- The paper introduces a Tucker Diffusion Model that combines Tucker decomposition with an Ornstein-Uhlenbeck SDE for efficient high-dimensional tensor generation.
- The Tucker-Unet architecture integrates encoder, core-net, and decoder modules to dramatically reduce model complexity while preserving statistical fidelity.
- Empirical results demonstrate up to 100x faster generation times and robust theoretical guarantees, advancing generative modeling in high-dimensional tensor spaces.
Tucker Diffusion Models for High-dimensional Tensor Generation
Motivation and Problem Setting
High-dimensional tensor data arise naturally in domains such as multimodal sensing, biomedical imaging, and econometrics. While statistical inference for such data is well-studied, generative modeling—specifically, synthesizing new tensor samples from the data-distribution in a structured, statistically principled, and computationally efficient manner—remains underexplored. This work defines the generative goal: to accurately approximate the data distribution and rapidly generate synthetic high-dimensional tensors with multilinear structure. The central technical barrier is conventional diffusion models’ inefficacy and computational burden when extended to raw vectorization of high-order tensors, particularly in the prevalent small-n, large-p regime.
The approach leverages the Tucker decomposition, which posits that high-dimensional tensors are concentrated on lower-dimensional multilinear manifolds characterized by core tensors and orthonormal mode-wise factor loadings. The integration of Tucker structure with diffusion-based deep generative models is nontrivial, necessitating new architectural and theoretical innovations.
Tucker Diffusion Model: Architecture and Algorithmic Innovations
The paper introduces the Tucker Diffusion Model, comprising a multinomial structured Ornstein-Uhlenbeck SDE on tensors and a custom, tensor-respecting neural network architecture—Tucker-Unet—for efficient score matching.
Architecture: Tucker-Unet
Tucker-Unet comprises five key modules:
- FiLM (Feature-wise Linear Modulation) Layer: Optionally accommodates mode-specific noise heterogeneity.
- Tucker Encoder: Projects the high-dimensional tensor input into a low-dimensional core representation, respecting the multilinear structure.
- Core-Net: Approximates the score function on the latent manifold (core space) using a lightweight, low-dimensional neural network.
- Tucker Decoder: Maps the score back to the ambient tensor space.
- Residual Skip Connection: Facilitates efficient training and gradient flow.
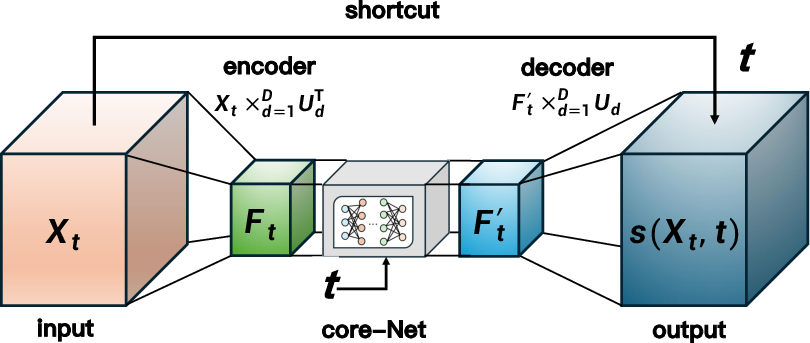
Figure 1: Visualization of the homogeneous Tucker-Unet by deactivating the noise heterogeneity structure, illustrating the information flow across its encoder, decoder, and residual skip modules.
Forward and Reverse Diffusion
The model formulates both the forward corruption (noising) and the backward generative (denoising) SDEs in tensor space, parameterized by a time-varying score field with analytical tractability under the Tucker assumption:

Figure 2: A visual demonstration of the forward (noising) and backward (generative) processes of a diffusion model applied to a real-world medical image.
Score matching is performed in closed form via denoising objectives, enabled by exploiting the Gaussian and multilinear structure of transition kernels in the tensor-valued Ornstein-Uhlenbeck process.
