- The paper establishes a 3D scaling law framework that quantifies the trade-off between pretraining tokens and retrieval data in language models.
- It demonstrates that retrieval is most effective in low-to-mid pretraining regimes, with diminishing marginal gains as model size increases.
- The study provides practical guidelines for corpus allocation by highlighting the substitutability between pretraining and retrieval under fixed data constraints.
Scaling Laws and Data Allocation in RAG-Aware Pretraining
Introduction
The paper "To Memorize or to Retrieve: Scaling Laws for RAG-Considerate Pretraining" (2604.00715) establishes a quantitative framework for optimizing the trade-off between parametric (memorization via pretraining) and non-parametric (retrieval-augmented) knowledge in LLM training under fixed data constraints. By systematically varying model size, pretraining token counts, and external retrieval corpus scale across OLMo-2-based LMs (30M–3B parameters), the authors elucidate the conditions under which retrieval can substitute for pretraining and provide task-specific guidance for RAG-aware LM development.
Scaling Laws for Parametric and Retrieval-Augmented Pretraining
The empirical results demonstrate canonical power-law scaling for parametric pretraining: increasing model parameters and training tokens reliably reduces loss, albeit with diminishing returns. The paper fits loss surfaces using formulations such as
L(N,D)=A(109N)−α+B(109D)−β+L0
and extends this to include retrieval via an additive logarithmic gain term:
L(N,D,R)=A(109N)−α+B(109D)−β−Clog(1+η109R)+L0
where N is model size, D is pretraining tokens, and R is retrieval corpus size. These 3D scaling surfaces are fit on multiple downstream benchmarks, with low CV ARE (<8% for most tasks), validating the model's capacity to capture retrieval-augmented scaling behavior. Importantly, retrieval provides diminishing returns, both in absolute loss reduction and marginal gains per retrieved token.
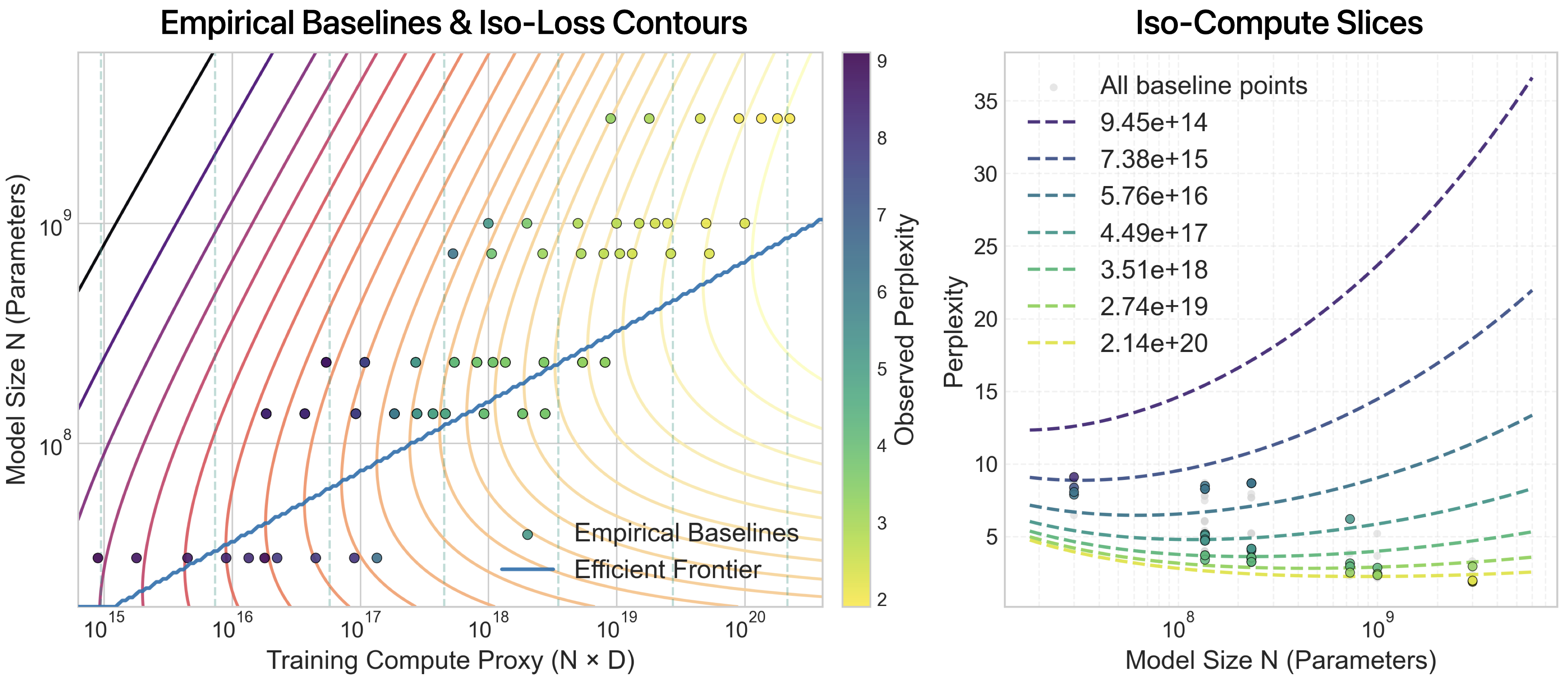
Figure 1: Power-law parametric scaling, with iso-loss contours and compute-efficient frontier; scaling fits match empirical observations across model sizes and data budgets.
