A remark on an error analysis for classical and learned Tikhonov regularization schemes
Published 1 Apr 2026 in math.NA | (2604.00759v1)
Abstract: This paper presents an error analysis of classical and learned Tikhonov regularization schemes for inverse problems. We first demonstrate, both theoretically and numerically, that using a fixed regularization parameter across varying noise levels-which is a common miss-specification in practice-has only a mild impact on the reconstruction error. As a special case, we then investigate scenarios where the true data resides in an unknown finite-dimensional subspace. Here, our results lead to an empirically supported strategy for estimating the unknown dimension based on numerical experiments. Finally, we examine the approach that motivated this study: a method where a sparsity-promoting term is learned from denoising tasks and subsequently applied to general inverse problems via a simple heuristic parameter selection. The corresponding error analysis is initially developed using classical concepts and subsequently refined through a more detailed investigation of the discretized setting.
The paper quantifies how mis-specifying the Tikhonov parameter mildly influences reconstruction error through analytic and numerical methods.
The paper extends classical error analysis to low-dimensional subspaces, providing procedures to empirically estimate the intrinsic dimension of the signal.
The paper examines the stability of learned regularizers using sparsifying transforms, contrasting finite- and infinite-dimensional settings.
Error Analysis of Classical and Learned Tikhonov Regularization for Inverse Problems
Overview and Motivation
The paper "A remark on an error analysis for classical and learned Tikhonov regularization schemes" (2604.00759) provides a rigorous error analysis of both classical and learned Tikhonov regularization methods in the context of linear inverse problems. The analysis clarifies the effect of regularization parameter misspecification, explores error behavior under model misspecification (e.g., ground truth lying in an unknown subspace), and investigates the theoretical underpinning and stability of learned regularizers trained for denoising but deployed for general inverse problems.
The main contributions are:
Analytic and numerical quantification showing that suboptimal selection of the Tikhonov regularization parameter with respect to noise level has only a mild effect on reconstruction error.
Extension of classical error analysis to the setting where the signal lies in a low-dimensional but unknown subspace, including procedures for empirically estimating this intrinsic dimension.
Worst-case error analysis for learned variational regularization methods, particularly those employing a learnable sparsifying transform, with theoretical clarification of the corresponding stability properties in finite- and infinite-dimensional settings.
Theoretical Error Analysis of Tikhonov Regularization
Classical Tikhonov regularization for linear inverse problems is defined as xαδ=(A∗A+αI)−1A∗yδ, where A is a compact operator between Hilbert spaces, yδ is noisy observation, and α>0 is the regularization parameter.
The worst-case reconstruction error is considered: wc(α,δ)=∥yδ−y†∥≤δ,Ax†=y†sup∥Tαyδ−x†∥
The analysis yields closed-form upper bounds (see Equation (4) in the paper), and identifies the optimal parameter choice α(δ)∼δ/ρ (with ρ a source norm), aligning with classical results. The novel insight is the analytic characterization of the relative error increase incurred by applying a regularization parameter optimized for a reference noise level δˉ to data with different, potentially mismatched, noise level δ.
The resulting bound,
wc(α(δ),δ)wc(α(δˉ),δ)=21(λ+λ1),with δ=λδˉ,
demonstrates that—even for large noise level mismatch—the relative error grows only as A0 rather than exponentially or catastrophically.
