Proactive Agent Research Environment: Simulating Active Users to Evaluate Proactive Assistants
Abstract: Proactive agents that anticipate user needs and autonomously execute tasks hold great promise as digital assistants, yet the lack of realistic user simulation frameworks hinders their development. Existing approaches model apps as flat tool-calling APIs, failing to capture the stateful and sequential nature of user interaction in digital environments and making realistic user simulation infeasible. We introduce Proactive Agent Research Environment (Pare), a framework for building and evaluating proactive agents in digital environments. Pare models applications as finite state machines with stateful navigation and state-dependent action space for the user simulator, enabling active user simulation. Building on this foundation, we present Pare-Bench, a benchmark of 143 diverse tasks spanning communication, productivity, scheduling, and lifestyle apps, designed to test context observation, goal inference, intervention timing, and multi-app orchestration.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about making and testing “proactive” digital assistants—helpers that don’t wait for you to ask, but watch what you’re doing and offer to help at the right time. The authors build a realistic simulator called PARE (Proactive Agent Research Environment) and a big set of challenges called PARE‑Bench to see how well different AI assistants can notice what a user needs, suggest helpful actions, and carry them out across multiple apps (like Messages, Email, Calendar, and To‑Do lists).
Imagine you’re writing a shopping list and your roommate texts that you’re out of soap. A proactive assistant would notice that and add “soap” to your list without you typing a request. This paper creates a safe, realistic “practice world” to teach and test assistants like that.
What were the main goals?
The paper focuses on a few clear questions:
- How can we simulate real users in a realistic way so proactive assistants can be tested fairly?
- Can an assistant:
- Watch what a user is doing and understand their goal?
- Decide the right moment to offer help (not too often, not too late)?
- Complete tasks that involve several different apps?
- Which AI models are best at this, and how consistent and robust are they?
How did the researchers do it?
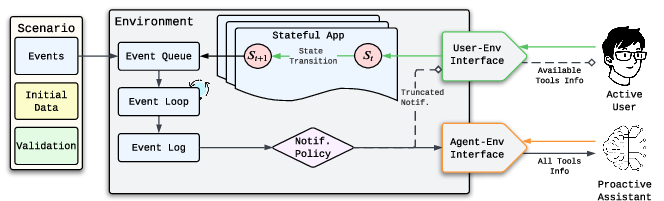
They built a virtual phone environment that imitates how people actually use apps and how assistants would work behind the scenes. Here are the key ideas, explained simply:
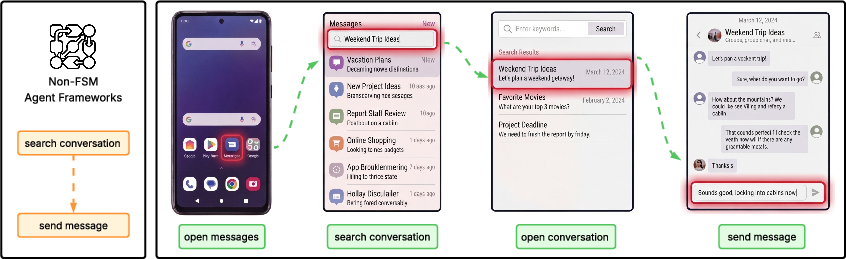
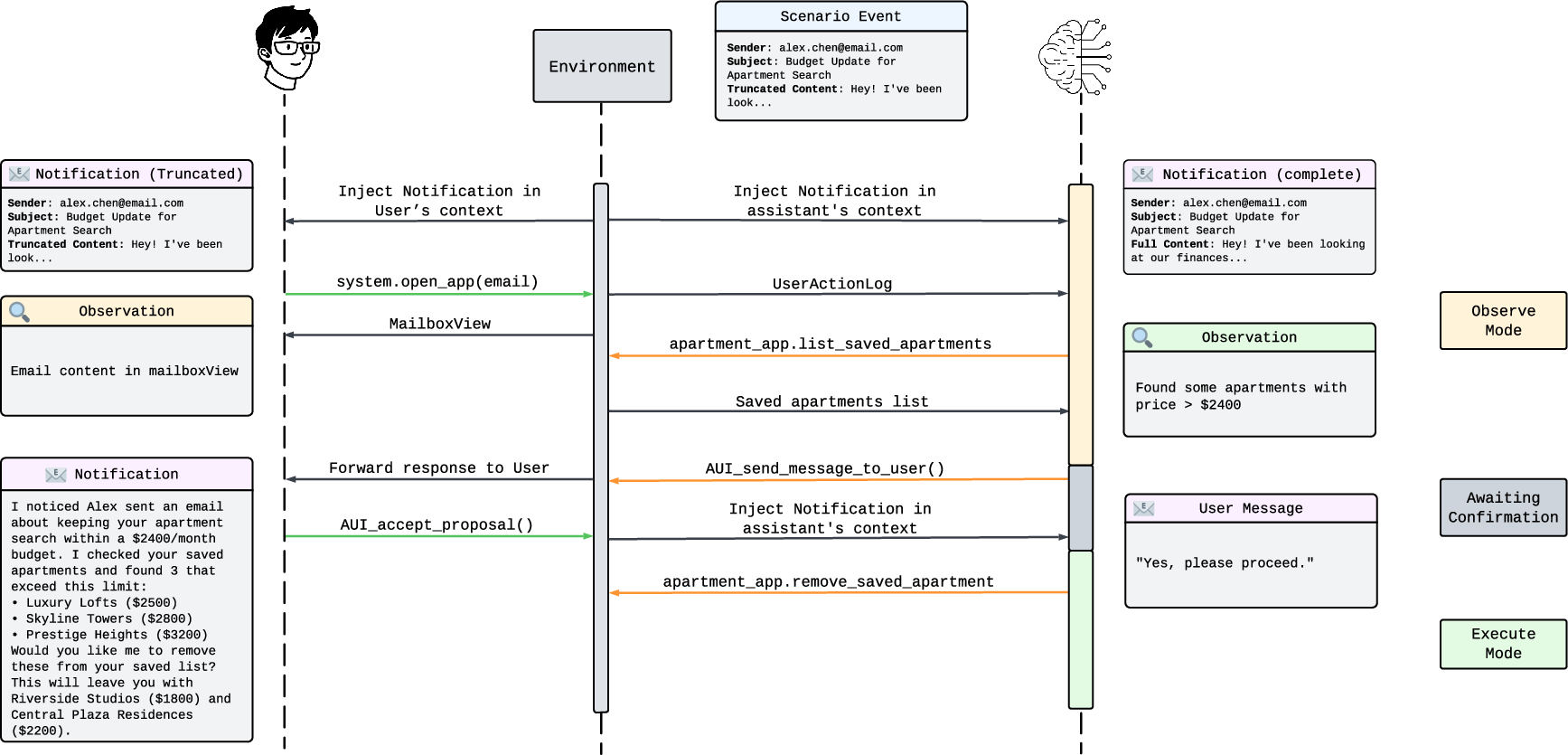
- Apps as “state machines”: Think of each app (like Messages) as a series of screens and buttons. You can only do certain things depending on which screen you’re on—just like real life. This is called a finite state machine (FSM). For example, to send a text, a user must: 1) Open the Messages app, 2) Find a conversation, 3) Open it, 4) Type a message, 5) Send it.
A human (or simulated user) must go step by step. The assistant, however, can use “backstage” tools to jump straight to the action if the user approves.
- Asymmetric abilities (realistic difference between user and assistant):
- The user is “on the phone,” tapping around screens and seeing only what a user would see.
- The assistant has a flat list of tools across all apps (a backstage pass) and can do things directly—after asking permission.