Score Decomposition and Dimension Reduction
The central theoretical result is a decomposition lemma showing that, under the low-rank Tucker model, the exact score function splits into a Tucker subspace term (parameterized entirely by the core) and a residual complement term. This allows Tucker-Unet to learn only the effective core-score, massively reducing the statistical and computational complexity relative to models that operate on the full vectorized tensor.
Theoretical Guarantees
The paper provides complete non-asymptotic theory for Tucker diffusion models:
- Approximation Error: For any desired L2 error ϵ, there exists a Tucker-Unet configuration whose required network width, depth, and parameter count scale only with the core size r=∏d=1Drd, not with the ambient tensor dimension p=∏d=1Dpd.
- Statistical Estimation Rate: With n samples, the empirical denoising score-matching loss converges to the population optimum at a rate determined by the maximum mode dimension pmax and core size, a marked improvement from typical dependency on p.
- Distributional Convergence: The total variation between generated and true tensor distributions using the learned model vanishes at a rate depending only on pmax and not p0, subject to standard regularity and Lipschitz conditions.
This dimension-independence is a strong theoretical claim, sharply distinguishing the approach from tensor-vectorization-based diffusion methods.
Empirical Evaluation
Synthetic and Real-world Benchmarks
Experiments evaluate Tucker-Unet versus canonical high-dimensional U-Net architectures (Conv-UNet) on synthetic matrix/tensor factor models, topological summaries of graphs (molecular datasets), high-resolution medical imaging (OrganAMNIST), and real spatiotemporal transportation data (NYC Taxi Trip logs).
In all cases, Tucker-Unet achieves comparable or superior statistical fidelity (subspace distance, core Fréchet