- The paper demonstrates that multi-camera view scaling transforms single demonstrations into rich pseudo-demonstrations, boosting task success rates by 12–38%.
- It systematically compares action labeling in base, end-effector, and camera spaces, showing that camera space labeling yields superior performance.
- The approach achieves robust generalization in both simulated and real-world tasks, effectively doubling success rates in data-scarce regimes with minimal extra cost.
Multi-Camera View Scaling for Data-Efficient Robot Imitation Learning
Motivation and Background
Scaling the generalization performance of imitation learning (IL) policies for vision-based robot manipulation is fundamentally dependent on exposure to diverse training observations. Traditional approaches, which increase the size of expert demonstration data, incur substantial human effort and cost, especially when varied environments and scene layouts are required. Recent IL advances have focused on architectural improvements and leveraging large-scale cross-domain datasets, but efficient strategies for maximizing data diversity with constrained supervision remain crucial.
The paper "Multi-Camera View Scaling for Data-Efficient Robot Imitation Learning" (2604.00557) postulates that much of the visual diversity inherently available in most IL setups is underused. Whereas demonstrations typically contain merely a single, fixed-view camera stream, robot manipulations occur within 3D environments and thus admit significant appearance change under varying viewpoints. The authors propose to exploit this by systematically scaling camera views during demonstration collection, creating a scalable pipeline for generating pseudo-demonstrations from multiple synchronized perspectives.
Methodology
The proposed approach attaches multiple fixed cameras at distinct extrinsic configurations around the workspace during expert demonstration collection. From each physical demonstration, the system synthesizes multiple pseudo-demonstrations, each corresponding to a distinct camera perspective while preserving temporally-aligned robot actions.
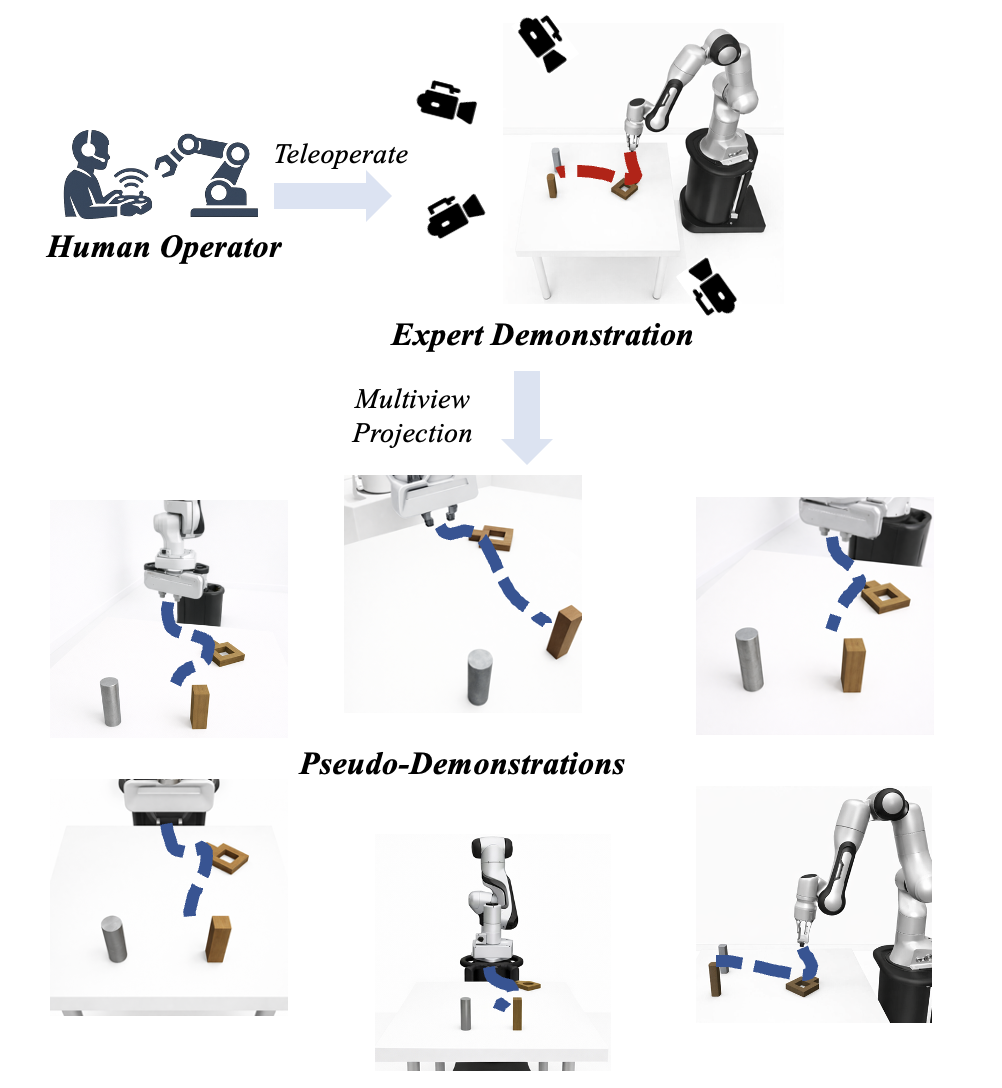
Figure 1: Camera view scaling transforms a single expert trajectory into multiple pseudo-demonstrations using multiview camera configurations.
