- The paper shows that breaking symmetry in training data is critical for enabling generalization in feature learning kernels using the Recursive Feature Machine.
- The study employs group-theoretic analysis to reveal that disrupting subgroup invariance through random data removal restores proper generalization.
- The results emphasize that careful data partitioning aligning with kernel symmetry and task structure is essential to avoid symmetry traps that hinder learning.
Data Symmetry and Generalization in Feature Learning Kernels
Overview
This paper explores the relationship between data symmetry and generalization within the context of feature learning kernels, specifically using the Recursive Feature Machine (RFM) algorithm. The authors investigate the phenomenon of grokking—where models achieve high training accuracy but only generalize after extensive additional training—on algebraic tasks such as modular arithmetic and binary operations in Abelian groups. Through a group-theoretic lens, the paper demonstrates that the generalization behavior of RFM is fundamentally governed by the symmetry structure of the training data and the target function, and that breaking this symmetry is essential for generalization.
Grokking and Symmetry Groups in Algebraic Tasks
The paper builds on prior studies of grokking in neural networks and feature learning kernels, extending the analysis to algebraic functions characterized by an explicit symmetry group. Binary operations in Abelian groups (e.g., modular addition) are examined, where the symmetry group of the function can transform any data point with a given label into any other with the same label. RFM, through iterative AGOP-based feature updates, is shown to learn representations closely linked to the symmetry group governing the target function. This group-theoretic approach provides a rigorous framework for understanding how selected data partitions may induce “symmetry traps” that inhibit generalization.
Experimental Characterization: Symmetry Breaking and Generalization
Empirical results establish that generalization in RFM occurs only when the symmetry of the training data is broken. When the train-test partition is invariant under a subgroup of the full symmetry group (e.g., dihedral group D2p for modular addition with p prime), RFM fails to generalize to the test set; moving even a single random training point into the test set (thus breaking invariance) enables generalization.
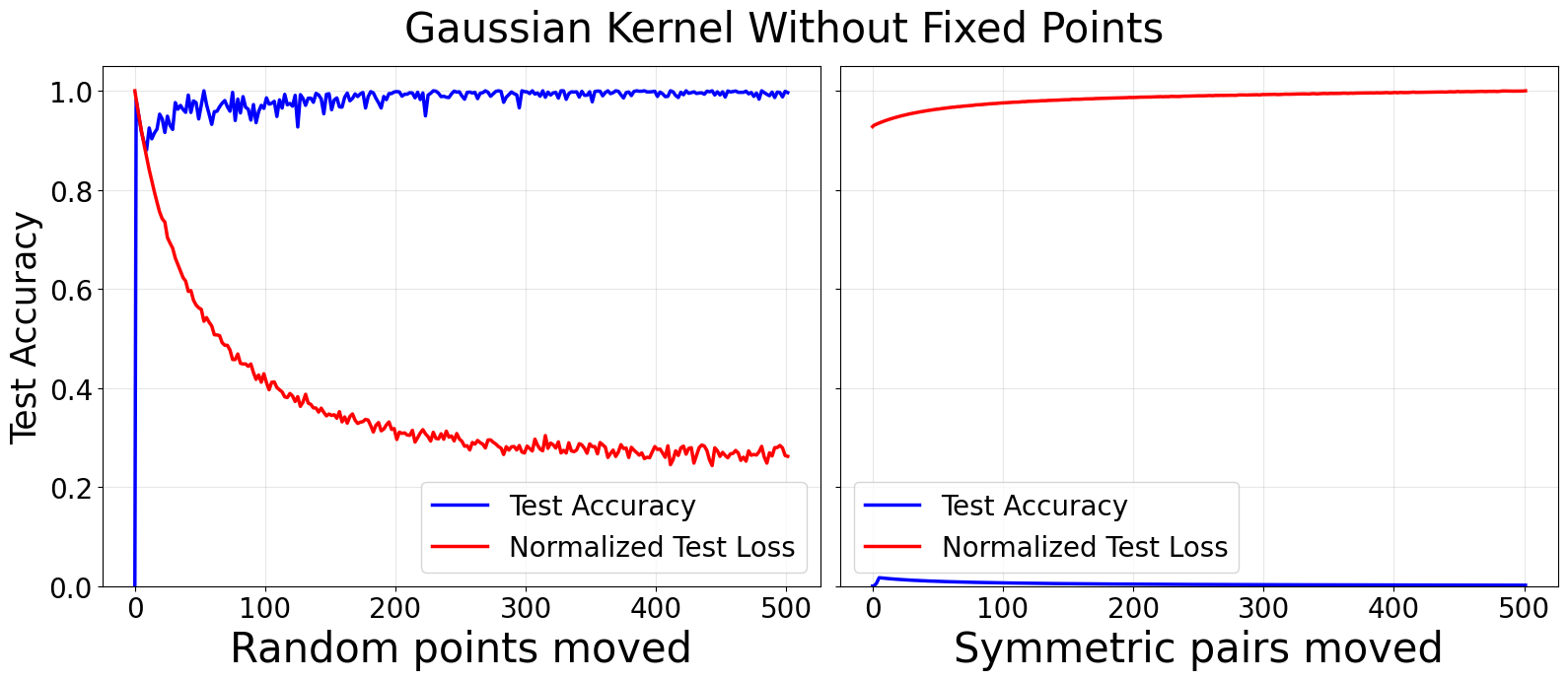
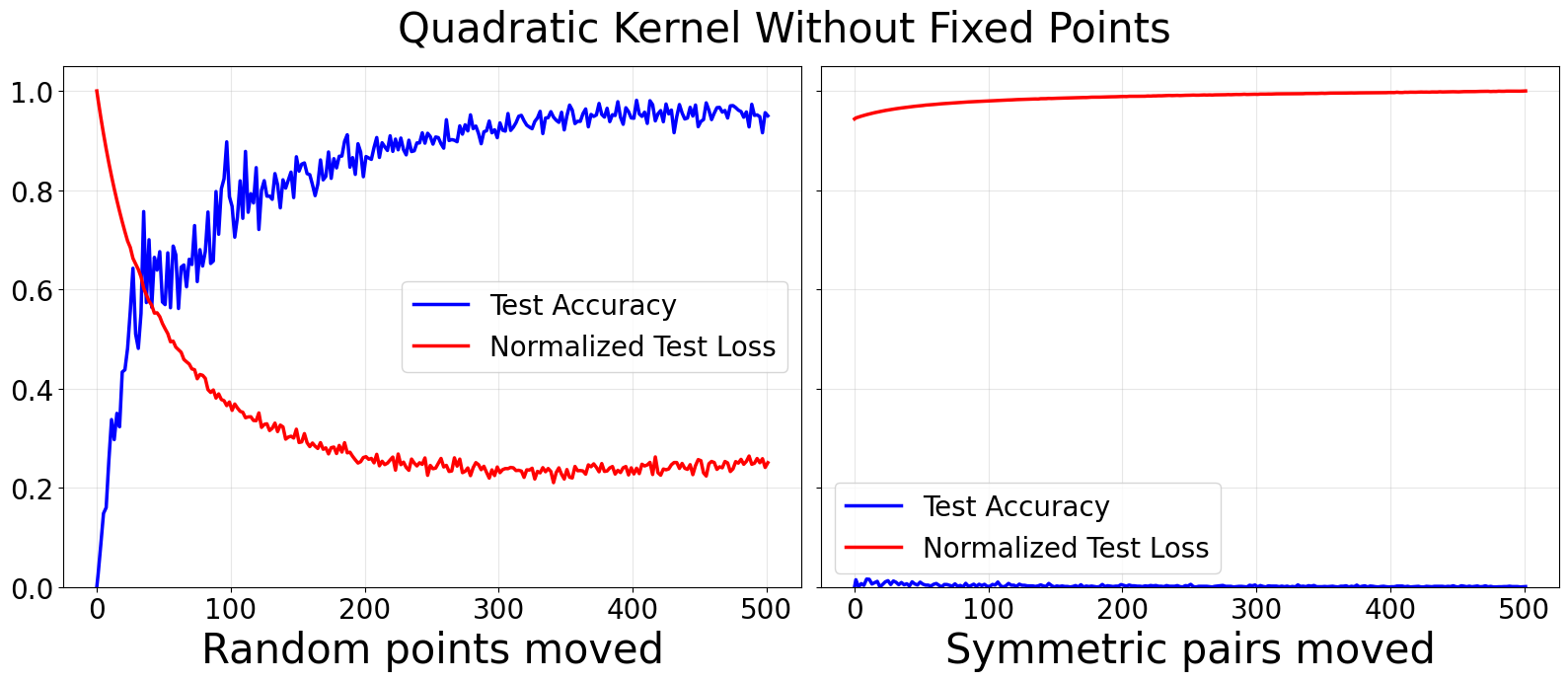
Figure 1: Gaussian (top) and quadratic (bottom) kernels trained for addition modulo p=53 on symmetric partitions; random removal of points breaks symmetry and allows generalization, whereas removal by symmetric pairs does not.
