- The paper introduces a novel dynamic graph model with adaptive feature selection that significantly improves RGB-D indoor scene recognition.
- It employs attention-driven node selection and dual ResNet-101 backbones to fuse multi-modal features, achieving 57.7% and 70.4% mean-class accuracies.
- The framework offers a robust, interpretable method for adaptive multi-modality fusion, paving the way for enhanced real-time robotic and vision systems.
Dynamic Graph Neural Networks with Adaptive Feature Selection for RGB-D Indoor Scene Recognition
Introduction
Indoor scene recognition leveraging both RGB and depth (RGB-D) data is critical for robotic, vision, and semantic understanding systems operating in cluttered, complex environments. Traditional approaches mainly rely on global CNN feature aggregation or hand-designed local features, which demonstrate limitations in adaptively selecting and exploiting discriminative local signals—especially under challenging modality fusion requirements. The paper "Dynamic Graph Neural Network with Adaptive Features Selection for RGB-D Based Indoor Scene Recognition" (2604.00372) introduces a dynamic graph-based model that learns to adaptively select and organize local features from both modalities using attention mechanisms, processes their relations with a dynamically updated graph structure, and performs cross-modality feature fusion for state-of-the-art classification performance.
Methodology
End-to-End Dynamic Graph Construction
The proposed framework comprises four main modules: feature extraction, adaptive node selection (ANS), dynamic graph modeling, and multi-modality feature fusion.
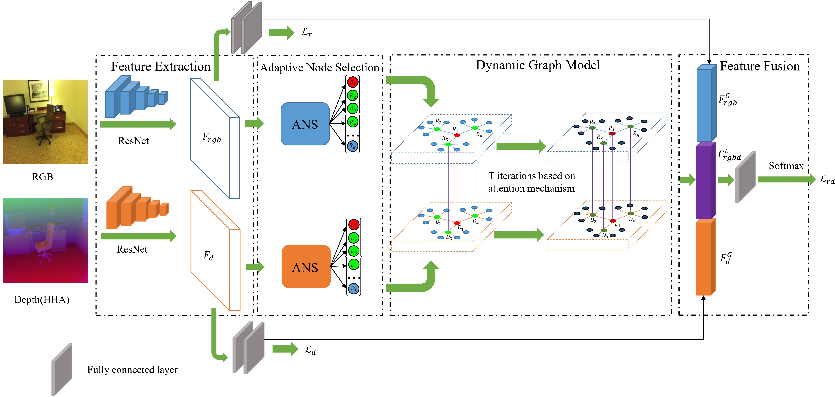
Figure 1: End-to-end pipeline for RGB-D scene recognition, showing CNN-based feature extraction, adaptive node selection, multi-level dynamic graph construction, and final fusion for classification.
RGB and depth images are independently processed using two ResNet-101 backbones, obtaining dense spatial feature maps for each modality. The ANS module applies channel and spatial attention (CBAM) to compute importance maps per modality. Nodes (local features) with the top-k attention responses are selected and categorized hierarchically into one main-central, several sub-central, and leaf nodes, reflecting their semantic and spatial importances.
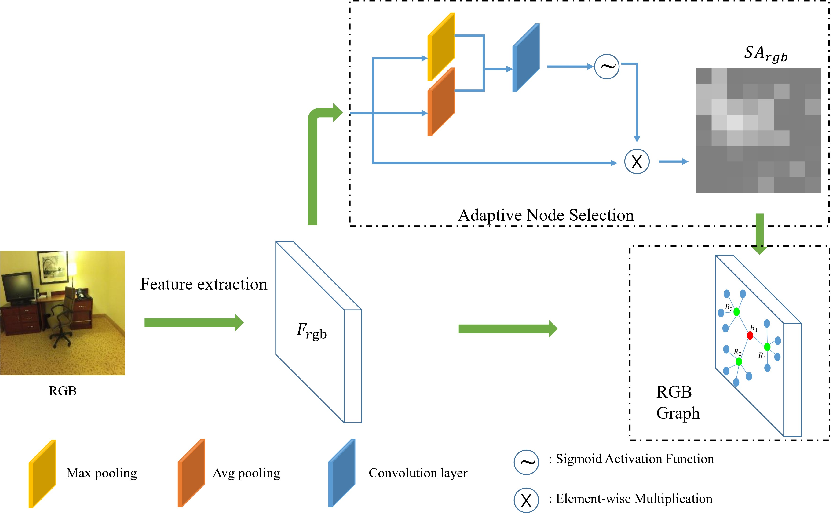
Figure 2: Node selection and organization for a single modality, with attention-driven assignment to central and peripheral roles in the dynamic graph.