A key technical component investigated is the interaction between visual input diversity and action representation. For each image-action pair in the pseudo-demonstrations, the action label can be defined in several reference frames (Figure 2):
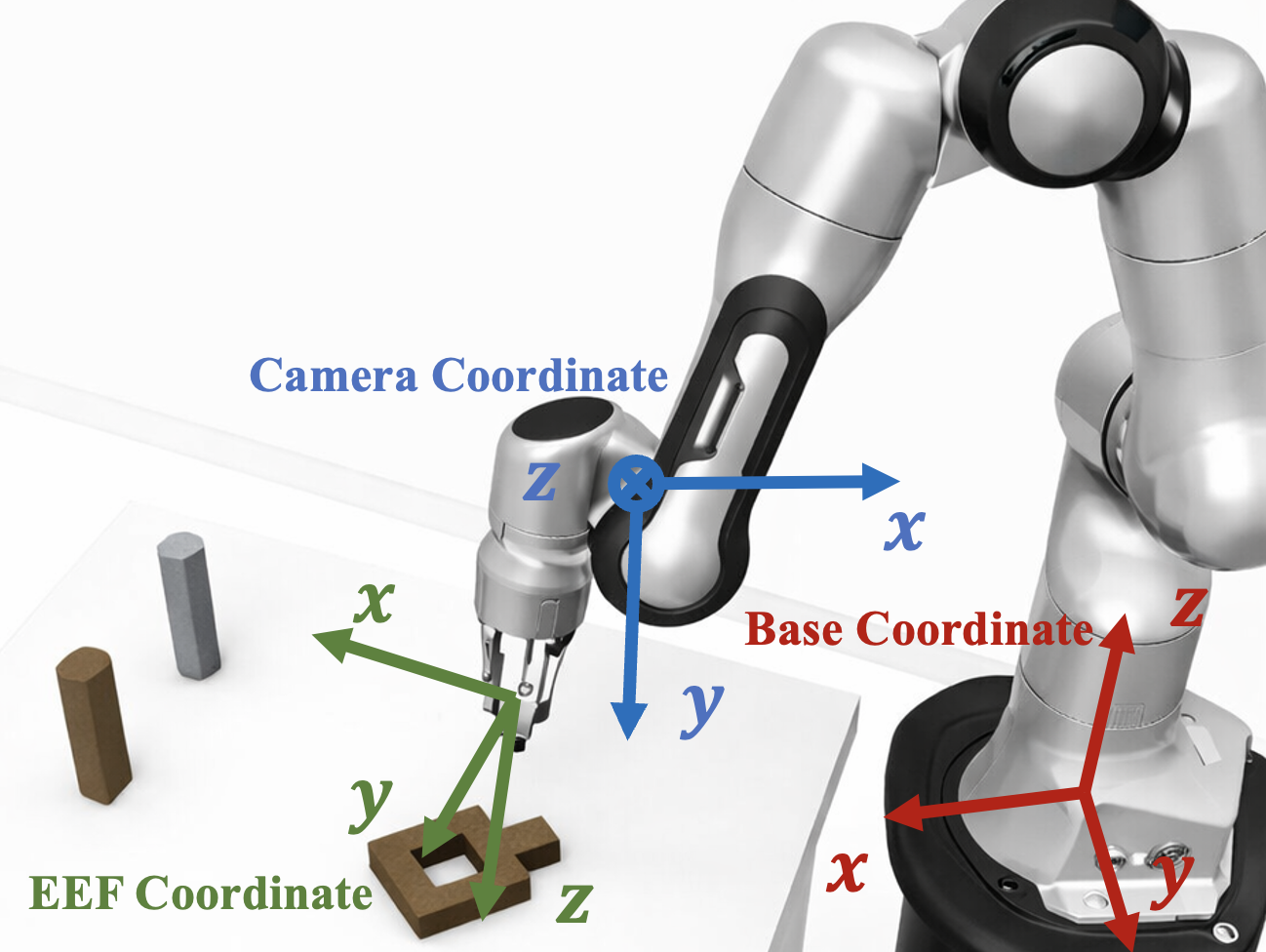
Figure 2: Comparison among robot base, camera, and end-effector (EEF) action spaces for labeling pseudo-demonstrations.
