- The paper demonstrates a novel, training-free trajectory planning method that uses kernel-based score estimation to replace dynamic simulations.
- It employs a triple-kernel structure and reward-based candidate selection to ensure robustness and near-parity with model-based diffusion planners across various systems.
- Empirical results show high safety rates and strong performance on systems up to 6D, while maintaining theoretical consistency and sample efficiency.
Behavioral Score Diffusion: Training-Free Model-Free Trajectory Optimization via Kernel Score Estimation
Introduction
Behavioral Score Diffusion (BSD) introduces a model-free, training-free paradigm for trajectory planning, eliminating dependencies on explicit dynamics models or neural network-based score approximation. BSD implements direct nonparametric inference of the diffusion score using a library of a finite number of pre-collected trajectories, rendering it a practical alternative to both model-based diffusion (MBD) planners and kernel/neural generative approaches. Kernel-based Nadaraya-Watson estimation is employed to construct multi-scale, goal- and context-aware interpolants in data-driven planning scenarios—a critical step toward broadening diffusion-based planning applicability to systems with inaccessible, uncertain, or highly nonlinear dynamics.
An overview of the BSD framework illustrates three core computational modules: initialization from noise, nonparametric score estimation using a triple-kernel structure, and safety-constrained denoising with multi-sample candidate selection.
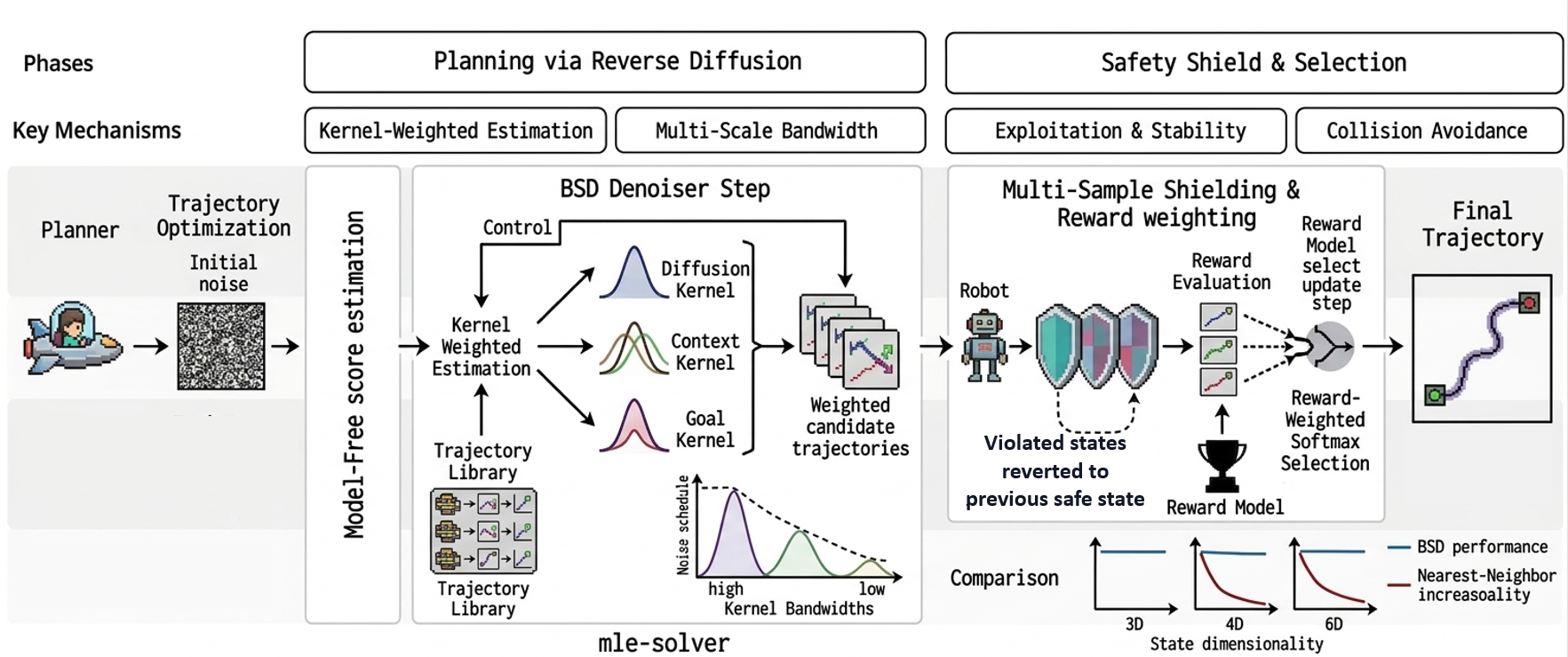
Figure 1: Overview of Behavioral Score Diffusion, showing initialization from noise, triple-kernel weighted score estimation, and reward-based trajectory selection; BSD's performance scales robustly with state dimensionality versus the nearest-neighbor baseline.
