- The paper introduces CASA—a two-stage framework that integrates token-level safety prediction to robustly block adversarial multimodal queries.
- It leverages a safety attention module to scale logits using internal representations, reducing attack success rates by over 97% across benchmarks.
- CASA maintains or enhances output utility on benign queries, outperforming traditional SSFT by decoupling safety detection from response generation.
Robust Multimodal Safety via Conditional Decoding: Detailed Technical Analysis
Motivation and Problem Framing
The proliferation of Multimodal LLMs (MLLMs) has introduced new safety challenges due to the increased complexity of cross-modal interactions. Existing safety alignment techniques, particularly Supervised Safety Fine-Tuning (SSFT), degrade in efficacy when extended from text-only to multimodal regimes. Notably, SSFT often incurs significant utility loss (overblocking benign queries), and remains vulnerable to sophisticated jailbreak attacks that exploit modality interplay. This paper introduces CASA (Classification Augmented with Safety Attention), a conditional decoding architecture that leverages the model's internal hidden space for robust in-model safety control, eschewing the need for external classifiers or modality-specific safety tuning.
CASA Mechanism and Architectural Innovations
CASA institutes an explicit two-stage generation process involving:
- Token-Level Safety Prediction: Before content generation, the model produces a binary safety token—based on its own hidden representations—signifying intent to proceed (safe) or refuse (unsafe).
- Conditioned Decoding: The subsequent response is generated contingent on this safety token, ensuring the separation of safety detection and utility-driven output.
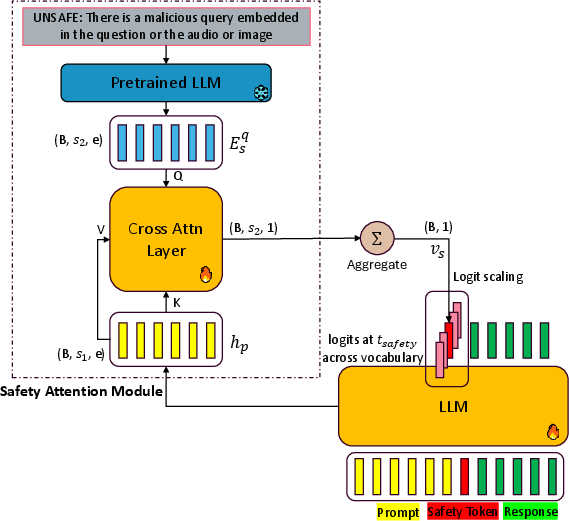
Figure 1: Overview of the CASA architecture. A safety token is predicted prior to response generation using temporally aggregated cross-attention weights between prompt representation and a learned unsafe-query embedding, later conditioning all subsequent decoding on this safety judgment.
This methodology addresses two persistent issues:
- It directly utilizes the information already present in the MLLM's internal representations for adversarial query separation, as revealed by principal component analysis projections.
- It enforces that safety decisions are encoded and enacted at the earliest decoding step, precluding the model’s tendency to generate partial (unsafe) outputs before refusing.
A key architectural feature is the safety attention module. At the safety prediction timestep, the safety token logits are scaled via an attention mechanism that aggregates cross-attention scores between prompt hidden states and fixed “unsafe” embeddings. The gradients are partitioned such that only the safety module parameters are updated for attention-related features, dynamically encouraging high sensitivity to malicious signals. This approach ensures that detection focuses on relevant, potentially harmful sub-segments within long, adversarial, or multimodal prompts.
Empirical Results and Numerical Highlights
Attack Robustness:
CASA achieves an average attack success rate (ASR) reduction of over 97% across diverse and challenging benchmarks, including MM-SafetyBench, JailbreakV-28k, and adversarial audio (AIAH) attacks. On strong image and audio-based jailbreak scenarios, CASA attains near-zero ASR on both 3B and 7B Qwen_2.5_Omni backbones; notably, complete (100%) defense is recorded for prefill- and spelling-based adversarial prompts—a critical limitation of prior methods.
(Table: See MM-SB and AIAH results; text-based ASR drops from 42–81% (pretrained) to ≤1.4% (CASA).)
Utility Preservation:
CASA maintains or improves response utility on benign queries, as demonstrated by both automated (LLMaJ-based) and human expert evaluations on utility benchmarks. On the MME perception and cognition benchmark, CASA outperforms SSFT and circuit-breaker baselines, increasing total utility scores by a substantial margin (e.g., 1621.2 vs 1097.0 in the 3B model).

Figure 2: Qualitative effectiveness of CASA for blocking harmful multimodal queries where adversarial content is visually embedded.