Trade-Offs and Substitutability Between Pretraining and Retrieval
The crux of the paper is the joint optimization of pretraining and retrieval allocation under a fixed corpus budget. The authors quantify substitutability (σ) – the number of pretraining tokens that can be replaced per retrieval token – and the marginal benefit of retrieval (κ) – the loss reduction per unit of retrieved data. The results show clear regime dependence: retrieval is most effective in low-to-mid pretraining regimes and for smaller models, where capacity saturation has not been reached. Substitutability becomes significant (each retrieval token replaces multiple pretraining tokens) when pretraining tokens per parameter exceed ∼4.
As model size increases, both σ and κ decrease, indicating diminishing marginal utility of retrieval. The efficiency of retrieval is highest for knowledge-centric tasks, and minimal or even negative for reasoning-heavy tasks where internal computational capacity is the limiting factor, not factual recall.

Figure 2: Allocation trade-off curves. Performance varies smoothly along the pretraining–retrieval frontier; smaller models achieve substantial gains with retrieval, large models exhibit saturation.
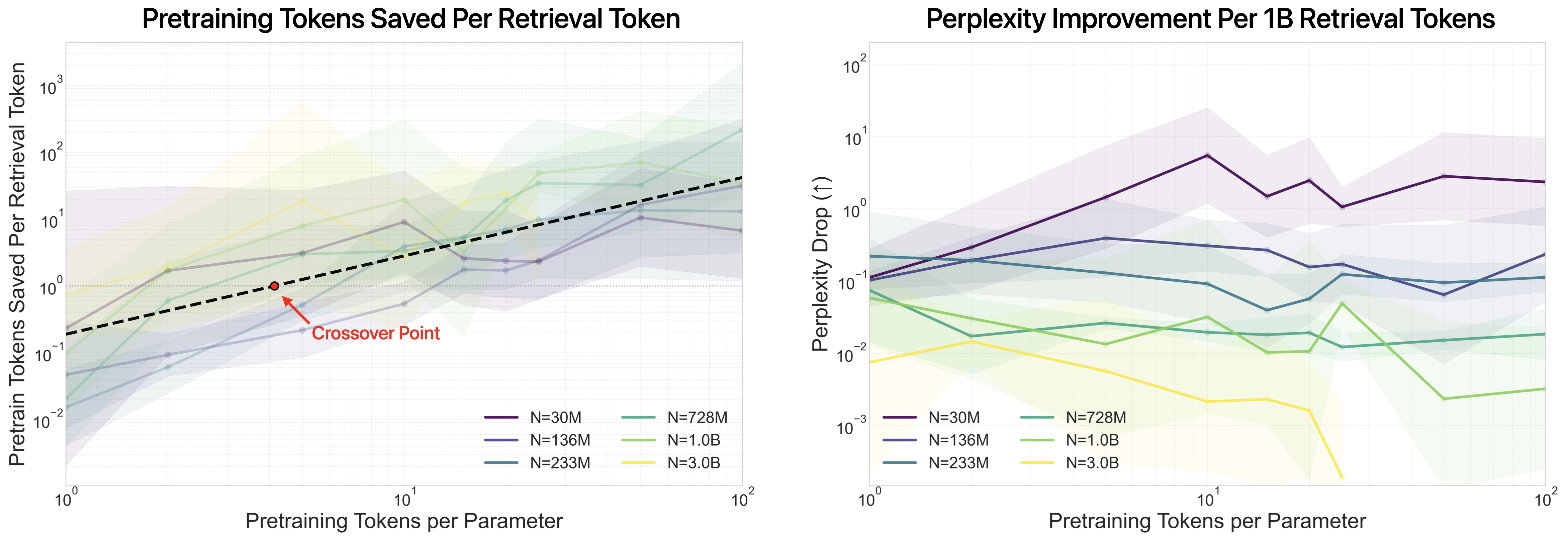
Figure 3: Substitutability and marginal gains of retrieval. Left: retrieval becomes an efficient substitute for pretraining above critical scale; right: marginal benefit peaks for small models and declines with scale.
