UI) often did well, but were expensive. They had to process lots of screen and page information, which drove up cost.
- Terminal agents (typing commands and calling APIs) hit the sweet spot. They:
- Matched or outperformed web agents in many cases
- Cost far less per task (often 5–9× cheaper)
- Were flexible, because they weren’t limited by fixed tools and didn’t pay the “overhead” of browsing
They also tested two add-ons for the terminal agent:
- Access to documentation: Reading official docs didn’t always help. On some platforms it helped a bit; on others it slowed the agent down because the docs weren’t organized in the way agents need (more like a giant reference than a task guide).
- “Skills” memory: Letting the agent save useful tips and scripts as it worked boosted success and cut cost over time—especially on less familiar platforms. Think of it like the agent keeping a personal notebook of tricks that it reuses later.
Why does this matter?
Companies want AI agents that can safely and reliably do work inside important systems without constant hand-holding. This paper shows:
- You don’t always need a complex setup. If the software has good APIs, a simple terminal-based coding agent can handle many tasks well.
- Less can be more. Fewer layers (no fragile UI clicking, no limited tool menus) can mean better performance and lower cost.
- Documentation should be agent-friendly. Manuals that are organized around real tasks (not just long reference pages) help more.
- Letting agents build their own “playbook” (skills) makes them better and cheaper over time.
What are the limits and future ideas?
The terminal agent isn’t perfect:
- Some actions only work in a web browser (like certain user impersonations or drag-and-drop builders).
- Some tasks involve reading things that only appear in the visual UI (like a chart’s labels or exact formatting).
A promising direction is a hybrid approach: use direct API calls when possible (fast and flexible), and switch to the browser only when needed.
The big takeaway
When enterprise software provides solid APIs, a simple coding agent that lives in the terminal—paired with a filesystem to save notes and scripts—can automate a lot of real work. It often matches or beats more complicated approaches, and costs much less. That means the best path to reliable, affordable automation may be simpler than many people think.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper. Each item is phrased to suggest actionable next steps for future research.
- Benchmark representativeness: Quantify how task selection favors API-amenable workflows; add a controlled subset where critical steps are UI-only (e.g., impersonation flows, drag‑and‑drop editors) to measure selection bias.
- Coverage of enterprise verticals: Extend beyond ServiceNow, GitLab, ERPNext to HRIS (e.g., Workday), IAM, finance (e.g., SAP/Oracle), security (e.g., SIEM/SOAR) to test cross-vertical generality.
- Long-horizon, cross-system automations: Evaluate multi-stage workflows spanning multiple platforms, approvals, SLAs, and time delays (e.g., overnight batch jobs), including state persistence and resumption.
- RBAC and organizational constraints: Systematically vary roles, permissions, and approval gates to assess agent reliability under least privilege and constrained entitlements.
- UI-only capability gap: Quantify frequency and impact of tasks that require browser session state or complex UI interactions (charts, WYSIWYG/flow designers); report failure rates and workarounds for terminal agents.
- Hybrid routing policies: Develop and evaluate learned or rule-based policies that route subtasks between API and GUI modes, with cost/latency-aware switching and confidence thresholds.
- Robustness to API evolution: Measure degradation and recovery when endpoints, schemas, or auth flows change (version bumps, deprecations); test automatic adaptation using docs, error probing, and schema discovery.
- Authentication complexity: Assess terminal-agent viability under OAuth2/OIDC, SSO, MFA, short-lived tokens, cookie-bound sessions, and device flow constraints common in enterprise deployments.
- Network and platform variability: Stress-test under rate limits, throttling, transient failures, pagination quirks, and eventual consistency; evaluate retry/backoff strategies and idempotency safeguards.
- Safety and harmful-action tests: Introduce adversarial tasks (e.g., mass deletions, PII exfiltration) with defense layers (RBAC, policy checks, dry-run/approval) to quantify risk and mitigation efficacy.
- Side-effects and rollback: Go beyond binary success to detect unintended changes, verify idempotency, and test transactionality/rollback (e.g., two-phase commit patterns or compensating actions).
- Cost and efficiency realism: Incorporate API latency, tool execution time, infrastructure compute, and platform licensing into a total cost of ownership analysis, not just token costs.
- Reproducibility and variance: Report multi-seed runs, run-to-run variance, and statistical significance for all paradigms; include sensitivity to decoding parameters and tool nondeterminism.
- Fairness of MCP baseline: Compare against enhanced MCP registries with broader coverage, compositional tools, and learned argument schemas; quantify gains from realistic tool engineering.