Symmetry breaking is further studied through:
- Random vs. symmetric removal of data points: Removing points randomly from the training set disrupts subgroup invariance and rapidly restores generalization. Removing points in symmetric pairs does not break invariance and generalization remains absent.
- Fixed points and orbits: By withholding fixed points under specific reflections (e.g., srk) from the training set, test accuracy falls to zero. Breaking this symmetry by moving random points yields near-perfect generalization.
Feature Matrix Structure and Group Representations
The learned features (via AGOP) are shown to encode group-theoretic structure. When trained on random partitions, RFM recovers block-circulant feature matrices, mapping closely to permutation representations of the symmetry group. With non-generalizing partitions (e.g., withholding fixed points), the feature matrices exhibit support primarily aligned with the subgroup elements of the symmetry group.
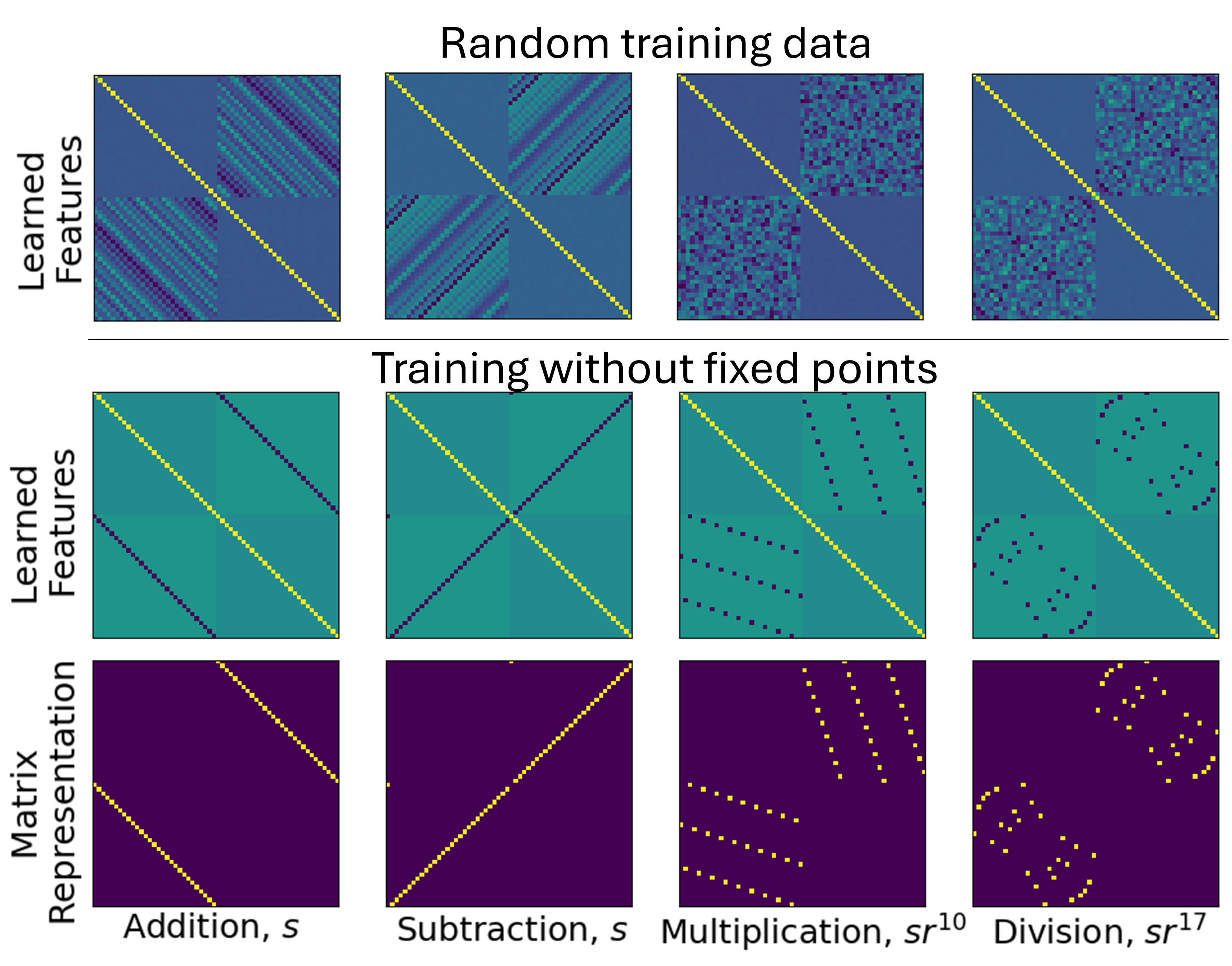
Figure 2: Feature matrices learned by RFM on modular arithmetic tasks align with group-theoretic permutation representations of the relevant symmetries.