BSD is positioned at the intersection of trajectory-level diffusion planners, safety-constrained generative approaches, data-driven predictive control, and kernel-based score estimation. BSD diverges from diffusion policies that rely on extensive neural training [janner2022planning, chi2023diffusionpolicy] by directly leveraging trajectory libraries. Unlike MBD [pan2024mbd] and its shielded extensions [kim2026safempd], BSD requires neither model access nor explicit simulation rollouts. The theoretical underpinnings generalize DeePC [coulson2019deepc, coulson2022robust] beyond LTI systems, with consistency and sample complexity inherited from nonparametric regression [nadaraya1964, bierens1987kernel]. Recent advances in kernel-based score estimation for diffusion models [yang2026trainingfree, veiga2025kernelsmoothed] motivate BSD's estimator structure for safe, data-driven planning.
BSD: Method and Theory
BSD replaces per-step (reverse) diffusion rollouts through dynamic models with kernel regression over trajectory data. For denoising step i, triple kernel weights are computed to capture (1) diffusion proximity, (2) initial state-context, and (3) goal relevance, with optional reward reweighting to bias toward high-performance trajectories. The diffusion noise schedule modulates bandwidths, effecting a transition from coarse to fine-scale regression during iterative denoising.
Candidate control sequences are constructed by multinomial sampling from the kernel-weighted dataset, and reward-softmax selection over multiple samples is used to select the next denoising iterate.
Theoretical analysis guarantees (1) pointwise consistency of the estimator for arbitrary continuous dynamics and (2) MSE rates determined by the data size and ambient dimensionality. In the LTI regime, BSD is shown to be equivalent to regularized DeePC with maximum-entropy weighting. Safety preservation is ensured by the direct inheritance of the geometric shielding mechanism, which is agnostic to the source of the underlying state sequence.
Experimental Validation
Experiments span four robotic systems (bicycle, two- and three-joint tractor-trailer, and accelerating tractor-trailer) ranging from 3D to 6D state spaces. BSD is systematically compared to MBD (upper bound), nearest-neighbor retrieval (NN; lower bound), and an ablated BSD variant with adaptive bandwidth scheduling.
BSD-fix (fixed bandwidth) closely tracks MBD across all but the most challenging 6D system, achieving an average 98.5% of the MBD reward. NN strongly degrades with system complexity, confirming that infusing the diffusion denoising mechanism in BSD is critical for high-dimensional, nonlinear control. Adaptive bandwidth scheduling impairs performance due to the variance/bias tradeoff intrinsic to high-dimensional kernel regression, as predicted theoretically.
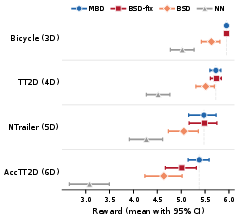
Figure 2: BSD-fix attains near-parity with MBD in mean reward across all evaluated state dimensionalities, with NN degrading sharply as complexity grows.
BSD-fix also matches or exceeds MBD’s safety rates in three systems; only on the most complex 6D platform does a statistically marginal shortfall emerge. The multi-sample candidate mechanism in BSD allows coverage of the behavioral manifold when available data is limited, and preservation of reward distribution indicates robust match to model-based ground truth.
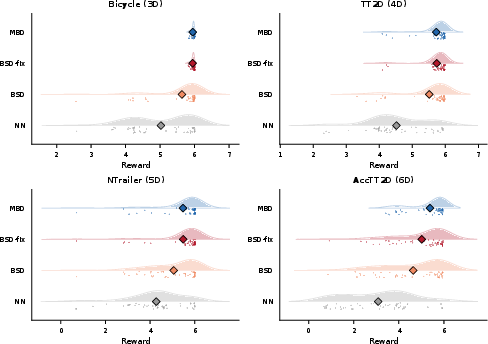
Figure 3: Reward distribution analysis demonstrates BSD-fix mirrors MBD in mean and spread, with wider variance appearing only in higher dimensions.