- Strength of web-agent baselines: Evaluate stronger GUI agents (e.g., multimodal VLMs with dense DOM grounding, memory, better planning) to ensure fair comparisons.
- Terminal environment constraints: Test under enterprise-like shells (restricted syscalls, egress proxies, certificate pinning), and measure impacts of quoting, sandboxing, and CIS hardening.
- Documentation grounding design: Systematically vary RAG pipelines (chunking, retrieval, summarization) and document structure; test authoring guidelines that make docs agent-friendly vs user-oriented.
- API discovery without docs: Evaluate schema introspection, hypermedia-driven navigation, and self-probing for unknown fields/endpoints; benchmark performance when docs are incomplete or stale.
- Memory/skills governance: Study security, provenance, versioning, validation, and revocation of self-generated skills; assess risks of stale or harmful procedures being reused.
- Skill generalization and sharing: Measure cross-task/platform transfer of skills, the benefits/risks of organization-wide skill repositories, and mechanisms for de-duplication and quality control.
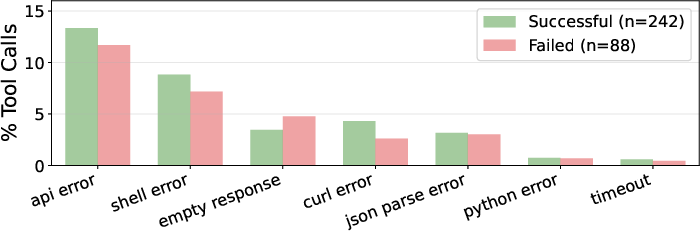
- Failure taxonomy at scale: Provide a comprehensive, cross-platform error taxonomy (beyond one model on one platform), with proportions and targeted fixes for each failure mode.
- Human-in-the-loop workflows: Evaluate approval gating, selective confirmation, and exception handling; measure how minimal human oversight affects safety, success, and cost.
- Async and event-driven tasks: Include tasks requiring scheduled jobs, webhooks, or long-running processes; assess monitoring, callback handling, and timeout/retry logic.
- Non-API or low-API platforms: Test the approach on systems with weak/closed APIs where GUI/RPA is dominant; quantify how much GUI fallback is needed for practical coverage.
- Security adversaries: Red-team against prompt injection via API data, command/JSON injection, SSRF in curl usage, and data-leak channels; evaluate mitigations (sanitization, allowlists).
- Data privacy and compliance: Assess handling of PII/PHI, audit logging, and regulatory constraints (e.g., SOX/GDPR); measure auditability of actions taken by terminal agents.
- Decision criteria for modality choice: Formalize when “terminal suffices” vs “GUI required” based on task features (auth, UI semantics, aggregation fidelity); derive predictive routing heuristics.
- Comparative agent baselines: Include open-source coding agents (e.g., SWE-agent/OpenHands variants), and state-of-the-art tool-use frameworks to strengthen external validity.
- Localization and i18n: Evaluate agents on non-English UIs/docs and localized field labels; test robustness to region-specific formats and encodings.
- Dataset and environment release: Ensure full public release and independent replication; include exact platform versions, seeds, and container configs to validate claims.
- Economic impact estimates: Model ROI versus human baselines, including setup/maintenance costs for skills, docs pipelines, and security controls in enterprise settings.
- Maintainability under UI/API drift: Measure effort to maintain web vs terminal vs MCP agents over time as platforms evolve (e.g., breakage frequency, repair time).
- Ethical deployment playbooks: Translate the high-level safety discussion into concrete deployment patterns (permissions, policy layers, monitoring, incident response) and benchmark their overhead.
Practical Applications
Below is an overview of practical, real-world applications enabled by the paper’s findings that terminal-based, API-first coding agents (e.g., StarShell) can match or outperform more complex agent stacks for enterprise automation at a fraction of the cost. Applications are grouped into those deployable today versus those requiring further development or scaling.
Immediate Applications
The following applications can be piloted or deployed now, contingent on stable APIs, appropriate permissions, and standard enterprise controls.