Extensive comparisons are made between the AGOP matrices produced by RFM and theoretical permutation representations, confirming that the kernel can internalize only those symmetries present in the training data.
Subgroup Structure and Generalization Orbits
The failure to generalize is further explored through other dihedral subgroups. Data partitions invariant under subgroups of D2p (e.g., larger dihedral subgroups in non-prime p) also inhibit generalization. The precise characterization of fixed points, reflection pairs, and orbits is analytically developed for both cyclic and Abelian group settings.
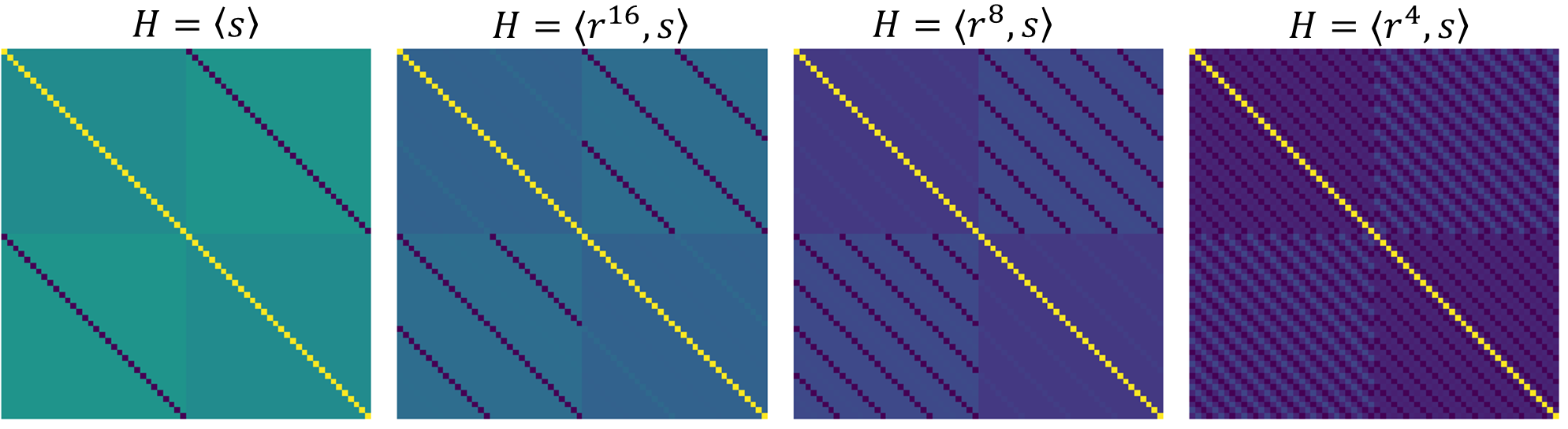
Figure 3: AGOPs for addition mod 32 trained on partitions excluding fixed points of dihedral subgroups. RFM does not generalize under these settings, confirming theoretical predictions.
Initialization and Generalization to Group Orbits
By initializing the feature matrix to encode a particular subgroup symmetry (e.g., matrix aligned with a fixed reflection), RFM is constrained to generalize only within the orbit of that subgroup action. Empirical results show perfect correspondence between theoretical orbit predictions and actual test outputs.