Trial-by-trial correlations between BSD-fix and MBD using common random initializations verify the faithfulness of kernel-based planning—correlations consistently exceed 0.7 and reach as high as 0.99.
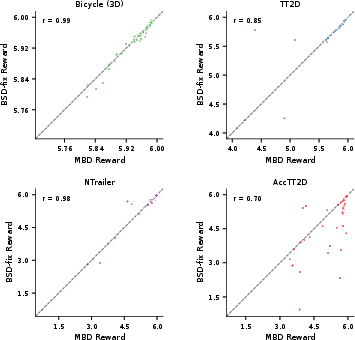
Figure 4: High Pearson correlation coefficients indicate tight per-trial agreement between BSD-fix and MBD on identical initial conditions.
From a computational perspective, BSD incurs a 1.5–3.8× computational penalty versus MBD, though this overhead shrinks at higher state dimensions where model rollouts become relatively more expensive.
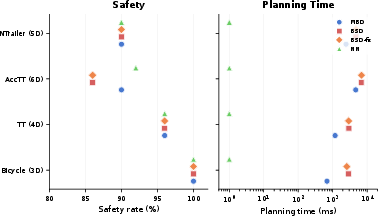
Figure 5: BSD achieves safety rates comparable to MBD, while NN suffers both in performance and in reward.
Qualitative visualizations show BSD denoising nontrivial parking trajectories and producing smooth, feasible paths akin to model-based rollouts.
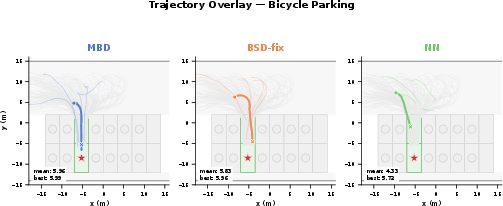
Figure 6: BSD-fix produces executed parking trajectories nearly indistinguishable from MBD's; NN consistently fails to reach the goal.
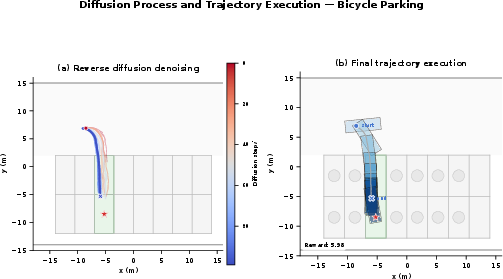
Figure 7: Progressive denoising transitions in BSD highlight the coarse-to-fine spatial organization, with endpoints matching goal geometry.
Implications and Future Directions
BSD demonstrates that data-driven, training-free trajectory planning is feasible and competitive when supported by efficient kernel estimation and exploration. The established theoretical and empirical correspondence with predictive control (DeePC) frameworks suggests that kernel-based trajectory inference is a viable foundation for generalizing data-driven control methods to nonlinear, nonparametric, or black-box domains—particularly when safety-critical constraints are required.
Key implications include:
- Practical deployment in unmodeled or proprietary systems becomes tractable by pre-collecting a finite trajectory library.
- Robust transferability of geometric “shields” is guaranteed since safety logic can be decoupled from the prediction mechanism.
- Sample complexity remains a limiting factor in very high-dimensional manifolds, though dimensionality reduction, active collection, and metric learning are promising remedies.
- Bandwidth scheduling must be carefully managed; large-scale candidate sampling can supersede the need for adaptive kernel shrinkage.
There are remaining limitations: computation overhead, reliance on the quality and coverage of the collected library, and current evaluation in simulation only. Addressing these points will further enable real-world adoption.
Conclusion
BSD presents a compelling, theoretically justified model-free planning method. By leveraging kernel-weighted estimation over trajectory libraries and multi-sample candidate exploration, BSD replaces dynamic simulators with efficient, scalable nonparametric regression. The empirical match to MBD performance, strong safety preservation, and clear superiority over naïve retrieval methods validate its standing as a practical model-free planner for constrained nonlinear systems. Future extensions should target scalable data structures, metric learning, and real-world closed-loop validation.

