- The paper introduces deconfounding scores as a novel framework unifying balancing and prognostic representations for unbiased causal estimation.
- It provides a closed-form solution for Gaussian GLMs that maps valid representations onto a hyperbolic family, enabling efficient variance reduction.
- Empirical evaluations demonstrate that prioritizing outcome-predictive information yields lower RMSE in weak-overlap scenarios compared to traditional methods.
Deconfounding Scores and Representation Learning under Weak Overlap: Theory and Practice
Introduction
The paper "Deconfounding Scores and Representation Learning for Causal Effect Estimation with Weak Overlap" (2604.00811) targets the persistent challenge of high-variance and instability in causal effect estimation when the traditional overlap (positivity) assumption is weak, especially in high-dimensional observational data. It approaches this by both formally defining and theoretically characterizing deconfounding scores: feature representations that retain sufficient confounding information for unbiased estimation while improving statistical properties, specifically overlap between treatment groups. The analysis includes nonparametric results and a tight closed-form solution for generalized linear Gaussian models, culminating in a geometric and algorithmic description of the tradeoff between balancing and prognostic score representations.
Theoretical Characterization of Deconfounding Scores
The authors provide a unifying formalism, showing that deconfounding scores are representations ψ(X) such that unconfounded adjustment for ψ(X) yields identifiability of the estimand. Both the propensity (balancing) score and the prognostic score are demonstrated as special cases contained in a larger class, connected analytically by a "zero confounding bias" constraint.
They introduce a covariate-wise confounding bias covariance expression, which states that any deconfounding score must satisfy:
τψ(X)−τ=EP0[Cov(m0(X),rX(X)∣ψ(X))]=0
where m0(X) is the conditional mean outcome model for controls, and rX(X) is the relevant density ratio defining overlap.
This criterion implies that any function measuring the conditional covariance of the prognostic and balancing statistics, conditioned on the representation, can interpolate between pure propensity- or outcome-based adjustments and trade off their information contributions.
Overlap Divergence: Quantifying Statistical Efficiency
A new metric called overlap divergence, defined as the χ2-divergence between the treatment and control distributions, is proposed to measure the severity of poor overlap for a given representation:
O(Z)=χ2(PZ1∥PZ0)+1
Analytically, the authors show that the minimal possible variance (semiparametric efficiency bound) of any regular and asymptotically linear estimator is tightly controlled by O(ψ(X)). Reducing O(ψ(X)) is necessary and often sufficient for improving estimator variance.
They mathematically prove that any representation, as long as it excludes variables predictive only of the treatment and not of the outcome (i.e., reduces the balancing score error), strictly improves overlap compared to the original feature space. The improvement magnitude connects directly to a reduction in confounding bias, providing the first mathematical proof of the intuition that reducing treatment-predictive (but not confounding) features reduces variance.
Analytic Solution for Gaussian GLMs: Hyperbolic Geometry and Optimality
For Gaussian feature settings with generalized linear outcome and assignment models, the paper derives the entire family of deconfounding scores in closed form. The key result is geometric: the set of valid deconfounding linear projections γ lies on a segment of a hyperbola in the subspace spanned by the outcome and treatment regression vectors, ψ(X)0 and ψ(X)1.
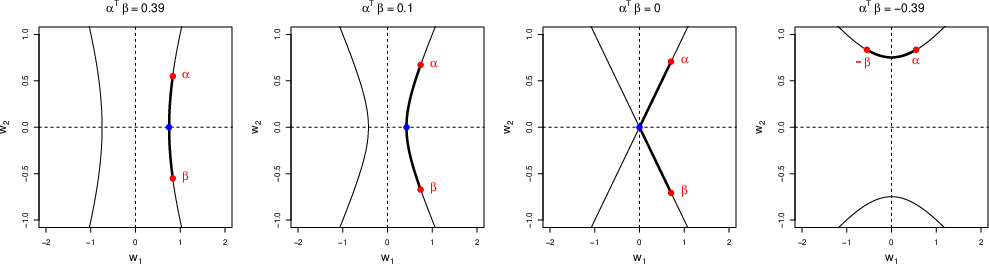
Figure 1: The projection of ψ(X)2 onto the space spanned by ψ(X)3 and ψ(X)4 lies on a hyperbola between endpoints corresponding to ψ(X)5 (prognostic score) and ψ(X)6 (balancing score); orientation and endpoints depend on ψ(X)7.
The main theorem establishes that among all representations in this hyperbolic family:
- Prognostic scores (aligned with the outcome model vector ψ(X)8) globally minimize overlap divergence.