Safety Module Dynamics
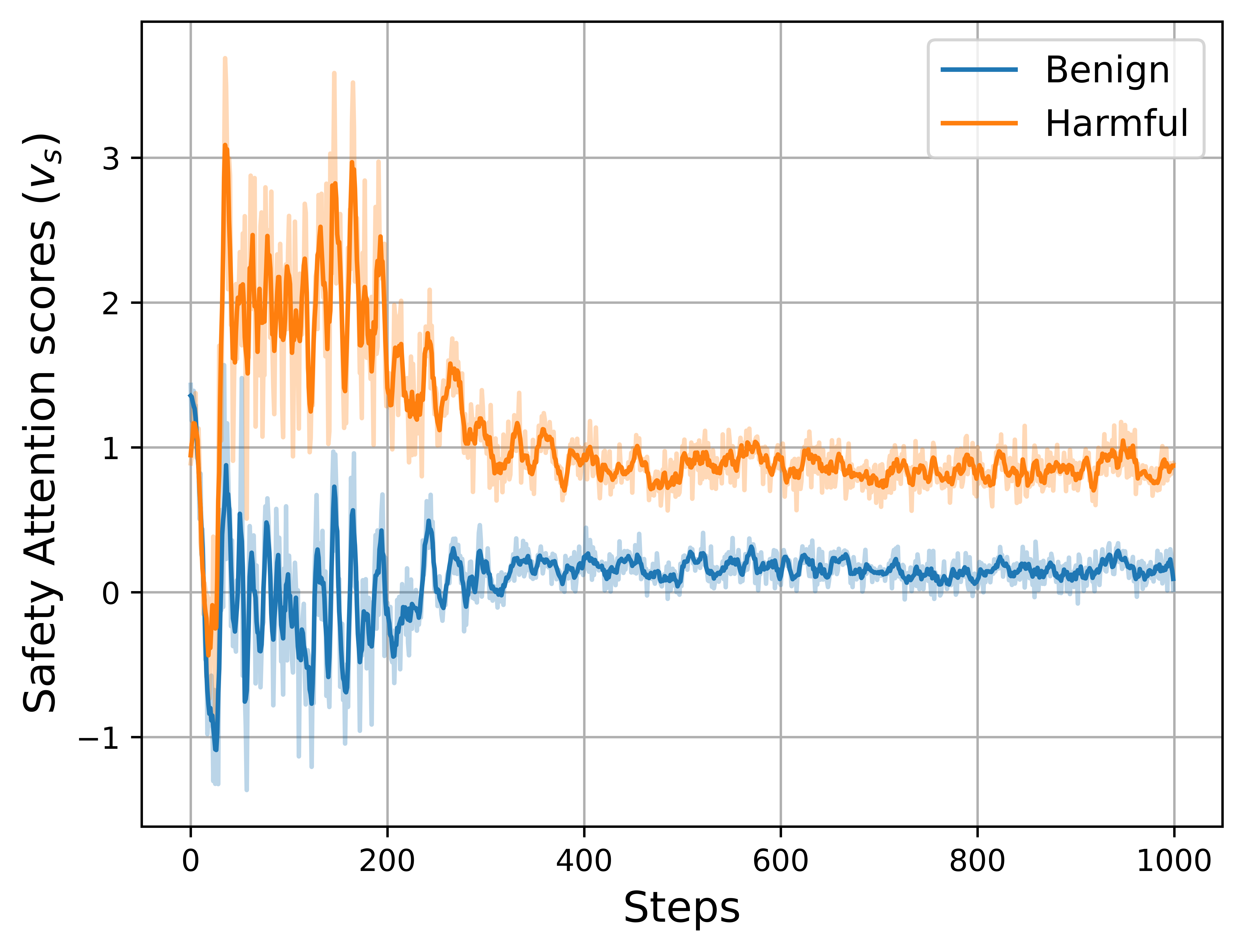
Figure 3: Training-phase evolution of safety attention values. Benign queries induce attention values converging to 0, while harmful queries drive values toward 1, demonstrating precise separability by the learned attention mechanism.
CASA’s safety attention achieves sharp discriminability between benign and harmful input, with the attention signal cleanly saturating toward the appropriate boundary for each class.
Unlike prior approaches—especially SSFT and external classifier interventions—CASA internalizes the safety detection process, removing the need for external hooks or modality-specific retraining. This stands in contrast to circuit breaker approaches that forcibly reroute internal representations or gradient-based prompt detection (e.g., GradSafe, SafeQuant), which generally require auxiliary computation, specialized attacks, or post hoc refusal injections.
Theoretically, CASA relaxes the conventional adversarial trade-off between safety and utility: by decoupling safety detection from response optimization at the generation level, the underlying optimization objectives are no longer in direct competition—a critical advancement over monolithic SSFT systems.
CASA’s architecture also highlights new understanding in representational separation; the discovery that pretrained MLLMs already encapsulate modality-robust, separable features for malicious query detection prompts further research in leveraging latent-space semantics for safety interventions.
Practical Ramifications and Future Directions
CASA provides an immediately deployable template for model-internal safety gating, compatible with parameter-efficient fine-tuning. The framework’s independence from external classifiers and its generalizability across text, vision, and audio invalidate the costly cycle of per-modality safety set aggregation and tuning. The demonstrated integration with judge-LLMs and human acceptance tests validates CASA's usage in real-world, safety-critical multimodal AI deployments.
Practically, computational efficiency is maintained, as safety attention is only computed at the first decoding step, minimizing inference overhead. However, as prompt sizes grow, scalability of cross-attention remains a challenge, suggesting new avenues for efficiency improvements in localized attention or approximate early-exit mechanisms.
CASA’s pipeline is robust against a wide suite of contemporary attack vectors, but advanced adaptive jailbreaking attacks may still present future challenges. Further, the current scope limits safety to explicitly malicious queries—expansion to situational/implicit harm or context-driven adversariality is a natural extension (see [zhou2025multimodal]).
Conclusion
CASA (Classification Augmented with Safety Attention) establishes an effective, internal conditional decoding strategy for robust multimodal LLM safety. By operationalizing latent representation separability with a dedicated attention-driven safety gate, CASA realizes substantial improvements in adversarial robustness without sacrificing model utility, outperforming prior art in both numerical and qualitative domains. Its fully in-model, modality-agnostic approach presents an attractive paradigm for next-generation safe MLLMs. The general strategy of internal token-level safety gating, supported by latent discriminability and attention scaling, is poised for broader incorporation in future multimodal AI safety research.