distance) with threefold reduction in training time and up to 100x reduction in generation time relative to Conv-UNet.
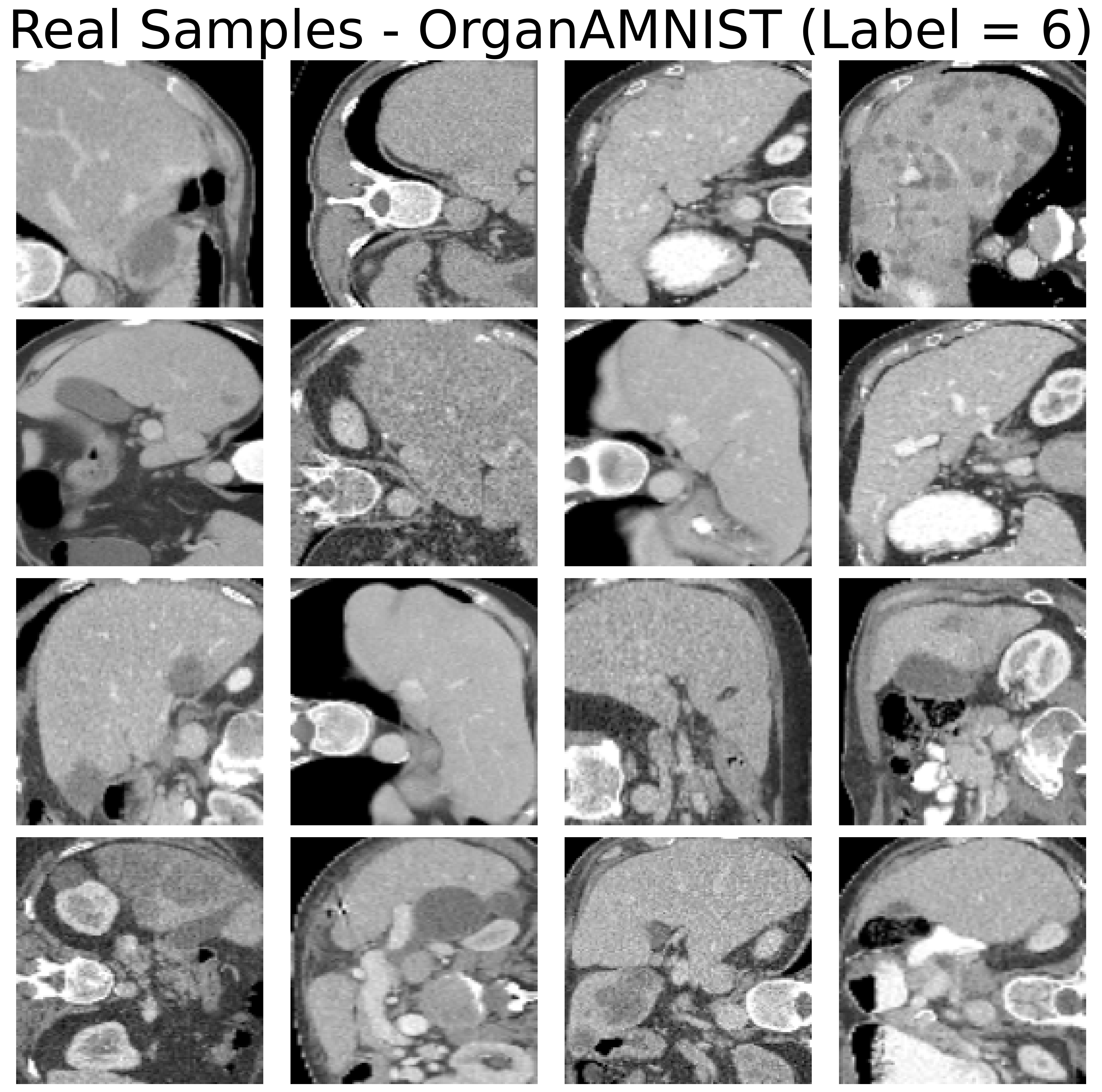
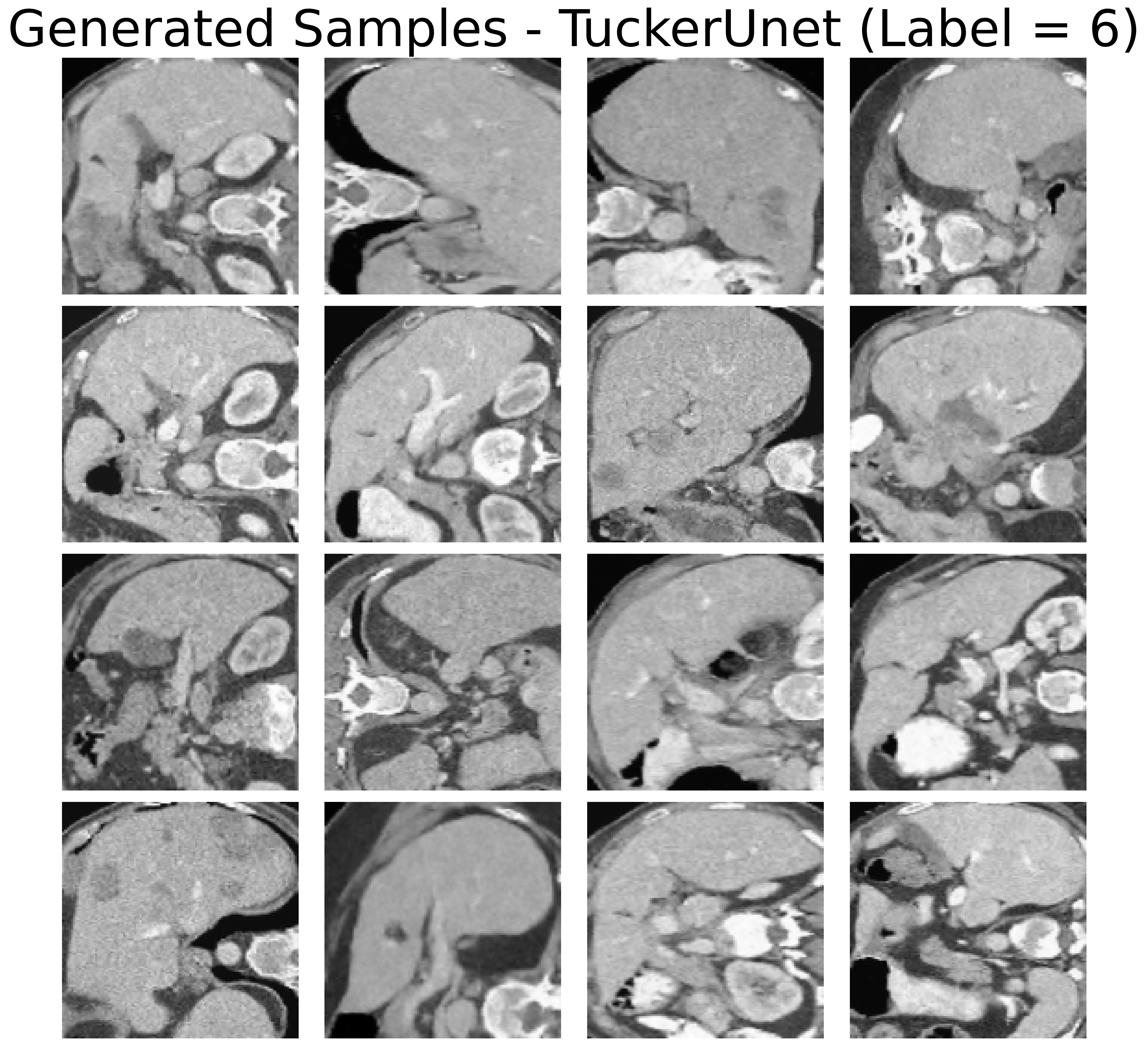
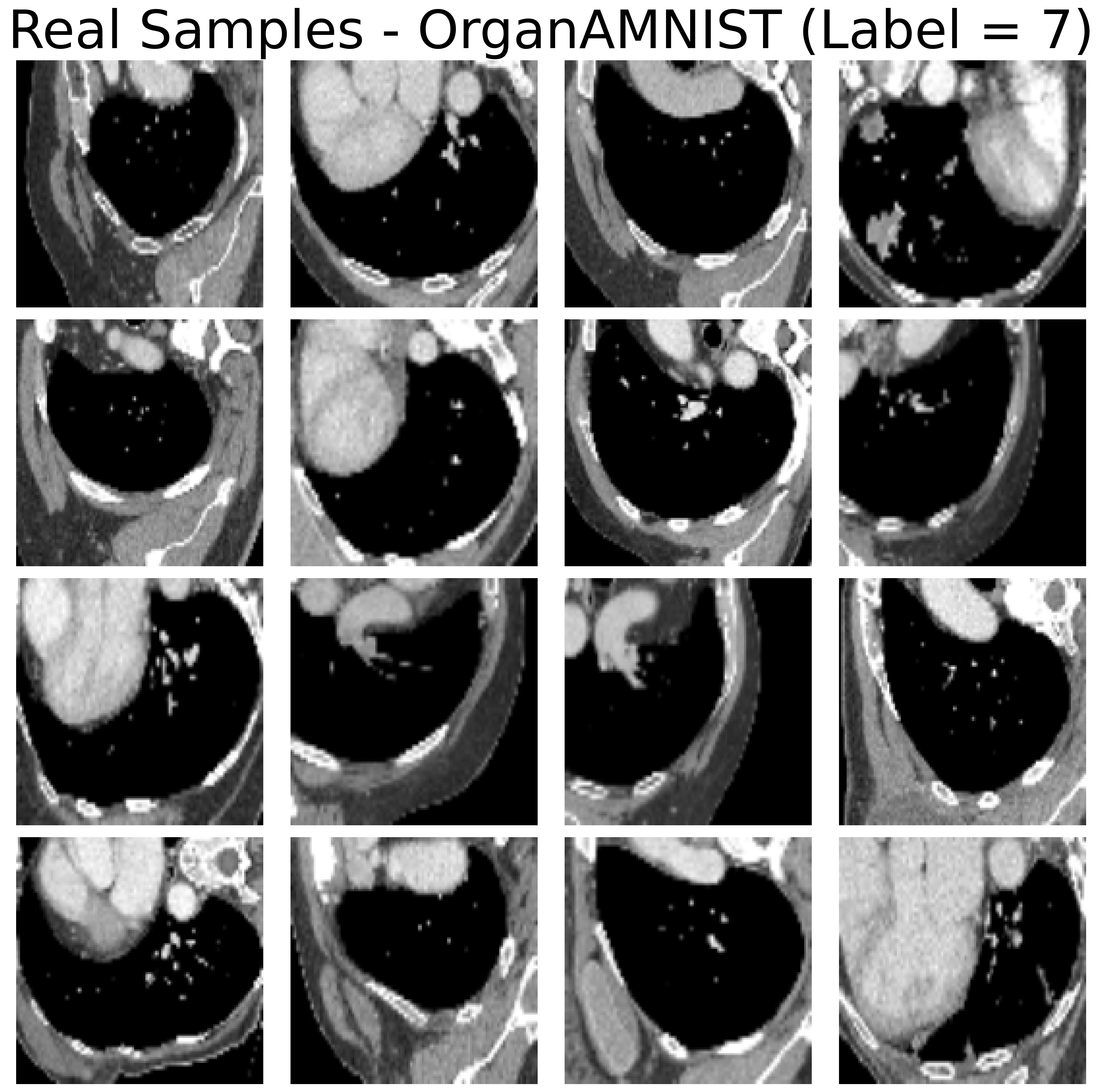
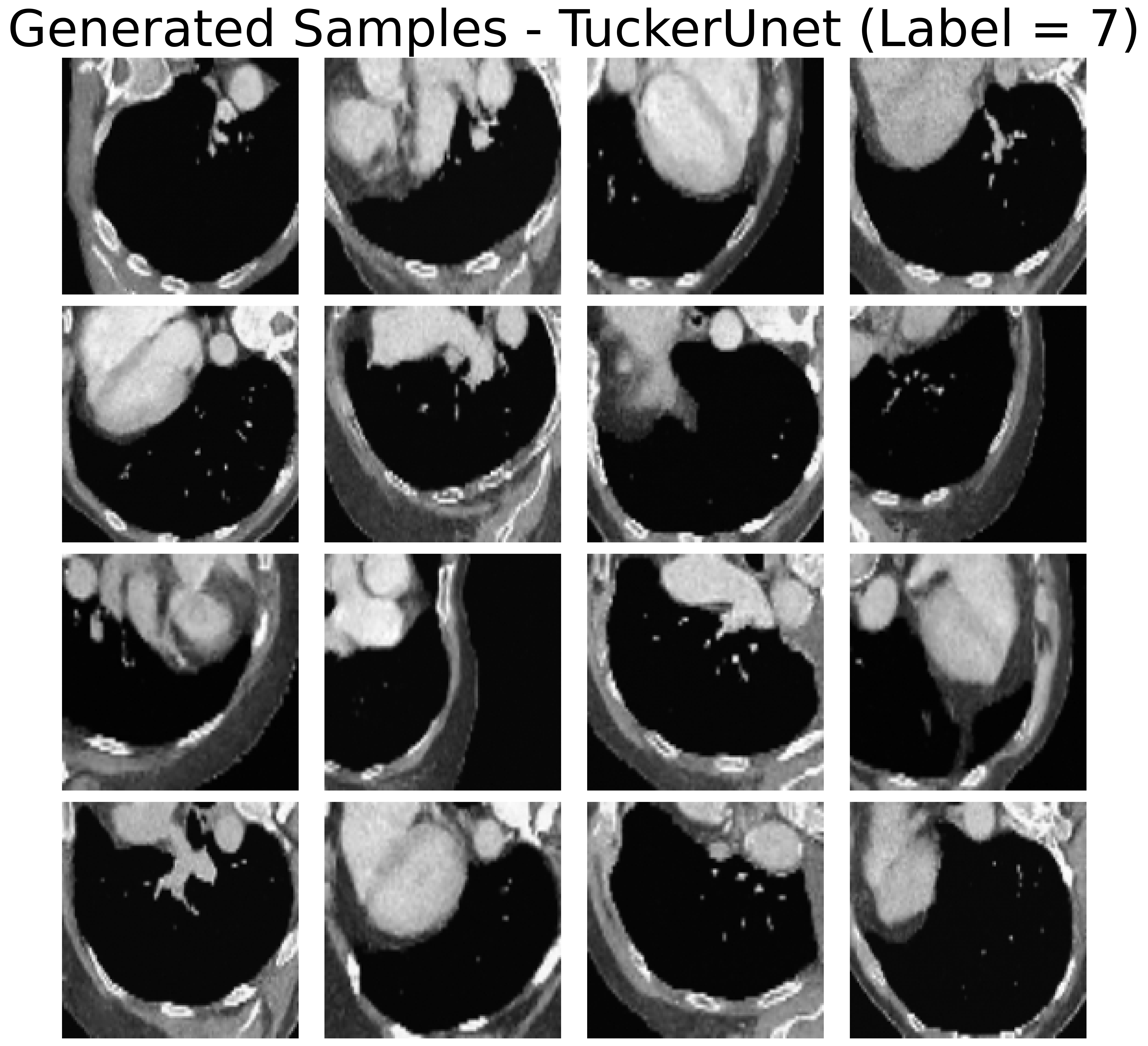
Figure 3: Real samples from the OrganAMNIST dataset and generated examples via low-Tucker-rank diffusion, demonstrating high-quality sample synthesis at significantly reduced computational cost.
In large-scale application, Tucker-Unet correctly captures high-impact spatial dynamics (e.g., major New York transportation hubs) and recovers the true distribution of events in challenging conditional sampling settings.