- Balancing scores (aligned with the propensity score vector ψ(X)9) globally maximize it.
- The entire family forms a continuum, parameterized by convex combinations and controlled by a hyperbolic constraint.
This result is robust for a broad range of link functions and includes non-smooth cases (e.g., indicator and ReLU functions). The geometric mapping offers a continuous spectrum for methodologically interpolating between the two classical extremes depending on statistical priorities.
Empirical Evaluation: Simulations and Semi-Synthetic Datasets
The authors conduct comprehensive simulations to empirically validate their theoretical claims. Three classes of estimators—outcome regression, IPW, and AIPW—are compared using either raw covariates or deconfounding-score-based representations (balancing, prognostic, equiangular). Both well-specified and misspecified settings are included, testing robustness to real-world estimation error.
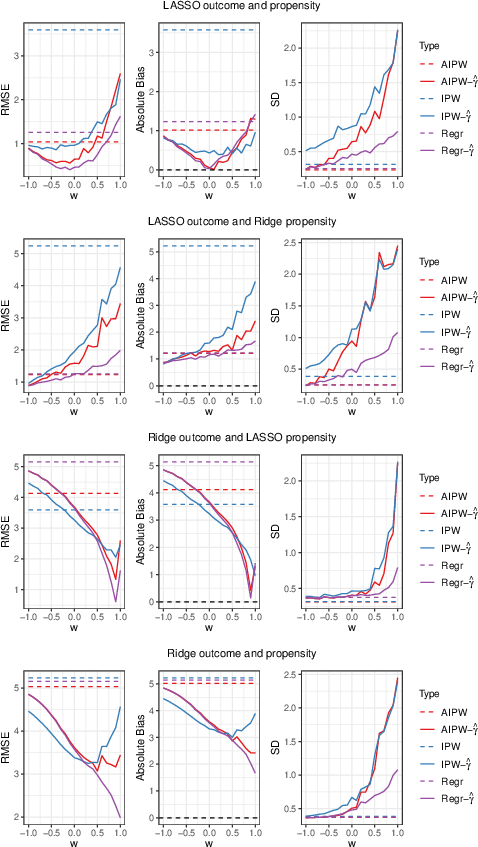
Figure 2: RMSE, bias, and standard deviation on synthetic data, reported as functions of the coordinate τψ(X)−τ=EP0[Cov(m0(X),rX(X)∣ψ(X))]=00 parameterizing the deconfounding score within the hyperbolic family.
Key findings:
- Prognostic scores consistently yield lower or equal RMSE relative to baseline models when the outcome model is well-specified, particularly improving in low-overlap regimes (high τψ(X)−τ=EP0[Cov(m0(X),rX(X)∣ψ(X))]=01).
- In regimes of model misspecification, balancing scores are superior if and only if the propensity model is well-approximated and the outcome model is not.
- Equiangular scores (interpolating representations in the score space) often offer a robust compromise, combining information from both predictive directions and mitigating model misspecification.
- These patterns persist both in highly controlled simulations and canonical semi-synthetic benchmarks (IHDP, ACIC2016, HC-MNIST), with the empirical best score always from some member of the deconfounding score family.
Implications, Limitations, and Future Directions
The results strongly imply that representation learning for causal effect estimation should prioritize preservation of outcome-predictive information (prognostic scores) for efficiency under weak overlap, and that standard balancing score approaches may be statistically suboptimal in high-dimensional, low-overlap domains.
The analytic framework also enables principled design of regularization for neural or deep representations: explicit constraints or penalties can enforce zero-confounding bias while directly targeting decrease in overlap divergence. This positions deconfounding scores as a natural drop-in for all modern doubly robust estimators (AIPW, TMLE, double/debiased machine learning).
Primary limitations are the reliance on correct specification and on the Gaussian+GLM model for closed-form results; generalizing analytic optimality to arbitrary nonlinear representations remains unresolved. The estimation from finite data of overlap-optimal representations is also open, suggesting future research in both algorithmic and theoretical extensions, possibly involving variational τψ(X)−τ=EP0[Cov(m0(X),rX(X)∣ψ(X))]=02-divergence optimization and more general representation families.
Conclusion
The paper presents a rigorous formalization and deep characterization of the deconfounding score representation class for causal inference under weak overlap. The geometric, analytic, and empirical results collectively demonstrate that classical prognostic scores realize optimal overlap properties and statistical efficiency, providing substantial guidance for the design of causal representations. This work unifies and extends the theory of balancing and prognostic scores into a broad, actionable framework and sets up several well-posed future challenges in robust, high-dimensional causal effect estimation.