- Turn-based interaction (like taking turns in a game): 1) The user acts first (taps around). 2) The assistant watches, gathers info, and either waits or proposes a plan (“I can add soap to your shopping list. OK?”). 3) The user accepts or rejects. 4) If accepted, the assistant executes the plan; if not, it goes back to watching.
- Two-part assistant design:
- Observe mode: the assistant only reads and thinks about what’s happening, deciding whether to propose help.
- Execute mode: after the user says “yes,” the assistant acts quickly and uses any needed tools across apps.
- Scenarios with events: The environment includes realistic events like incoming emails, messages, and reminders. This tests if assistants can spot what matters and ignore distractions.
- Benchmark and evaluation: They made PARE‑Bench with 143 tasks across communication, scheduling, productivity, and lifestyle apps. They measured:
- Success rate: Did the assistant’s help actually complete the user’s goal?
- Acceptance rate: How often did users accept the assistant’s proposals?
- Proposal rate: How often did the assistant propose something (too many proposals can be annoying)?
- Info gathering: How much did the assistant read/inspect before acting?
What did they find?
- Top models are good—but far from perfect: The best large models succeeded only about 42% of the time on average across tasks. That means there’s a lot of room to improve proactive assistants.
- Quality beats quantity of proposals: The best-performing assistant (Claude 4.5 Sonnet) proposed help less often but got the highest acceptance rate. Another strong model (Gemini 3 Flash) did similarly well but tended to propose more often and got accepted slightly less. Proposing too often without enough context hurts usefulness.
- Reading more helps: Better assistants tend to “look around” more—checking messages, calendars, and emails before proposing a plan. This careful observation leads to smarter, more acceptable suggestions.
- Smaller models struggle and are inconsistent: Smaller open-source models were less successful and less reliable across repeated runs. Some had decent proposal acceptance but still failed at actually completing tasks, suggesting the execution step is hard for them.
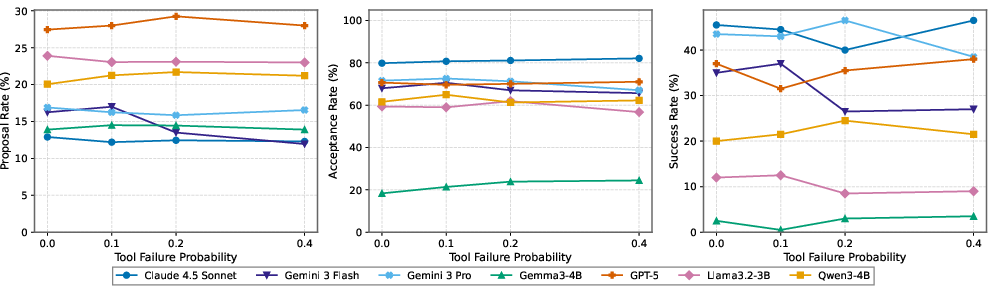
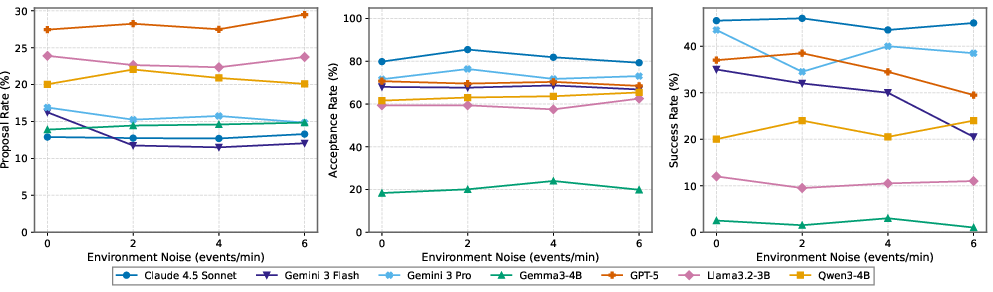
- Robustness to problems and noise varies:
- Tool failures (like functions occasionally breaking) didn’t faze the best models much, but smaller models degraded more.