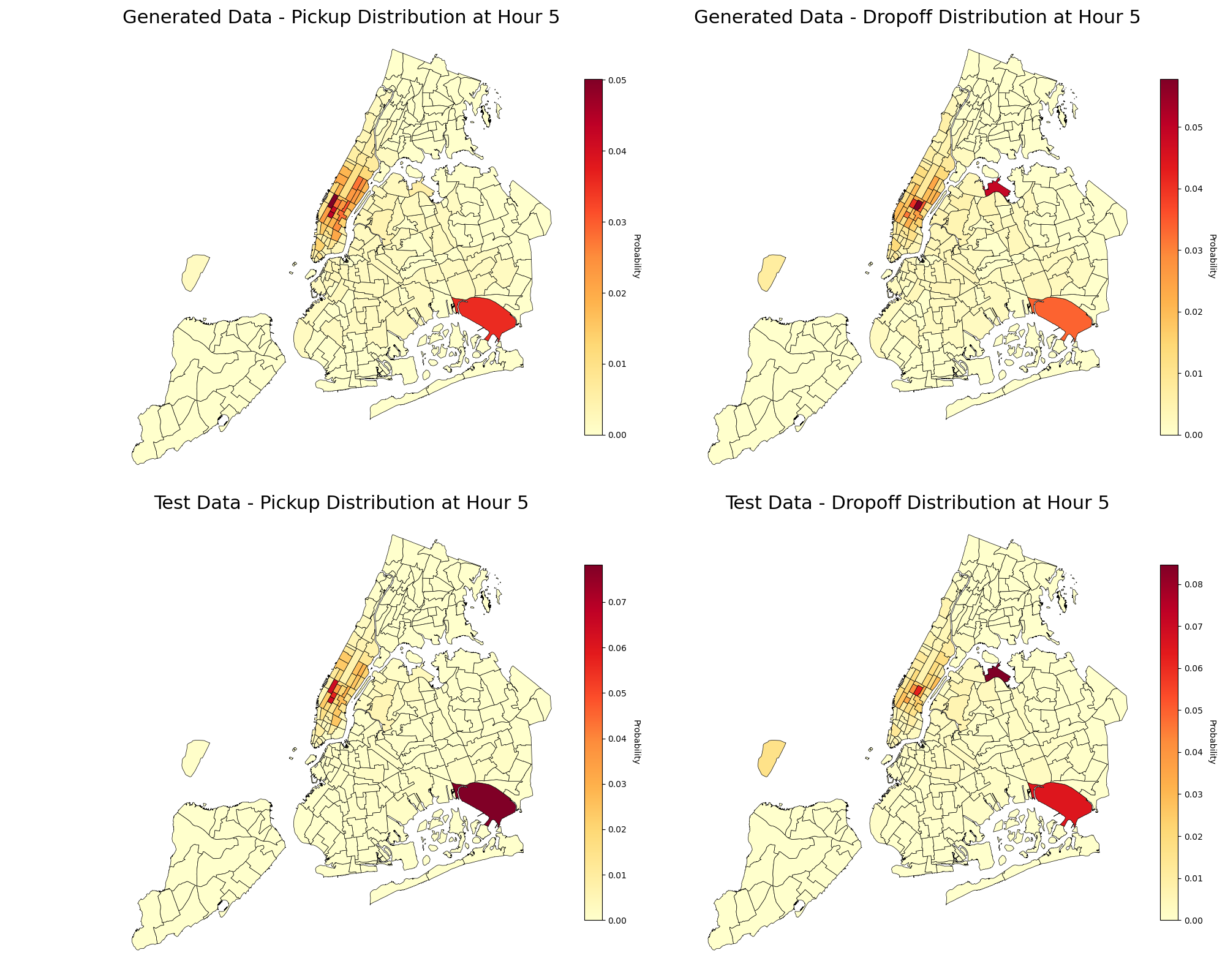
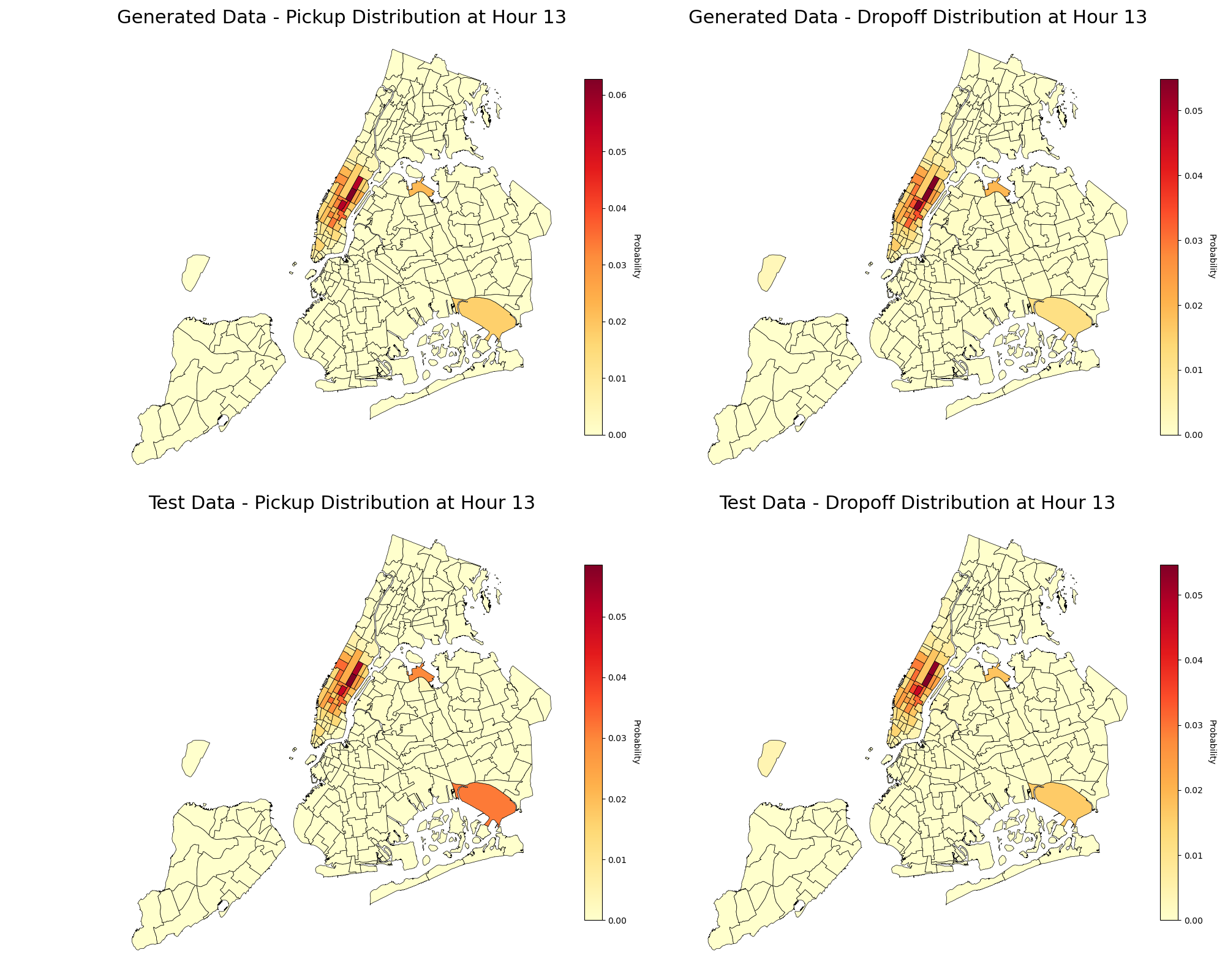
Figure 4: Hourly pickup (PU) and drop-off (DO) marginal distributions from generated and real data, demonstrating Tucker-Unet's ability to learn and replicate high-level urban mobility patterns.
Implications and Future Directions
The Tucker diffusion model substantially advances the state-of-the-art for generative modeling in high-dimensional tensor spaces, especially under sample-constrained and computationally limited regimes. The architecture's statistical efficiency and runtime reductions facilitate applications in medical imaging, spatiotemporal analytics, synthetic data generation for RL environments, and privacy-preserving simulation.
The approach effectively closes the gap between prior theoretical analyses of tensor factor models (PCA, SVD, Tucker/CP, etc.) and practical deep generative modeling, paving the way for more general structured diffusion models respecting domain symmetries and tensorial invariances.
Immediate research directions include: extension to higher-order conditional generative tasks (e.g., context-aware data augmentation, tensor completion/inpainting); integration with transfer learning and domain adaptation frameworks; and study of model selection for rank/tensor dimension hyperparameters under limited data.
Conclusion
This work rigorously formulates the Tucker Diffusion Model for high-dimensional tensor generation and demonstrates the statistical and computational optimality of the Tucker-Unet architecture. Through a suite of theoretical and empirical results, the paper establishes both practical and theoretical foundation for tensorized diffusion in structured statistical machine learning, significantly mitigating the traditional curse of dimensionality and unlocking new applications in scientific and industrial AI.

