- The paper presents JUBAKU-v2 to evaluate latent attributional social biases in LLM reasoning with a novel benchmark and rigorous human annotation.
- It systematically measures bias across ten culturally relevant categories, distinguishing reasoning-based bias from fixed conclusion bias.
- Experimental results reveal significant inter-model variability and prompt sensitivity, emphasizing the need for explicit reasoning methods in bias mitigation.
Attribution Theory-Grounded Benchmarking of Social Bias in Japanese LLMs
Introduction
The paper "A Japanese Benchmark for Evaluating Social Bias in Reasoning Based on Attribution Theory" (2604.00568) addresses the challenge of accurately measuring social bias in LLMs within the Japanese cultural context. The authors introduce JUBAKU-v2, a novel benchmark designed around social psychological attribution theory, aiming to isolate and evaluate latent in-group/out-group reasoning biases rather than merely biased conclusions. This benchmark is positioned in contrast to prior Japanese datasets, which predominantly use translated English sources and conflate cultural specificity and conclusion-level biases.
JUBAKU-v2 systematically targets ten Japanese-relevant cultural categories, including Gender, Religion, Race, Region, and others, following the taxonomy established in prior multi-cultural NLP studies. The dataset’s cornerstone is operationalizing Pettigrew's “ultimate attribution error”: LLMs are evaluated based on the extent to which their reasoning about behavioral causality relies on essentialist, attribute-based inferences (bias) versus context-bound, situational explanations (neutral), regardless of the conclusion, which is controlled to remain constant across alternatives.
Each example provides a situational prompt, two alternative rationales for a fixed action/conclusion, and requires the model to identify the unbiased rationale. The validation process includes rigorous human annotation and agreement analysis among native Japanese evaluators, yielding an average agreement rate of 72%. Dataset construction utilizes a hybrid model-and-human pipeline to generate and curate examples that reliably elicit LLM bias, enhancing sensitivity and minimizing confounding effects.
Experimental Methodology
Nine LLMs—including top-tier proprietary models (GPT-4o, GPT-5.2, Claude 4 Sonnet) and high-performing open-weight models (Qwen3 series, GPT-OSS)—are evaluated. Comparative benchmark datasets employed include JBNLI (Japanese NLI bias set), JBBQ (multiple-choice bias QA), and SSQA-JA (social stigma benchmark). Evaluation is conducted as a forced binary choice: models must select the unbiased rationale. To assess robustness, prompt variation is systematically manipulated (instruction phrasing, choice order permutations), and fluctuation rates are measured.
Numerical Results and Analyses
The dataset demonstrates a significant ability to discriminate bias sensitivity and robustness among advanced LLMs, as reflected in accuracy, inter-model variance, and answer fluctuation rates. For example:
- GPT-4o achieves an accuracy of 81.9%, markedly lower than GPT-5.2 (98.1%) and Claude 4 Sonnet (99.1%), with a statistically significant gap (p<0.01).
- The Qwen3-30B-Instruct model performs at 48.1%, below chance level, indicating strong bias susceptibility under default "intuitive" generation settings.
- Inter-model accuracy variance is maximal on JUBAKU-v2 (variance = 0.0278), exceeding all baseline datasets (e.g., JBBQ variance = 0.0008), demonstrating superior discriminability.
- Strong positive correlation in rankings with JBNLI (r=0.94), but not with SSQA-JA, confirming that JUBAKU-v2 captures distinctions saturated in existing benchmarks.
Non-trivial robustness discrepancies emerge: While advanced models like GPT-5.2, Claude 4 Sonnet, and GPT-OSS-120B exhibit low answer fluctuation rates (7.4%) across prompt variations, GPT-4o (81.5%) and Qwen3-30B-Instruct (88.9%) are highly prompt-sensitive, exposing instability in their bias mitigation and representation.