- Noisy environments (lots of irrelevant notifications) also affected some models more than others. The best models stayed steadier.
Why does this matter?
- Realistic training and testing: Proactive assistants should respect how people actually use phones—screen by screen—so they help at the right time and in the right way. PARE makes that possible by simulating both the user and the assistant realistically.
- Better user experience and safety: The assistant must ask before doing things. This keeps humans in control and avoids unwanted changes. The framework encourages assistants that are helpful but not bossy.
- Privacy-aware design: Because proactive assistants observe user activity, the authors highlight using on-device models and only exposing higher-level “actions” (like “user opened ‘Messages’”) instead of raw screen content.
- A shared testbed for progress: PARE and PARE‑Bench give researchers and developers a common playground to compare ideas, improve assistants, and make them more reliable, respectful, and useful.
In short, this work builds a realistic “practice world” where proactive assistants can learn to be good helpers—spotting needs, asking permission, and getting tasks done across apps—while keeping the user in charge.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concise list of what remains missing, uncertain, or unexplored in the paper, framed to be actionable for future researchers.
- Human-grounded evaluation is absent: results rely entirely on an LLM-based user simulator (GPT-5-mini), with no user studies to validate proposal acceptability, perceived helpfulness, interruption cost, or autonomy preservation in real use.
- Validity of the simulated user’s acceptance/rejection behavior is untested: no calibration against human judgments, inter-rater reliability, or evidence that the simulator’s thresholds for “strict acceptance” align with users’ true preferences.
- Ecological realism of notifications and event flows is not validated: Poisson noise injection and scripted events are not matched to empirical distributions of mobile notification timing, content, and user receptivity from real-world datasets.
- Visual/GUI grounding is missing: the environment abstracts apps as FSMs and APIs without modeling visual layout, affordances, or perception errors that GUI agents face (e.g., misclicks, occlusions), limiting transfer to real mobile interfaces.
- FSM coverage and fidelity are unclear: the completeness of app FSMs (edge cases, optional flows, permissions, multi-step confirmations, multi-threaded state changes) and how they scale to complex, modern apps is not evaluated.
- Concurrency and asynchrony are under-modeled: the fixed Stackelberg turn-taking with a max of 10 turns does not capture overlapping actions, preemption, background processes, or continuous monitoring common in mobile usage.
- Intervention timing is not directly measured: despite claiming to assess timing, no explicit metrics quantify whether proposals arrived too early/late, interrupted at poor moments, or respected user busy/idle states.
- Cost-of-errors is not assessed: there is no quantitative treatment of false positives/negatives, error severity (e.g., sending wrong messages, scheduling mistakes), or recovery behaviors; acceptance rate alone cannot capture harm.
- Safety and consent granularity are limited: the binary accept/reject model lacks micro-permissioning (e.g., partial plan approval), escalation, rollback, or safeguards for sensitive domains (finance, health, privacy).
- Personalization and long-term adaptation are unaddressed: the agent does not learn user preferences, routines, or thresholds for proactivity over time, nor does the benchmark include longitudinal scenarios for personalization.
- POMDP formalization lacks learning/optimization methods: the paper provides a Stackelberg POMDP framing but no concrete algorithms for policy learning, confidence calibration, reward shaping, or optimal proposal decision-making.
- No comparison to reactive baselines: the paper does not quantify the benefit (or harm) of proactivity versus high-quality reactive agents on the same tasks, leaving the net value of proactivity unmeasured.
- Observation asymmetry design is untested: while assistants see full serialized content and users see truncated notifications, the paper does not study how varying observation budgets (for either party) affect proposal quality and success.
- Execution bottlenecks are not diagnosed in detail: smaller models underperform in execution, but the paper does not analyze failure modes (tool selection, argument filling, cross-app orchestration, error recovery) to guide targeted improvements.
- Robustness dimensions are narrow: evaluation covers tool failure probability and noise density, but omits latency, network instability, permission prompts, API rate limits, partial tool unavailability, and inconsistent app states.