Sparse Hierarchical Multi-Modality Graph Connections
Edges in the graph are constructed with modality- and importance-aware strategies. Intra-modality connections link sub-central to central nodes and associate each leaf to its nearest sub-central node via Euclidean distance in feature space, forming a hierarchical structure that favors information flow from discriminative regions to minor details.
Inter-modality graph construction is designed to address the latent semantic gap between RGB and depth modalities, linking corresponding main-central and sub-central nodes sparsely but effectively—thereby maximizing informative cross-modal context while minimizing noisy interference.
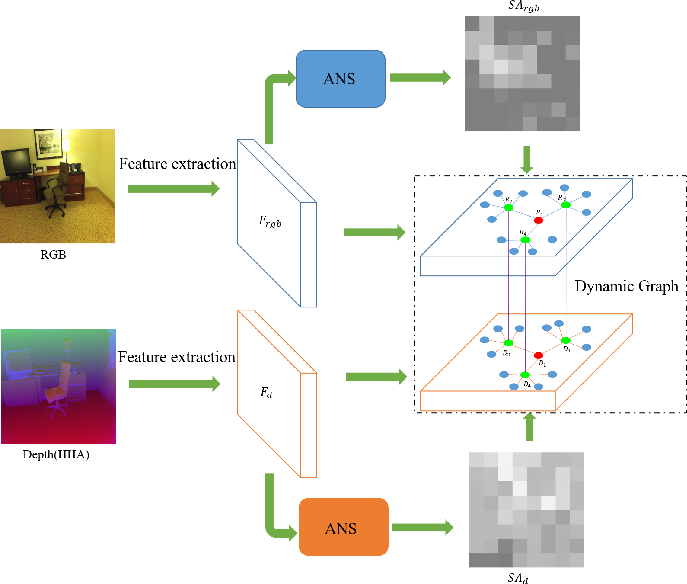
Figure 3: Sparse cross-modal connections between RGB and depth graphs, linking central and sub-central nodes to leverage complementary cues with minimal semantic dilution.
Attention-Guided Graph Update and Fusion
The model employs dual attention mechanisms: first to guide node selection (ANS), and then, in each graph propagation layer, to adaptively weight both intra- and inter-modality neighbors during node feature update. Node attributes from both RGB and depth flows are updated via attention-weighted aggregation, ensuring that only central, highly contributing features strongly modulate scene representation. After several propagation layers, the optimized node features are concatenated with the global CNN features from both modalities and fed to a final classifier.
Experimental Evaluation
Results on SUN RGB-D and NYU Depth v2
Comprehensive experiments on SUN RGB-D and NYU Depth v2 datasets demonstrate that the proposed method achieves state-of-the-art mean-class accuracies of 57.7% and 70.4%, respectively—surpassing prior CNN-, fusion-, attention-, and GNN-based approaches.
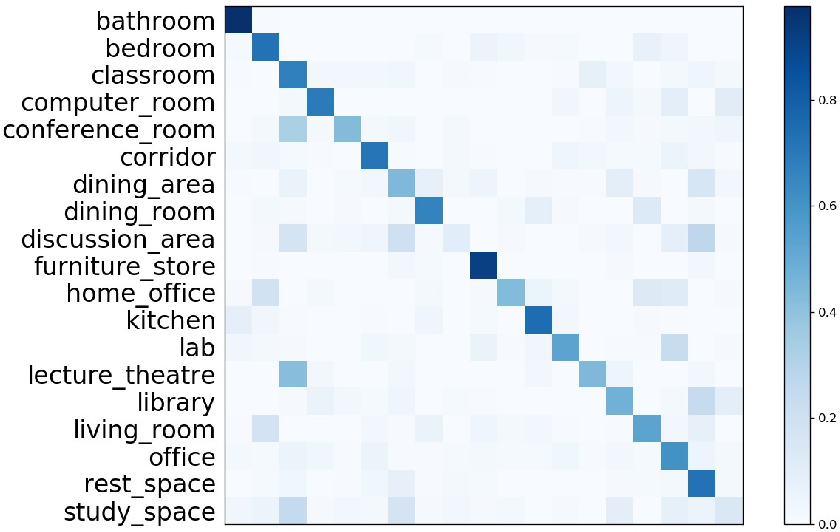
Figure 4: Confusion matrix for SUN RGB-D, indicating robust recognition across diverse indoor classes with minimal confusion primarily between visually or functionally similar categories.