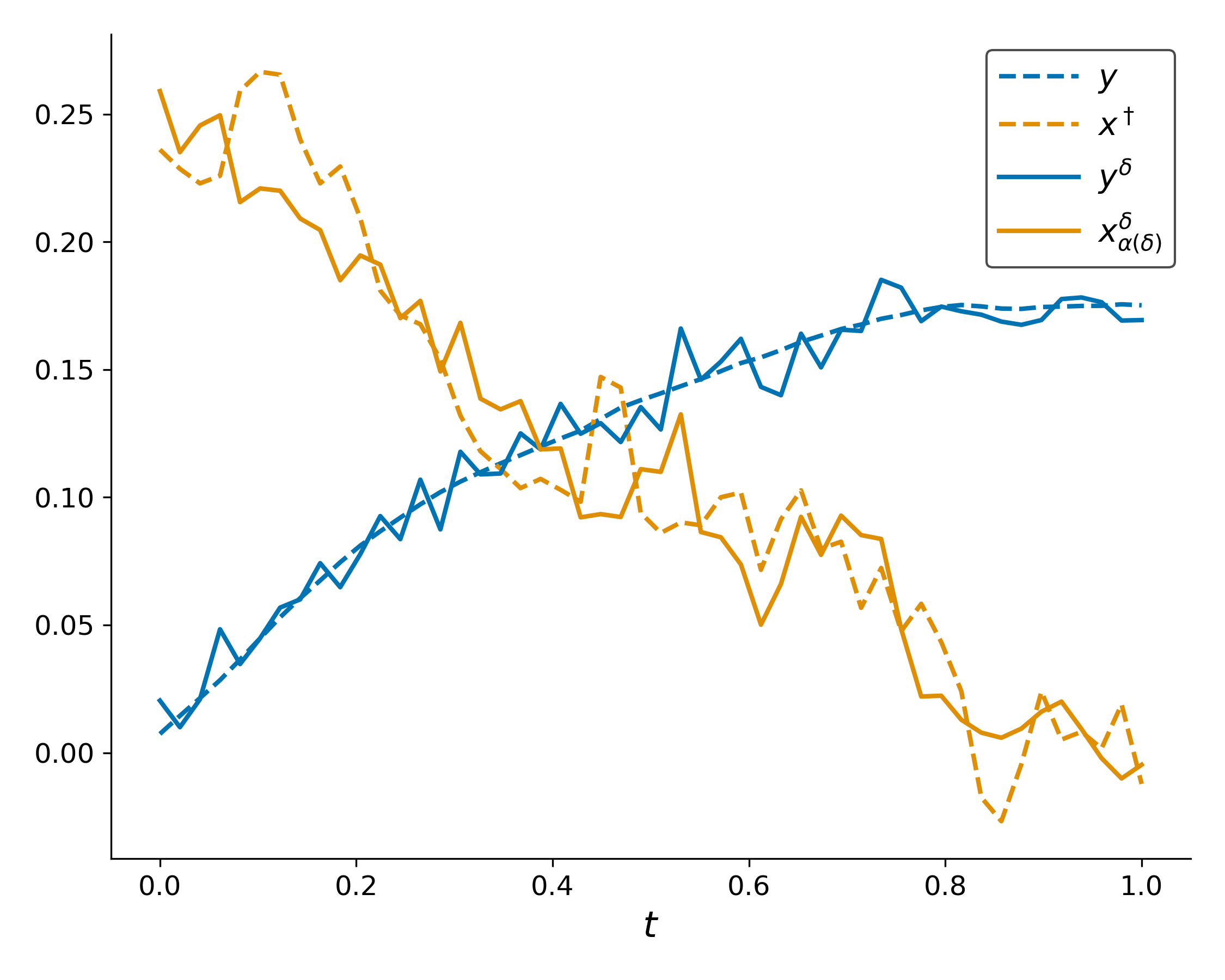
Figure 1: Test data A1 for both inverse problems with noise-free and noise-perturbed measurements A2 and corresponding Tikhonov reconstruction A3.
This finding is further substantiated by numerical experiments on image reconstruction with Radon and integration operators, showing close alignment of empirical errors with analytic worst-case bounds across a wide range of noise and regularization parameters.
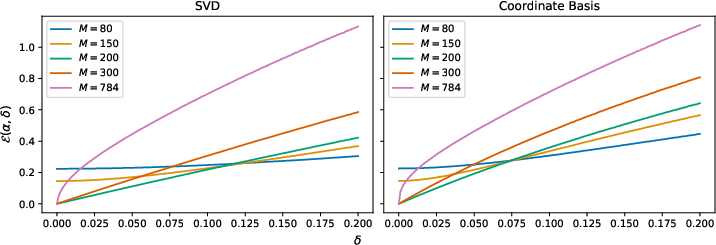
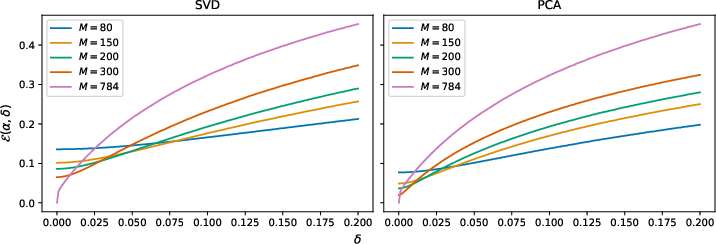
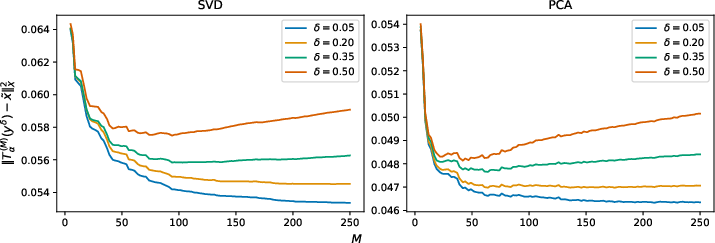
Analysis for Data in Unknown Low-dimensional Subspaces
The paper extends the worst-case error analysis to cases where the true solution A4 is restricted to a (unknown) finite-dimensional subspace A5 of A6, with A7. This structure is commonly exploited (either implicitly or explicitly) in learned regularization and forms the backbone of data-driven imaging pipelines.