The paper further isolates the impact of retrieval quality by varying the query formulation and evaluating oracle-style retrieval scenarios. Enhanced query constructs (e.g., including gold answers or answer choices) yield incremental gains but do not fundamentally alter the scale-dependent retrieval–pretraining trade-off. In knowledge-heavy tasks, improved retrieval precision provides stronger anchoring of factual cues, while in reasoning-heavy domains retrieval is rarely beneficial and may even distract the model.
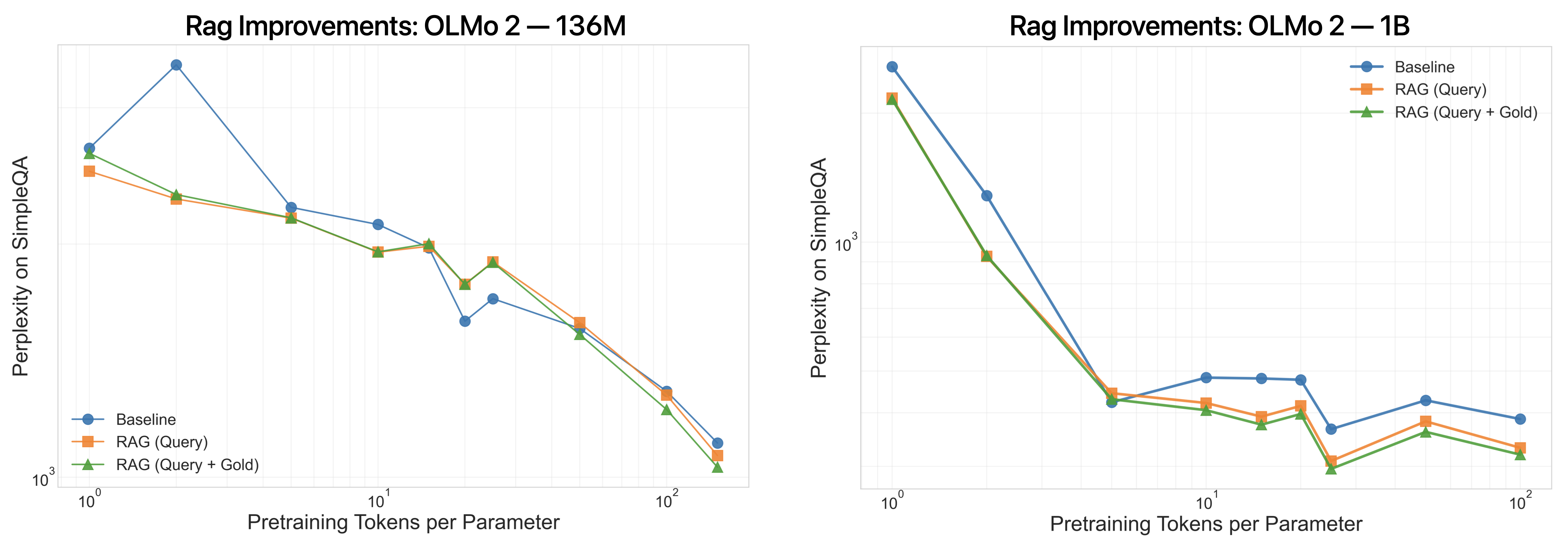
Figure 4: Effect of query formulation on retrieval-augmented performance; oracle queries provide incremental improvement, but scaling trends persist.
Benchmark-Specific Scaling and Fit Robustness
Scaling law fits are benchmark-specific but exhibit robust predictability across held-out model sizes (LOMO error) and random seeds, with knowledge-driven tasks such as ARC or OpenBookQA showing stable fits and reasoning-centric benchmarks displaying higher variance. The calibration plots confirm strong predictive alignment between fitted 3D scaling laws and observed perplexity trends, further motivating the joint optimization of parametric and non-parametric data allocation.