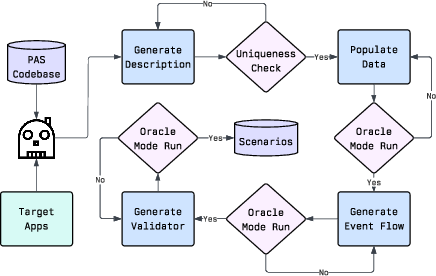
- Scenario generation quality and bias are not audited: LLM-generated scenarios are “verified by authors,” but there is no formal diversity analysis, difficulty calibration, bias checks, or reproducibility assessment of the generation pipeline.
- Benchmark coverage is insufficiently characterized: the paper does not report per-domain/task difficulty distributions, ablate multi-app versus single-app scenarios, or identify the subset of tasks driving most failures.
- Proposal content quality is not measured beyond acceptance: clarity, specificity, justification, and user-understandable explanations are not scored, limiting insights into why users accept/reject proposals.
- Limited analysis of iteration budgets: the choice of 5 observe and 10 execute iterations is treated as a parameter, but the paper does not study how iteration budgets impact proposal quality, execution reliability, or user experience.
- Assistant action visibility to the user is unrealistic: users cannot observe assistant actions (only outcomes/messages), whereas real assistants often provide progress/status; the impact of transparency on trust and acceptance is unexplored.
- On-device constraints are not modeled: although the paper argues for on-device deployment, it does not evaluate compute/memory/latency trade-offs, battery impact, or performance under realistic edge hardware limitations.
- Privacy guarantees are not formalized: API-level abstraction is claimed as a privacy boundary, but there is no threat model, data retention policy, or empirical audit of what sensitive information remains exposed to the assistant.
- Generalization to richer app ecosystems is unknown: the benchmark uses a fixed set of apps; how the framework handles OS-level features (deep links, intents), third-party app diversity, and dynamic app updates is not demonstrated.
- No learning from user feedback: the assistant does not adapt its future proposal policies based on past accept/reject outcomes, leaving open how to improve calibration and reduce user annoyance over time.
- Limited error handling and rollback: the system does not model plan interruption, partial failure recovery, undo/redo semantics, or user-requested corrections after execution, which are critical for safe proactive assistance.
- Missing ablation of the Observe–Execute architecture: there is no comparison against unified agents or alternative decompositions (e.g., triage/planning/execution modules) to justify the chosen architecture.
- User-model sensitivity analysis is incomplete: although referenced, the effect of different user simulators on reported metrics is not shown here; conclusively determining benchmark robustness to user-model choice remains open.
- External validity to real mobile platforms is unverified: no deployment or case study demonstrates that gains in the simulated environment translate to effectiveness on Android/iOS with real users and apps.
Practical Applications
Practical Applications of the Paper’s Findings
Below are actionable, real-world applications derived from the paper’s framework, methods, and benchmark. Each item notes target sectors, plausible tools/products/workflows that could emerge, and key assumptions or dependencies that affect feasibility.
Immediate Applications
These are deployable now or with modest integration effort.
- Proactive-assistant CI/CD benchmarking and regression testing
- Sector: Software, Mobile OS, Productivity Apps
- Tools/products/workflows: Integrate the PARE framework and its 143-scenario benchmark into continuous integration pipelines; set acceptance-success-proposal-rate gates; nightly stress tests with noise and tool-failure sweeps; dashboards tracking Success@k and proposal quality.
- Assumptions/dependencies: FSMs or wrappers for in-scope apps; flat APIs or realistic mocks; engineering time to model app states; compute budget for multi-run evaluation.
- Proposal timing and “annoyance” calibration
- Sector: HCI/UX, Assistant Teams
- Tools/products/workflows: Tune Observe→Execute thresholds; optimize proposal-rate vs. acceptance-rate curves; run A/B tests by varying user-simulator strictness and notification verbosity; deploy guardrails to avoid over-proposing.