- Enterprise ITSM automation via APIs (e.g., ServiceNow)
- Sectors: IT operations, customer support
- Potential tools/products/workflows: StarShell-like “Agent CLI” for incident triage, catalog order automation, bulk updates (e.g., state/priority), approvals, and reporting; Slack/Teams ChatOps integration to trigger API actions; scheduled jobs for clean-up and governance tasks
- Assumptions/dependencies: Stable REST APIs and RBAC; audit logging; sandbox environments for testing; human-in-the-loop for high-risk changes
- DevOps/SDLC task automation (e.g., GitLab)
- Sectors: Software engineering, DevOps
- Potential tools/products/workflows: Agent-driven repo provisioning, branch protection updates, merge request triage/labeling, pipeline re-runs, environment cleanups; “DevOps Assistant” that operates via GitLab/GitHub APIs; integration with existing ChatOps
- Assumptions/dependencies: API tokens and permissions; rate-limit handling; secure secret management; change approval workflows
- ERP operations automation (e.g., ERPNext)
- Sectors: Manufacturing, retail, finance back office
- Potential tools/products/workflows: Automated invoice creation, purchase orders, inventory adjustments, vendor/customer master updates; “ERP CLI Agent” with reusable API recipes (“skills”) for key document types
- Assumptions/dependencies: Clear mapping between business fields and API fields; consistent doctype schemas; verification against accounting and compliance policies
- API-first RPA alternative for brittle GUI bots
- Sectors: Shared services, BPO, IT
- Potential tools/products/workflows: Replace GUI screen-scraping bots with API-centric automations for tasks with solid API coverage; “API-first RPA” portfolio for cost and reliability gains
- Assumptions/dependencies: Adequate API surface for target tasks; exceptions when tasks require UI-only state; change-management for bot migration
- Runbook-to-skill conversion and internal skills libraries
- Sectors: IT operations, SRE
- Potential tools/products/workflows: Agents persist verified, reusable “skills” (API recipes, pitfalls, field mappings) that can be recalled across tasks; internal skills registries with versioning to accelerate future automations
- Assumptions/dependencies: Knowledge management processes; skills curation and de-duplication; governance for sharing and approval
- Cost-optimized agent deployments that minimize doc-dependency
- Sectors: Any enterprise with common SaaS platforms
- Potential tools/products/workflows: Configure agents to operate efficiently without documentation retrieval on well-known platforms to reduce token cost; selective doc access for less common systems
- Assumptions/dependencies: Strong parametric knowledge in the chosen model; monitoring to ensure no accuracy regressions
- Audit-friendly, programmatic automations
- Sectors: Finance, healthcare, public sector
- Potential tools/products/workflows: Agents that interact via APIs produce structured logs; verification hooks for state changes; policy-based approvals; integration with SIEM/GRC
- Assumptions/dependencies: Access to platform audit logs and event streams; clear segregation of duties; approval policies codified as guardrails
- Academic benchmarking and evaluation harness
- Sectors: Academia, industrial research
- Potential tools/products/workflows: Use containerized environments and programmatic verification to benchmark agent paradigms; evaluate cost-performance tradeoffs under identical backbones
- Assumptions/dependencies: Environment setup and maintenance; standardized scoring; reproducibility protocols
- ChatOps assistants for routine SaaS actions
- Sectors: Cross-industry
- Potential tools/products/workflows: Slack/Teams bots that accept natural language and execute API calls (e.g., “Create a P1 incident,” “Re-run CI on project X,” “Create PO for vendor Y”)
- Assumptions/dependencies: Role-based permissions; rate limits; approval steps for sensitive actions
- Procurement and platform-choice guidance (API-first)
- Sectors: Enterprise IT, procurement
- Potential tools/products/workflows: Introduce an “API sufficiency checklist” in software selection; pilot with platforms known to have strong APIs to unlock immediate automation value
- Assumptions/dependencies: Vendor cooperation; internal policy updates; alignment with security teams
- Power-user personal SaaS automations
- Sectors: Daily life, SMBs
- Potential tools/products/workflows: Local terminal agents for personal GitHub/Notion/Trello/Google Workspace tasks (e.g., issue triage, calendar ops, doc updates)
- Assumptions/dependencies: API keys and scopes; careful handling of personal data; throttling awareness
Long-Term Applications
These opportunities benefit from further research, scaling, hybridization, or organizational change management.