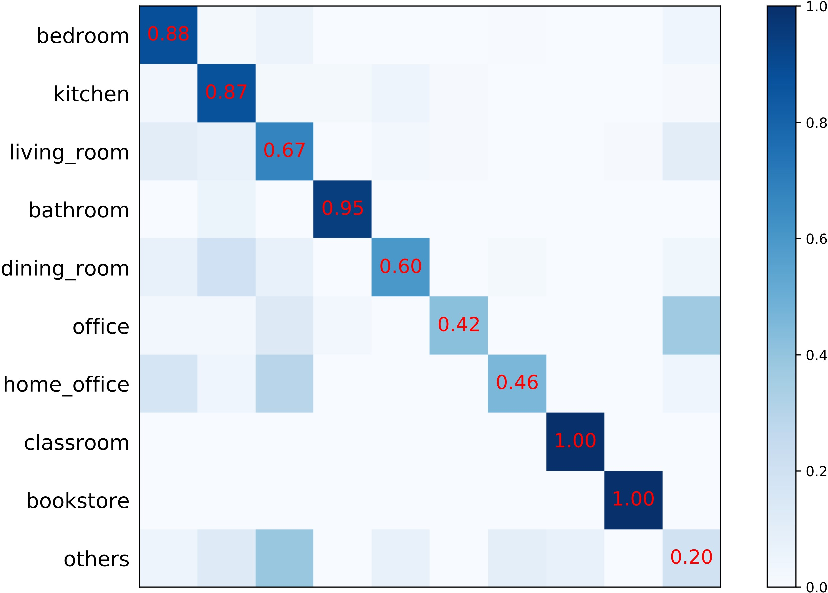
Figure 5: Confusion matrix for NYU Depth v2. Several classes (e.g., "classroom," "bookstore," "bathroom") achieve near-perfect accuracy; lowest performance is in compound 'other' classes with fewer training examples.
Detailed Analysis and Ablation
Ablation studies highlight the contributions of each component:
- Single modality vs. multimodal fusion: Fusing RGB and depth features with graph reasoning offers a 6-7% accuracy boost over simple concatenation or single-modality baselines.
- Dynamic graph structure: Leveraging attention to dynamically construct and update node connections outperforms fixed graph structures and naive local feature aggregation.
- Attention mechanisms: Removing attention reduces performance by up to 2%, affirming its necessity for adaptive information propagation.
- Node selection parameter k: Empirically, 16 nodes per modality balance representational power and noise avoidance; fewer nodes lack coverage, while more nodes dilute discriminative power.
Theoretical and Practical Implications
The work advances the state-of-the-art in several respects:
- Adaptive, semantic-aware feature selection from high-dimensional CNN feature spaces enables robust focus on discriminative regions, eliminating reliance on external object detectors or heuristic local sampling.
- Hierarchical, sparse multi-modal graph design provides an expressive yet efficient framework for capturing both intra- and inter-modality relationships, essential for robust fusion in cluttered environments.
- Attention-driven graph updating confers flexibility and interpretability, supporting dynamic re-weighting of salient scene elements per sample, accommodating intra-class variation, and reducing the impact of outliers.
Practically, the design is compatible with any strong CNN backbone, is fully differentiable, and can be easily extended to new modalities, scene types, or integration with temporal reasoning for video or multi-view data.
Future Directions
Potential avenues for future research include: (1) more sophisticated cross-modality alignment techniques to further mitigate semantic gaps; (2) explicit modeling of temporally dynamic or viewpoint-varying scenes; (3) exploration of unsupervised or few-shot scenarios leveraging the graph’s structural priors; (4) transfer to embodied agents for on-device scene understanding.
Conclusion
This work establishes a principled, high-performing dynamic graph neural network approach with adaptive feature selection for RGB-D indoor scene recognition. Attention-guided node selection, hierarchical graph construction, and modality-aware dynamic update mechanisms are proven effective in extracting, organizing, and integrating complementary 2D and 3D cues. The framework achieves new benchmarks on standard indoor datasets, supporting robust and efficient multi-modal scene perception, and sets a foundation for further innovations in graph-based scene understanding and fusion (2604.00372).