In this regime, the error behavior of Tikhonov regularization as a function of the regularization parameter A8 decouples for A9 and yδ0, yielding potentially improved error rates and reduced sensitivity to parameter selection for large yδ1. This additional regime can be detected empirically and used for estimating the intrinsic dimension yδ2 of the relevant signal submanifold.
Figure 2: Simulated data (yδ3) and Tikhonov error under two reconstruction bases: SVD and permuted unit vectors.
Numerical results confirm that learned methods (e.g., LISTA and learned primal-dual networks) substantially outperform classical methods in the presence of low-dimensional ground truth, as they exploit manifold structure absent from classical Tikhonov regularization (whose filter acts globally and agnostically). Furthermore, the empirical procedure for estimating yδ4 via varying the truncation parameter yδ5 in truncated Tikhonov regularization aligns with analytical predictions, supporting dimension estimation from error curves.
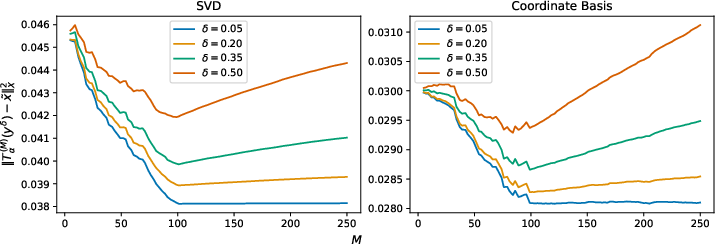
Stability and Error Analysis of Learned Regularization Schemes
Focusing on variational regularization with a learned sparsifying transform yδ6, the paper analyzes the error properties of reconstructions derived via: yδ7
where yδ8 is obtained non-operator-specifically (e.g., via CNN-based denoising).
Theoretical scrutiny reveals:
When yδ9 covers α>00 ("injective" case), learned regularization can guarantee optimal regularization properties with suitable α>01.
When α>02 is non-injective and the signal has components in α>03, uncontrolled error growth is possible in the infinite-dimensional setting (formally analogous to known pathologies in underconstrained regularization).
In finite-dimensions, stability holds in the sense that the (possibly set-valued) regularized inverse is Hausdorff-Lipschitz continuous as a function of the input data, with explicit dependence on properties of α>04 and α>05.
Figure 3: Simulated data sample with α>06 showing error as a function of truncation dimension α>07.
Experimental evidence affirms the practical stability of the learned-regularizer-based Tikhonov schemes, matching or improving upon classical methods in data regimes where the learned model adequately captures the signal structure.
Practical and Theoretical Implications
The results have several key implications for the theory and application of regularization in inverse problems:
Classical Tikhonov regularization is robust to moderate-to-severe misspecification of the regularization parameter provided the noise level is not grossly underestimated, which has consequences for heuristic or batch parameter selection in deployed pipelines.
Knowledge (even empirical) of intrinsic data dimension yields improvements in reconstruction error and parameter selection, indicating the value of model-based and data-driven hybrid schemes.
Learned regularization terms (especially those realized via neural networks or convolutional architectures) are best interpreted as adaptive, signal-class-specific regularizers whose efficacy is bounded primarily by the representational capacity and injectivity of the learned transform and its alignment with the forward model.
Stability and generalization of learned regularizers can be formally addressed in finite dimensions, but practitioners must take care when extending these schemes to very high- or infinite-dimensional signal spaces.
Conclusion
The paper offers a detailed mathematical and empirical dissection of Tikhonov-type regularization methods (both classical and learned) for inverse problems, highlighting scenarios where parameter selection is robust, regimes where learned methods excel, and theoretical hazards associated with improper regularizer design. The synthesis of variational, statistical, and deep learning perspectives provides actionable insights for further research on adaptive, data-driven regularization approaches and their safe deployment in computational imaging and other applied inverse problems.