- Hybrid API + GUI agents for UI-only tasks
- Sectors: Enterprise software, RPA
- Potential tools/products/workflows: Orchestrators that prefer APIs but gracefully fall back to browser control for operations requiring session/cookies, rendered charts, or drag-and-drop editors
- Assumptions/dependencies: Reliable browser automation; secure SSO/session handling; decision policies for when to switch modalities
- Cross-platform, long-horizon enterprise agents
- Sectors: IT operations, HR, finance, security
- Potential tools/products/workflows: End-to-end workflows spanning multiple systems (e.g., joiner–mover–leaver across HRIS, ITSM, IAM; incident-to-change-to-deployment across ServiceNow/GitLab/cloud)
- Assumptions/dependencies: Identity federation and least-privilege access; robust state management; approvals and audit
- Organization-wide “skills marketplaces” for agents
- Sectors: Consulting, large enterprises
- Potential tools/products/workflows: Versioned, signed, and verified skill libraries that teams can reuse; curation, ranking, and provenance tracking; internal app-store model
- Assumptions/dependencies: Governance and trust frameworks; compatibility with different platforms; process for deprecating stale skills
- API quality standards and scoring for agent readiness
- Sectors: Policy, procurement, software vendors
- Potential tools/products/workflows: Industry or government standards for API stability, completeness, and documentation clarity; “Agent-Readiness Score” used in RFPs
- Assumptions/dependencies: Vendor and buyer adoption; standardization bodies; alignment with security and privacy regulations
- Safety and policy enforcement layers for autonomous agents
- Sectors: Regulated industries (healthcare, finance, public sector)
- Potential tools/products/workflows: Policy-as-code engines; multi-step approvals; anomaly detection; agent-in-the-loop guardrails for consequential changes
- Assumptions/dependencies: Platform APIs that expose pre-commit checks; robust auditability; threat modeling for agent actions
- Domain-specific vertical agents
- Sectors: Healthcare, finance, energy, education
- Potential tools/products/workflows:
- Healthcare: FHIR-based EHR automations (order sets, scheduling, population health reports)
- Finance: Post-trade reconciliations, treasury ops, ledger upkeep via APIs
- Energy: Asset/CMMS updates, work orders in maintenance platforms
- Education: SIS/LMS integrations for roster updates, grading pipelines
- Assumptions/dependencies: Mature domain APIs; compliance (HIPAA, SOX, GDPR, FERPA); data governance and PHI/PII protections
- Training and fine-tuning with agent traces
- Sectors: Academia, AI product teams
- Potential tools/products/workflows: Use command–observation–result traces to fine-tune models for better API calling, error recovery, and shell-quoting robustness
- Assumptions/dependencies: Data rights and privacy; robust labeling; generalization beyond specific platforms
- RPA migration programs at enterprise scale
- Sectors: Shared services, BPO
- Potential tools/products/workflows: Systematic replacement of brittle GUI bots with API-first agents; migration factories with ROI calculators and regression tests
- Assumptions/dependencies: Adequate API coverage; strong change-management; fallback strategies for UI-only gaps
- On-prem/edge agents for sensitive environments
- Sectors: Defense, finance, healthcare
- Potential tools/products/workflows: Agents running in secure enclaves or VPCs with sealed secrets and attestation; local LLMs for data residency
- Assumptions/dependencies: Model availability/licensing; hardware and latency constraints; MLOps for secure updates
- Agent reliability research and products
- Sectors: AI platforms, developer tooling
- Potential tools/products/workflows: Libraries that auto-harden API calls (retry, backoff, schema probing), solve shell quoting/JSON issues by construction, and standardize verification hooks
- Assumptions/dependencies: Broad community adoption; benchmarks to measure reliability improvements
- Government/enterprise policy emphasizing API-first digital services
- Sectors: Public sector, enterprise IT governance
- Potential tools/products/workflows: Policies that require machine-consumable APIs for new systems; incentives for retrofitting legacy services with APIs to enable automation and accessibility
- Assumptions/dependencies: Budget and timeline for modernization; coexistence plans for legacy UI flows
These applications leverage the paper’s core insight: when stable, expressive APIs are available, minimal terminal-based coding agents can deliver high success rates at significantly lower cost than GUI agents, while avoiding the rigidity of curated tool registries. Feasibility hinges on API availability and quality, robust permissions and audit, and organizational readiness for API-first automation.
Glossary
- accessibility trees: Structured representations of UI elements used by assistive technologies; in agents, processing these trees increases perceptual overhead. "processing large accessibility trees and screenshots"
- API-first: An approach prioritizing direct interaction with application programming interfaces over GUI manipulation. "API-first and coding-agent approaches."
- brittle action chains: Long sequences of UI actions that are fragile and prone to breaking when interfaces change. "long, brittle action chains that are sensitive to interface changes"
- containerized instances: Isolated, reproducible runtime environments packaged as containers for deployment and evaluation. "All environments are deployed in containerized instances."