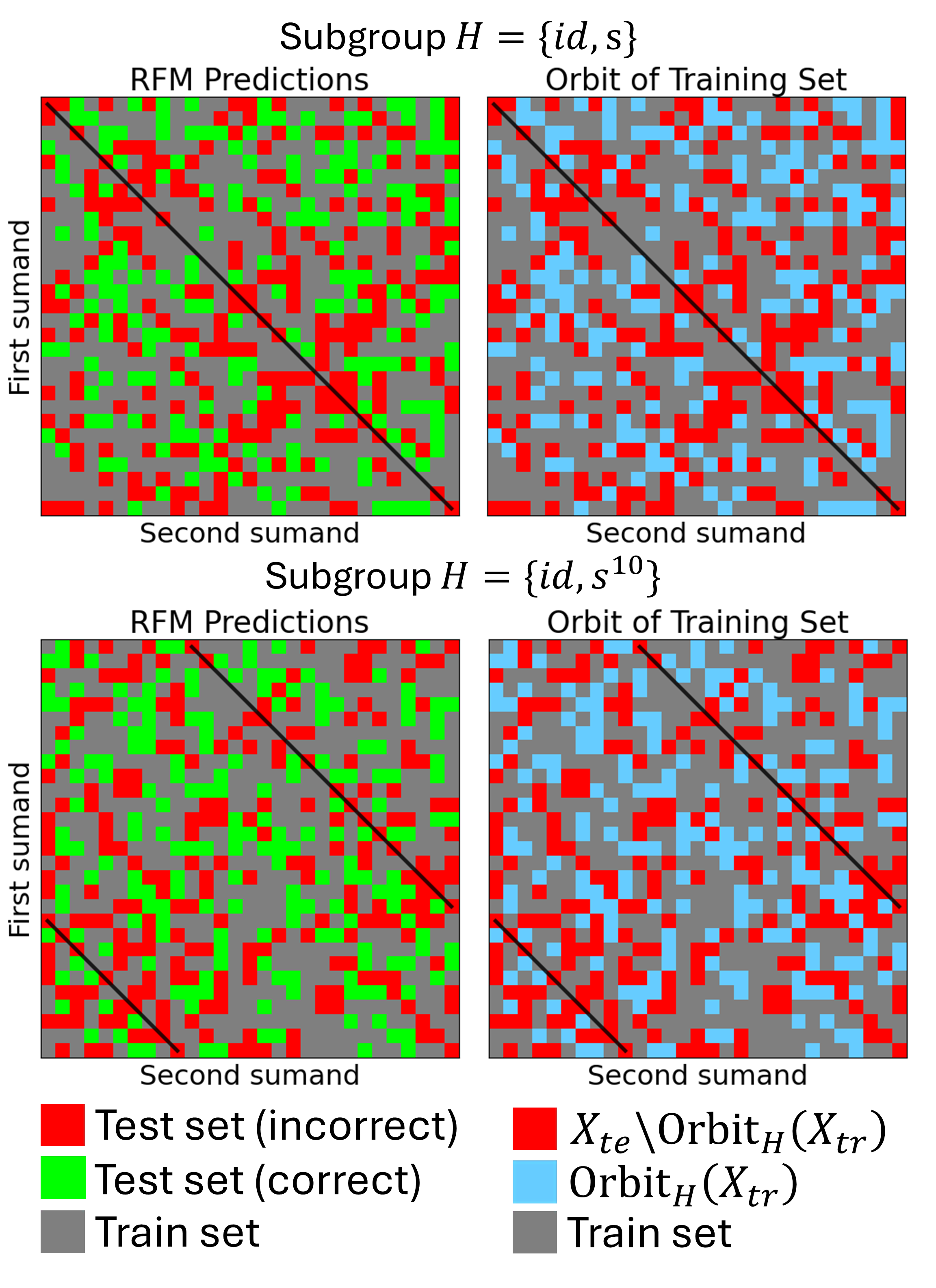
Figure 4: RFM initialized with feature matrix encoding a subgroup generalizes only to points within the orbit of that subgroup action; precision and recall are both 100% for theoretical prediction vs. observed outcomes.
Theoretical Implications and Directions
The paper’s analysis unifies group-theoretic representation theory and empirical results for feature learning kernels. It rigorously demonstrates that data symmetry fundamentally determines generalization—subgroup invariance in training partitions induces symmetry traps, and breaking invariance releases these traps. This insight applies not only to kernels, but also invites comparison with neural network grokking and regimes in which feature learning transitions from “lazy” to “rich” dynamics.
Practically, the results advocate for careful design of data partitions in learning tasks with high symmetry; data with symmetry traps can dramatically inhibit generalization despite the use of sophisticated feature learning mechanisms. The group-theoretic approach provides predictive power for such behaviors, and suggests that symmetries in initialization and kernel choice must be matched with the structure of the learning task to avoid failures in generalization.
Conclusion
This paper provides a detailed analysis of generalization failures and successes in feature learning kernels, rooted in the symmetry structure of algebraic tasks. Using the Recursive Feature Machine and AGOP, the authors demonstrate that breaking data symmetry is necessary for generalization; partitions invariant under symmetry group subgroups prevent the kernel from learning beyond the training set. The learned features are shown to encode group-theoretic representations, and the theoretical predictions regarding orbits, fixed points, and subgroup structures match empirical outcomes precisely. This work establishes a rigorous connection between group symmetry, data partitioning, and generalization in feature learning, and sets the stage for further theoretical development and extension to other models and learning regimes.