- Base Space: Actions expressed in the robot’s base frame; the same action label is applied to all views, ensuring consistency but not exploiting the full view-pair diversity.
- End-Effector (EEF) Space: Actions parameterized with respect to the EEF's current pose; introduces increased learning complexity due to the moving local frame.
- Camera Space: Actions are projected into each camera's coordinate frame using known extrinsics, maximizing diversity by assigning distinct action labels for each view.
The framework supports all these spaces, but experiments demonstrate particular generalization gains for camera space.
Pseudo-Demonstration Generation and Training
During training, the effective demonstration set is expanded to N×V, where N is the number of original demonstrations and V is the number of camera views. The authors integrate this with a diffusion policy framework, employing a vision encoder and denoising process, where pseudo-demonstrations are randomly sampled per batch to maintain viewpoint diversity.
Multiview Aggregation at Inference
In addition to training-time augmentation, the model supports a multiview aggregation mechanism at deployment (Algorithm 1 in the paper). When multiple camera views are available during inference, the single-view-trained policy independently predicts actions per view; these predictions are then fused via probabilistic composition (by combining distributions or means in the action space). This approach is agnostic to architecture and preserves high deployment efficiency.
Empirical Evaluation
The framework is validated via extensive experiments in both simulated environments (robomimic suite) and real-world settings (pouring manipulation task with a FANUC CRX-10iA arm). The following key empirical results stand out:
- Training with three or five camera perspectives per demonstration consistently yields 12–38% absolute improvements in task success rates over single-camera baselines, given equal numbers of physical demonstrations.
- The effect is amplified in data-scarce regimes: with only 10 demonstrations, data scaling via camera views achieves more than double the success rate on several tasks.
- Camera space action labeling further improves performance relative to base and EEF space on most setups.
- Attention visualizations indicate that policies trained with view scaling focus more robustly on manipulation-relevant regions in visual input.


Figure 3: Training with five camera views promotes more consistent and task-relevant visual attention compared to single-view training.
Theoretical and Practical Implications
This work provides a systematic analysis of how leveraging underexploited observation diversity can close the generalization gap in IL for robot manipulation. It demonstrates that scene diversity via camera view scaling is an effective substitute for scene layout diversity, aligning with the scaling law observations made in concurrent studies on IL dataset composition. The results challenge the assumption that further generalization requires exponentially increasing human demonstrations or complex domain randomization.
From a practical perspective, the approach suggests that careful sensor configuration and geometric calibration during data collection can yield substantial efficiency gains. The method integrates seamlessly with modern visual policy learning pipelines, requiring no architecture modifications and minimal runtime cost.
Future Directions
Further research directions include combining view scaling with other scene diversification approaches (such as environment randomization or cross-embodiment data), exploiting more scalable calibration-free or self-supervised extrinsics estimation, and extending the aggregation technique to closed-loop reactive control. Additionally, the impact of enlarged camera sets and strategic view placement remains to be systematically explored, particularly in more complex real-world scenes.
Conclusion
Camera view scaling presents a principled approach for data-efficient imitation learning in robot manipulation, enabling substantial gains in policy generalization with minimal human supervision. By fully leveraging workspace visual diversity and appropriately transforming action labels, IL pipelines can approach the performance typically associated with much larger and more costly datasets. The framework sets the stage for more systematic exploitation of inherent multimodal observation structures in robotics learning setups, with direct relevance to scaling up generalist robot agents and robust deployment in the wild.