- CRUD operations: Create, Read, Update, Delete actions that define basic data manipulation in APIs or databases. "generic CRUD operations over all document types"
- curated action schemas: Predefined structured specifications that constrain how models may invoke tools or operations. "curated action schemas through frameworks like Model Context Protocol (MCP)"
- curated tool registries: Catalogs of pre-approved tools/endpoints that agents can invoke, often limiting expressivity. "curated tool registries simplify invocation at the cost of restricting expressivity"
- documentation corpus: A collected, locally accessible body of official docs for retrieval by agents during tasks. "a local documentation corpus accessible through the filesystem"
- doctype: A document type identifier used by platforms like ERP systems to classify records/entities. "non-obvious doctype names"
- DOM elements: Nodes in the Document Object Model representing parts of a web page that agents can click or inspect. "issuing low-level actions over DOM elements and screenshots"
- Flow Designer: A graphical workflow builder (e.g., in ServiceNow) for composing automations via UI rather than public APIs. "through standard UI interactions in Flow Designer."
- foundation models: Large pre-trained models serving as general-purpose backbones for downstream tasks. "simple programmatic interfaces, combined with strong foundation models"
- frontier LLMs: The latest, most capable LLMs at the cutting edge of capability. "We evaluate multiple frontier LLM backbones"
- generalist code agents: Agents that solve diverse tasks by writing and executing code directly, without heavy tool curation. "Recent generalist code agents such as Claude Code and OpenClaw"
- GUI-driven agents: Agents that operate via the graphical user interface, simulating human browsing and clicking. "GUI-driven agents operate through web interfaces"
- hybrid agent: An agent that combines multiple interaction modes (e.g., APIs and browsing) to handle diverse subtasks. "We explore this approach with a hybrid agent in Appendix~\ref{sec:hybrid}."
- iframe-based UI: A web interface constructed with embedded frames, often complicating DOM-based navigation for agents. "becomes confused within the iframe-based UI"
- impersonation: A feature allowing an administrator to act as another user within a platform, often tied to browser session state. "ServiceNow's impersonation feature"
- LLM backbone: The underlying LLM powering an agent, shared across different agent interaction paradigms. "All agents use the same LLM backbone"
- MCP server: A server implementing the Model Context Protocol, exposing tools/actions that an agent can call. "web agents operate through the official Playwright MCP server"
- Model Context Protocol (MCP): A framework that standardizes tool exposure so models can invoke predefined operations. "Model Context Protocol (MCP)"
- OpenAI Agents SDK: A software development kit used to build and run the agent implementations in the experiments. "All agents are implemented using the OpenAI Agents SDK"
- parametric knowledge: Information encoded within a model’s learned parameters, as opposed to retrieved from external sources. "rely on their parametric knowledge"
- Playwright: A browser automation framework used here via an MCP server to provide web interaction capabilities. "Playwright MCP server"
- programmatic verification: Automated checking of task success by inspecting the live system state via APIs, rather than UI scripts. "programmatic verification against the live platform"
- REPL-style loop: An iterative cycle of reasoning, executing code/commands, and inspecting outputs to guide next steps. "REPL-style loop of reasoning, execution, and environment inspection"
- role-based access: A security model where permissions are granted based on a user’s role within an organization. "permissions, role-based access, or auditing"
- sample-proportion estimator: A statistical formula for estimating the standard error of a binary success rate. "we estimate standard errors for SR using the sample-proportion estimator"
- sandboxed environment: A restricted execution context that isolates the agent’s actions and filesystem from external systems. "Terminal agents operate in a sandboxed environment with terminal and filesystem access."
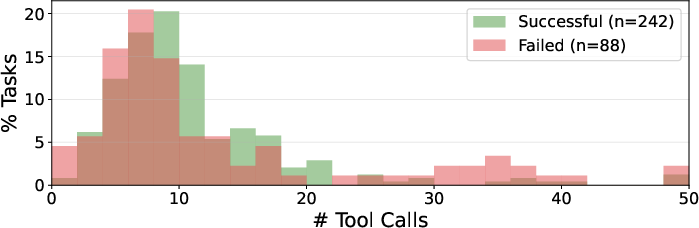
- success rate (SR): The primary metric measuring the percentage of tasks completed successfully. "Our primary metric is success rate (SR)"
- token usage: The number of input/output tokens consumed by the model, used here to estimate inference cost. "computed from the token usage of the underlying LLM."
- wall-clock time: Real elapsed time to complete tasks, influenced by infrastructure and environment latencies. "wall-clock time depends on environment and infrastructure latency."
- web agents: Agents that interact with systems through a browser, observing pages and taking UI actions. "Web agents operate through graphical interfaces"
Collections
Sign up for free to add this paper to one or more collections.