- The paper presents a novel parallel execution paradigm that overlaps code generation with execution, drastically minimizing idle time.
- It introduces a three-stage pipeline combining token stream chunking, dynamic batching, and early error interruption to harness latency benefits.
- Empirical tests reveal latency reduction of up to 55% along with improved accuracy in error repair for partial code executions.
Parallelizing Code Generation and Execution in LLM Agents: An Analysis of "Executing as You Generate: Hiding Execution Latency in LLM Code Generation" (2604.00491)
Reframing LLM Code Execution: From Serial to Parallel Paradigms
LLMs have established a de facto workflow in code execution tasks where generation and execution strictly follow a serial paradigm: the LLM fully generates code, only then passes it to an interpreter for execution, and finally conditions further generation or handling on the output. This architecture replicates serial human coding but contrasts sharply with the intrinsic sequential, non-revising behavior of LLMs, which emit code token-by-token without mutation. The paper formalizes and systematically analyzes an alternative---the parallel execution paradigm---where LLM-produced code is dispatched for execution as soon as it becomes parseable and executable. The model proposes and realizes a pipeline that overlaps code generation and execution to hide execution latency.
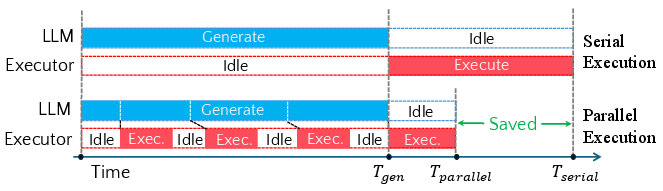
Figure 1: Comparison between serial and parallel execution: parallel execution overlaps the first three chunk executions with generation, reducing waiting time.
System and Theoretical Foundations for Parallel Execution
The authors formalize the parallel execution pipeline into three stages: generation (token production by LLM), detection (identification of complete and executable code chunks), and execution (dispatch to interpreter). Analytical latency bounds are derived. In the serial case, end-to-end latency is the sum of generation and execution times. In the parallel case, the majority of execution can be overlapped and hidden behind generation, especially when the generation process is the dominant bottleneck.
A closed-form characterization is provided for the pipeline’s latency envelope and speedup, interpolating between generation-dominated and execution-dominated regimes. With lightweight detection and batching, the only significant overhead relative to serial execution arises when per-chunk setup costs are nontrivial, which is typically negligible in modern interpreted sandboxed or persistent REPL environments. Under the established bounds, parallel execution cannot regress below serial execution and exhibits superlinear scaling as chunk granularity and batching are optimized.
Eager: Practical Implementation of Parallel LLM Code Execution
The paper introduces Eager, an end-to-end framework concretizing the parallel execution paradigm for LLM-driven Python code generation. The Eager architecture employs an AST-based chunker for granular detection of semantically and syntactically independent statements, employing lookahead and gating to ensure that code is only handed off for execution when it is a minimal, executable unit. The produced chunks are then dynamically batched and dispatched to a persistent execution environment to minimize invocation overhead.
Error handling is also parallelized: runtime failures trigger immediate generation interruption, which both reduces wasted computation and exposes failures sooner for repair.
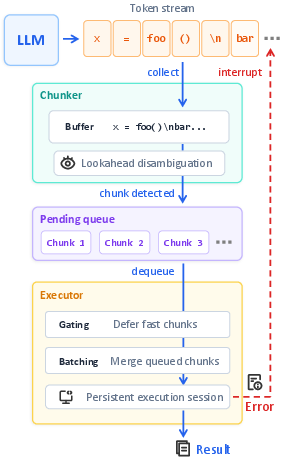
Figure 2: The Eager architecture consists of a streaming chunker parsing LLM token output, dynamic batching in an execution queue, and immediate error interruption feedback.
Empirical Evaluation: Benchmarks, LLMs, and Execution Settings
The empirical analysis spans four representative Python code generation benchmarks (DABench, DSBench, PandasPlotBench, and GitChameleon), seven LLMs (DeepSeek-V3.2, MiMo-V2-Flash, Qwen3-Coder, DeepSeek-Reasoner, GPT-4o-mini, GPT-5.1-Codex-Mini, Gemini-3.1-Flash-Lite), and three execution environments (local, Docker, Open Interpreter).
Evaluation proceeds both with replayed token streams (fixed token-per-second rates) and actual streaming LLM generation. Two primary latency metrics are used: Non-overlapped Execution Latency (NEL) and End-to-End Latency (E2EL).
Empirical results demonstrate that Eager reduces non-overlapped execution latency by 83--100% in all settings, nearly eliminating user-perceived waiting outside of the generation window. End-to-end latency reductions range up to 55% in error cases and up to 37% for error-free runs, with the largest benefits realized in generation-dominated tasks or with slower models.
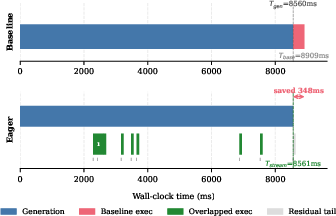
Figure 3: Example timeline showing Eager overlapping nearly all code execution with generation, saving 348 ms compared to serial execution.
The chunking mechanism is shown to be lossless: chunked and reassembled code is byte-identical to the LLM output, ensuring semantic preservation in deterministic settings. Latency reductions generalize robustly across model scales, benchmarks, and execution environments, with marginal differences in overhead between local and containerized settings.
Error Handling and Its Impact on Repair Success Rates
A striking empirical result is observed with Eager’s early error interruption: providing immediate error feedback and truncating post-failure code not only reduces wasted computation but also increases the success rate of subsequent code repair attempts. Across three data-centric benchmarks, error resolution rates are increased by up to 44 percentage points when attempting repair from the partial, pre-error prefix instead of the full, already-failed program. This is attributed to the prevention of anchoring the LLM on irrelevant, failed computation state. An exception is observed on version-specific code completion (GitChameleon), where context in the post-error suffix may be critical for correct repair.
Implications and Potential Future Directions
From the pipeline formalization and practical results, several implications emerge:
- Agentic Frameworks: Frameworks for autonomous LLM agents, which currently often require full code generation prior to execution, stand to benefit from integrating parallel execution interfaces, facilitating reduced latency throughout agentic workflows (including multi-file, multi-step pipelines).
- Programming Language Design: The pipeline’s dependence on incremental executability highlights that current language designs are mismatched with LLM emission characteristics. Future languages targeting LLM-based development can be refactored to provide streamable, unambiguous statement boundaries, or built-in incremental execution semantics.
- LLM Training and Prompt Engineering: Current LLMs are unaware that their outputs are executed incrementally. Incorporating streamability and executability into pretraining, finetuning, or prompting can further optimize overlap and minimize detection ambiguity.
- LLM Repair and Self-Debugging: Early error interruption pivots into a better exploration-exploitation trade-off for iterative program repair, as demonstrated by enhanced post-error recovery rates. This finding is relevant to dynamic repair, self-debugging, and iterative refinement workflows.
Conclusion
The work establishes a rigorous system and theoretical basis for parallel code execution in LLM agents, presents a robust and generalizable implementation (Eager), and experimentally validates sizable reductions in execution-induced user latency. The parallel execution paradigm is general, composable with agentic prompting, and highlights new directions in language design, LLM training, and integrated agent frameworks for software engineering tasks. This paradigm is expected to become a foundational primitive in next-generation LLM-based coding systems, particularly for interactive and low-latency environments.

