- The paper finds that AI agents generate predominantly beginner-level (A1/A2) code, with over 90% of constructs falling in this range.
- It employs a large-scale CEFR-based pycefr analysis on 591 PRs to systematically compare AI-generated and human-authored Python code.
- The study reveals that complex, advanced constructs arise mainly in feature addition and bug fix tasks, suggesting targeted review strategies.
Assessing Python Code Proficiency in AI Agent-Generated Code
Introduction
The adoption of AI-based code generation agents (e.g., GitHub Copilot, Cursor, Devin) is transforming core workflows in contemporary software engineering, shifting the developer's function toward code review and maintenance. Despite the high throughput of AI code generation observed in real-world development (e.g., over 400,000 PRs by Codex in <2 months), there has been limited empirical assessment of the linguistic and structural complexity of generated code. This study conducts a large-scale analysis of Python code generated by AI agents, employing the pycefr tool to systematically classify code constructs according to the CEFR-inspired six-level proficiency schema (A1 to C2). The central objectives are to quantify the proficiency profile of generated code, compare AI-generated code to human-authored code, and identify PR task types driving the production of advanced code constructs.
Proficiency Profiling with CEFR and Pycefr
The analytical framework is built on the Common European Framework of Reference for Languages (CEFR), which segments language proficiency into six progressive levels (A1, A2, B1, B2, C1, C2). The pycefr static analysis tool extends this taxonomy to Python code by mapping language constructs (e.g., list comprehensions, generator expressions, decorators) to these levels, thereby estimating the implicit proficiency required for comprehension and maintenance.
The dataset is curated from the AIDev corpus, filtering to 591 PRs from 145 starred Python repositories linked to AI agent authorship. The extraction pipeline reconstructs both human and AI-generated code diffs to isolate newly introduced code, ensuring analytic granularity at the construct level for reliable proficiency assessment.
Figure 1: Study overview illustrating data curation, code extraction, and pycefr-based proficiency analysis pipelines.
Distribution of Proficiency Levels in AI-Generated Code
The dominant finding is that AI agents overwhelmingly generate code at the lower proficiency spectrum. Specifically, over 90% of code constructs are classified as A1 (Breakthrough) or A2 (Waystage), with less than 1% at C2 (Mastery). Intermediate-level (B1/B2) and advanced (C1/C2) constructs are rare across all agents, with C1 peaking at 1.18% (Copilot) and C2 never exceeding 0.44% for any agent. Statistical analysis indicates that, although intra-agent differences in proficiency distributions are significant, their effect size is negligible.
These results establish that current-generation AI agents align generated code toward the linguistic/construct complexity accessible to developers with only basic Python proficiency.
Comparative Analysis of AI versus Human-Authored Code
Upon controlling for repository and project alignment, human-written and agent-generated code exhibit broadly similar proficiency distributions. Both predominantly employ A1 and A2 level constructs, with intermediate and proficient features comprising less than 10%. Notably, AI agents produce marginally more C1 code (1.12% versus 0.85%), while humans introduce slightly more C2 constructs (0.57% versus 0.42%). Both differences are statistically significant yet have minimal effect sizes; hence, in operational terms, the review and maintenance burden for AI-generated code mirrors the landscape faced when dealing with human-written code at scale.
PR Task Typology and Emergence of High-Proficiency Code
Analysis of outlier PRs—those containing abnormally high numbers of C1 or C2 constructs—reveals a strong association with feature additions and bug fixes. Feature addition PRs account for the bulk of high-proficiency code, while build and chore tasks exhibit the highest average advanced construct counts per PR. Refactoring and performance tasks, although less frequent, also contribute to the advanced code footprint.
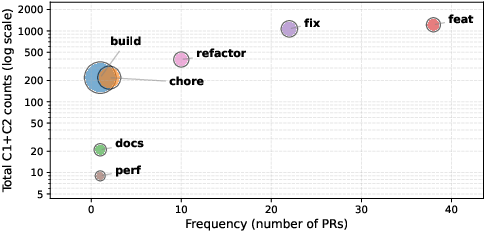
Figure 2: Task distribution among outlier agent PRs with extreme counts of proficient code (log-scaled C1 + C2 occurrences).
This pattern suggests that AI agents will produce complex, high-proficiency code primarily under tasks demanding substantial structural or behavioral extension.
Representative Example of Complex AI-Generated Constructs
A concrete instance is provided by a code edit in the "AGI-Alpha-Agent-v0" repository, where an AI agent introduces a nested list comprehension with an in-line conditional (see below). This idiom is concise but considered a barrier to comprehension for less proficient Python developers due to its compactness and syntactic density.

Figure 3: AI agent code change deploying a list comprehension with an inline if clause.
Such constructs, while idiomatic, increase the necessary review proficiency and may impede onboarding or maintenance efforts unless reviewers possess commensurate expertise.
Implications and Future Directions
These findings demonstrate that, while generator agents predominantly produce code tractable to programmers with elementary Python proficiency, specific PRs—especially those associated with new features or complex patches—may necessitate advanced review skills. From a process management perspective, PR triage and code review assignment may warrant explicit stratification based on measured code proficiency to ensure match between code complexity and reviewer skill sets.
On the research front, these results motivate further inquiry into the impact of code proficiency on review outcomes, defect rates, and project maintainability in AI-augmented workflows. Investigation into agent prompting languages, fine-tuning for coherent code proficiency, and task-specific code complexity profiling are also logical continuations.
Conclusion
Systematic analysis of AI-generated Python code in open-source PRs indicates strong predominance of beginner and elementary-level constructs, yielding a maintenance scenario comparable to human-origin code. However, advanced constructs emerge in the context of complex tasks, suggesting the need for enhanced review practices and targeted upskilling. The proficiency-aware assessment mechanic outlined here represents a robust baseline for future empirical and tool-based research into the intersection of AI agent coding and collaborative software development.