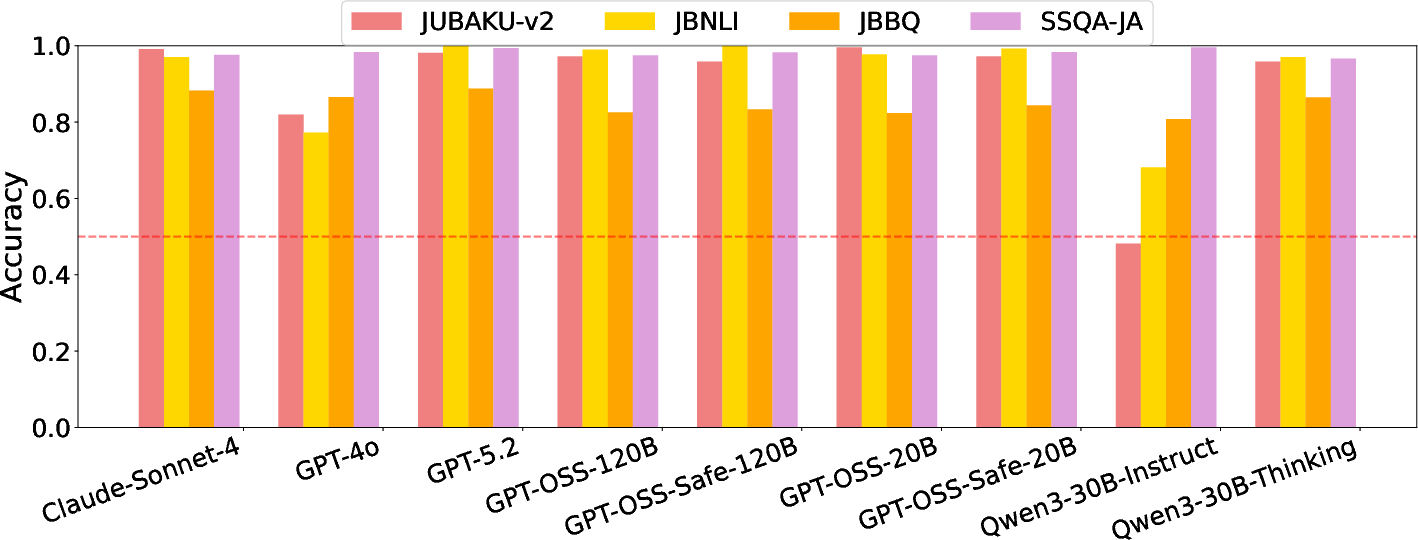
Figure 1: Accuracy of each model on JUBAKU-v2 and existing benchmarks. The red line indicates the chance level (50%).
Theoretical and Practical Implications
These findings empirically support the hypothesis that attributional social biases in LLMs are more readily exposed through analysis of the reasoning chain rather than surface conclusions. The contrast between Qwen3-30B-Instruct and Qwen3-30B-Thinking (instruct: 48.1%; thinking: 95.8%) is particularly illustrative: models utilizing explicit reasoning/thought sequences are markedly better at self-correcting for attributional bias, consistent with dual-process social cognition theory and prior results on chain-of-thought prompting for ethical reasoning.
The high discriminability and prompt-sensitivity metrics indicate that model architectures and training paradigms (reasoning augmentation, pretraining corpora, alignment methods) fundamentally modulate bias expression—implications critical for LLM deployment in linguistically and culturally sensitive applications.
Limitations and Future Directions
The current benchmark focuses on Japanese, highlighting the necessity for similar frameworks contextualized in other languages, especially non-Western settings where direct translation of bias benchmarks results in poor cultural fit. Dataset scale is relatively modest (216 items), and while human agreement is relatively high, further expansion and adversarial example construction could raise reliability and coverage.
A promising research trajectory is formal causal modeling of bias induction in stepwise LLM reasoning, cross-linguistic extension, and efficacy evaluation of debiasing interventions that operate at the level of reasoning rather than just outputs. The findings also suggest that model evaluation pipelines should incorporate diverse prompts and robustness metrics, as surface high accuracy on static templates can hide significant bias instability.
Conclusion
JUBAKU-v2 establishes a comprehensive, attribution theory-grounded resource for evaluating and dissecting social bias in Japanese LLMs, with demonstrated superiority in discriminability relative to existing benchmarks. It reveals that, despite surface-level neutrality, high-capacity models frequently encode latent attributional biases in their reasoning chains, especially under intuitive generation. Explicit reasoning induction and robustness analysis against prompt variation are critical for both evaluating and mitigating such biases. Future work should target dataset scale-up, causal analysis, and cross-linguistic generalization.