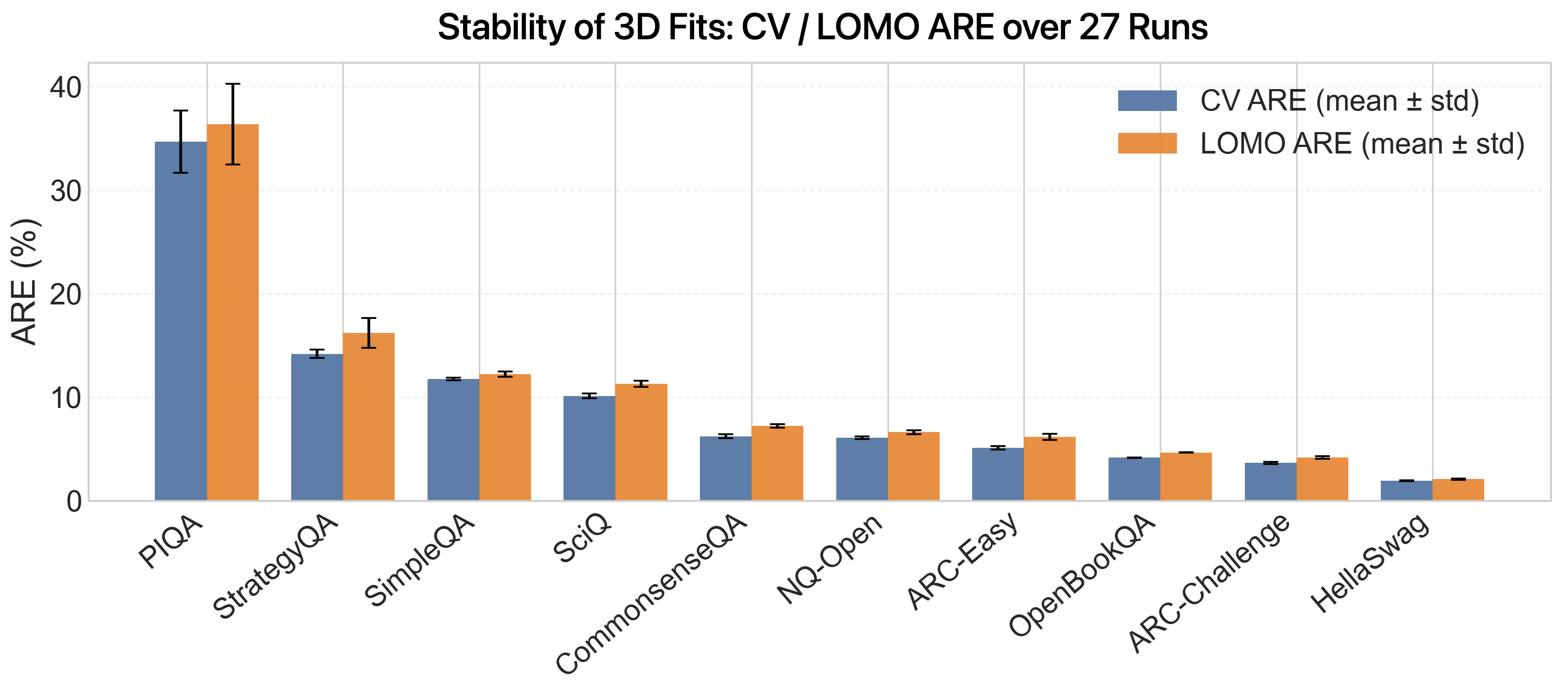
Figure 5: Stability of scaling law fits across seeds and model families. Low variance indicates robust scaling structure.
Implications for Model and System Design
The results demonstrate that retrieval and pretraining must be considered as competing mechanisms for corpus utilization, rather than as independent system augmentations. Retrieval is most valuable in data-constrained, undertrained, or small-LM regimes, where parametric capacity is insufficient for comprehensive factual recall. As models scale up or approach pretraining saturation, retrieval's marginal utility declines, and optimization should prioritize internalization via pretraining.
The practical implications are substantial for efficient LM system design, particularly for SLMs or deployments with strict data and computational budgets. Explicit partitioning of corpora for parametric learning versus external retrieval can yield compute-efficient and memory-efficient architectures. Theoretical implications involve a unified treatment of scaling laws, suggesting retrieval is not a monotonic or universal substitute for memorization but a conditional, scale- and task-dependent resource.
Limitations and Future Directions
The study fixes retriever type and chunking strategy, which may understate maximum achievable gains for advanced retrieval pipelines or adaptive methods. The scaling law framework could be extended to incorporate retrieval quality metrics, relevance estimation, or adaptive allocation schemes (e.g., reranking, learned filtering). Unification across benchmarks would also facilitate generalization of scaling law parameters and explainability regarding retrieval sensitivity or reasoning burdens.
Inspired by analogies to human cognition, future research could explore purposeful allocation of abstract reasoning to pretraining versus long-tail factual knowledge to retrieval within hybrid memory architectures. More principled scheduling of data exposure and adaptive retrieval could further enhance sample efficiency.
Conclusion
This paper provides an authoritative quantification of the pretraining–retrieval trade-off in RAG-aware LM training, supported by a 3D scaling law framework and robust empirical analysis across diverse model sizes and tasks. The results delineate the scale-dependent substitutability, marginal gains, and practical limitations of retrieval augmentation as a complement to parametric learning. The insights have immediate practical value for efficient architecture design and corpus allocation, and lay the foundation for future extensions in retrieval pipeline optimization and scaling law theory.

