- The paper introduces a dynamic stochastic model predictive control framework that optimizes weight sequences in a double linear policy.
- It derives analytical gradients for terminal wealth to enable efficient L-BFGS-B optimization while enforcing a positive expectation constraint.
- Empirical studies on BTC-USD and multi-asset tests show superior risk-adjusted performance and reduced drawdown compared to benchmark strategies.
Dynamic Stochastic Model Predictive Control for Double Linear Policy in Algorithmic Trading
Background and Motivation
The Double Linear Policy (DLP) generalizes the Simultaneous Long-Short (SLS) feedback trading paradigm by allowing time-varying, potentially asymmetric risk exposures through dynamic weight sequences. While constant-weight DLP exhibits a robust positive expectation (RPE) property under broad conditions, the challenge of sequential, in-sample optimization of these weights in a dynamic stochastic environment remains unresolved. Previous work either treated weight profiles as fixed exogenous functions or applied historical back-calibration, thereby lacking true closed-loop adaptability to current market states. The present work introduces a stochastic model predictive control (SMPC) framework for dynamically determining optimal DLP weight profiles, ensuring both RPE and strict survivability, and directly maximizing risk-adjusted performance.
The DLP splits the capital into simultaneous long and short accounts, applying linear leverage of the form πL(k)=wL(k)VL(k) and πS(k)=−wS(k)VS(k). The paper enforces a symmetric weighting scheme wL(k)=wS(k)=wk and describes the stochastic evolution of the combined value as a linear time-varying system with multiplicative feedback, rendering the objective function highly non-convex in the weight sequence.
The SMPC variant optimizes the sequence {wi}i=kk+H−1 over a receding horizon H, under box constraints 0≤wi≤wmax. The objective is the classical mean-variance criterion:
wmaxEk[yk+H]−γvark(yk+H),
subject to survivability (positive wealth) and a predicted positive expectation constraint, the latter acting as a regularizer to enforce a form of local martingale property and risk discipline.
Analytical Contributions
Given the non-convex, joint multiplicative structure, gradient-based optimization is non-trivial. The paper rigorously derives analytical gradients for both the conditional mean and variance of terminal wealth with respect to the full control sequence, providing efficient, exact updates for the L-BFGS-B quasi-Newton algorithm. Closed-form expressions for the state transition moments and their gradients with respect to weights ensure that finite-difference errors are eliminated, and gradient computations remain computationally competitive even for long horizons.
These tools are embedded in an augmented Lagrangian wrapper to enforce the non-box-positive expectation constraint, leading to a two-level optimization loop.
Empirical Evaluation
Empirical studies focus primarily on BTC-USD daily trading using six years of data, with cross-validated hyperparameters for both the receding horizon H and the risk-aversion parameter γ. The DLP–SMPC outperforms constant-weight and several prescribed time-varying DLP baselines across risk-adjusted metrics, especially drawdown.
A marked observation is that, although DLP–SMPC does not achieve the highest total return (substantially lower than naive buy-and-hold), it dramatically outperforms all benchmarks in annualized Sharpe ratio (1.388) and maximum drawdown (17.63%), demonstrating strict risk control. This behavior is visualized in the account evolution, with distinct periods of risk-on and risk-off adaptations corresponding to model-inferred regime switches.
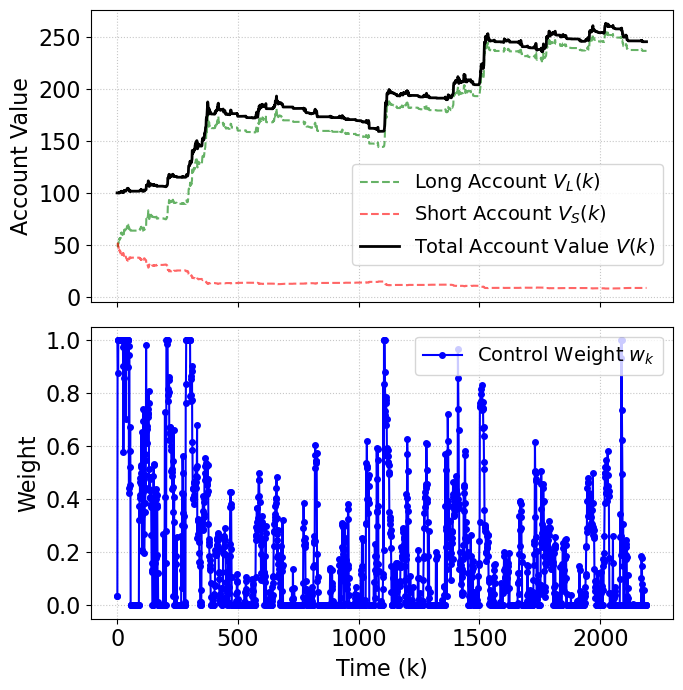
Figure 1: DLP–SMPC applied on BTC-USD, showing discrete upward moves in account value and the adaptation of control weights in response to market dynamics.
Additionally, SMPC performance is compared against global heuristics (Simulated Annealing, Differential Evolution, Basin-Hopping). The L-BFGS-B solution is nearly indistinguishable from these more expensive global searches, indicating there are no severe pathologies (e.g., poor local minima) in the practical landscape of the receding-horizon problem.
The introduction of transaction friction (ε=0.1%) is systematically evaluated, where DLP–SMPC retains its risk-adjusted leadership with only marginal reduction in gross return, a property not shared by naive or aggressive strategies, which experience significant return compression and sustained drawdowns.
Cross-Asset Generalization
Performance is robustly evaluated across orthogonal asset classes (TSLA, ETH-USD, AAPL). DLP–SMPC consistently offers superior Sharpe and Sortino ratios and lowest drawdowns (all <13%), while total returns remain competitive, confirming adaptability beyond cryptocurrency time-series and insensitivity to idiosyncratic volatility regimes.
Implications and Future Work
The presented SMPC formulation advances the state of DLP-style algorithmic trading from a static, heuristic regime into a dynamic, model-based risk-adjusted optimization. The analytic gradient enables large-horizon real-time control and makes extensions to live trading feasible. The explicit enforcement of predicted positive expectation at finite horizons represents a theoretically sound risk containment regime, balancing upside and survivability.
Practically, these advances suggest SMPC-DLP as a viable, robust overlay strategy for systematic portfolios seeking drawdown discipline under high-volatility assets.
Theoretically, this work bridges control-theoretic feedback and stochastic optimization for sequential market decision processes. The extension to non-i.i.d. return structures, e.g., persistent serial dependence, explicit GARCH/VAR effects, and cross-asset portfolios, is highlighted as an open challenge. Integration of state prediction via RL-based world models, or direct deep RL policy search over the receding horizon, are logical directions for further exploration that would further situate this contribution within the broader stochastic control and reinforcement learning literature.
Conclusion
This paper delivers a technically rigorous, empirically validated framework for sequential, risk-adjusted trading via the Double Linear Policy, enabled by stochastic model predictive control and strengthened by closed-form analysis. Empirical results underscore the method's capacity to deliver robust gains with strict downside control compared to both naïve and heuristic feedback strategies. The framework is readily extensible to multi-asset or reinforcement learning variants, positioning it as a strong candidate for institutional-grade risk-managed strategy design.