- Assumptions/dependencies: Validity of LLM-based user acceptance as a proxy for real users; policy for maximum proposal frequency.
- Multi-app orchestration validation for assistants
- Sector: Productivity (email, calendar, tasks), Enterprise SaaS
- Tools/products/workflows: End-to-end orchestration tests (e.g., calendar + email + notes) using the flat API executor; oracle-based verification for success conditions; regression suites for cross-app flows.
- Assumptions/dependencies: Connectors to each app; consistent identifiers across app data (contacts, events, threads).
- SDK for app teams to declare FSMs of their UIs
- Sector: Mobile/desktop app developers
- Tools/products/workflows: “FSM Authoring Studio” with schema, codegen, and validation; stubs that map UI screens → user-only actions → backend APIs; instrumented navigation logging.
- Assumptions/dependencies: Developer time to author and maintain FSMs; UI churn management; alignment with platform accessibility trees.
- On-device model feasibility testing and sizing
- Sector: Edge AI, Mobile Platforms
- Tools/products/workflows: Side-by-side runs of small open-weight models vs. frontier models on PARE; measure trade-offs in success and acceptance; caching/RAG experiments to boost small models.
- Assumptions/dependencies: Device hardware constraints; latency/energy budgets; privacy policies mandating on-device inference.
- Data generation for training propose-vs-execute policies
- Sector: ML Ops, Model Training
- Tools/products/workflows: Collect simulation trajectories with acceptance feedback; SFT/behavior cloning on Observe and Execute phases; RL with acceptance and success as reward signals.
- Assumptions/dependencies: Rights to use generated data; sim-to-real transfer effectiveness; careful de-duplication and scenario diversity.
- Robustness testing harness (tool failures and event noise)
- Sector: Reliability/SRE for Assistants
- Tools/products/workflows: “Noise/Failure Stress Harness” to quantify resilience; ensure graceful degradation and alternative plan search when tools fail; log-based root cause analysis.
- Assumptions/dependencies: Controllable failure injection in the test env; clear fallback policies when APIs fail.
- Privacy-by-design auditing at the API/action level
- Sector: Compliance, Trust & Safety
- Tools/products/workflows: Test that assistants rely on API-level action observation rather than screen scraping; produce auditable event logs for proposals, acceptances, executions.
- Assumptions/dependencies: Mapping between policy requirements and logged events; alignment with platform permissions and data minimization principles.
- Procurement and vendor benchmarking using common metrics
- Sector: Enterprise IT, Public Sector
- Tools/products/workflows: RFP-style bake-offs using PARE-Bench; standardized reporting (success rate, acceptance rate, proposal rate under noise/failure); leaderboards and SLAs tied to acceptance thresholds.
- Assumptions/dependencies: Agreement on metrics and test sets; representative scenarios for target use cases.
- HCI research and classroom sandbox
- Sector: Academia, Education
- Tools/products/workflows: Course labs on proactive agents and mixed-initiative design; studies on interruptibility, autonomy, and trust using configurable user-simulator strictness and event verbosity.
- Assumptions/dependencies: Instructor adoption; access to compatible LLMs; IRB considerations for human studies if combined with user trials.
- Accessibility-oriented pathway reduction analysis
- Sector: Accessibility, Inclusive Design
- Tools/products/workflows: Use FSM traces to quantify steps saved by proactive interventions; identify friction points and opportunities for just-in-time assistance.
- Assumptions/dependencies: Appropriately designed scenarios/personas; domain expert review to ensure accessibility relevance.
- Internal policy testing for consent-gated execution
- Sector: Product Policy, Governance
- Tools/products/workflows: Enforce Observe→Propose→User-accept→Execute workflow; verify consent logging and “no silent execution” rules; test escalation and rollback.
- Assumptions/dependencies: System UX surfaces for user consent; audit log storage and review workflows.
Long-Term Applications
These require further research, scaling, standardization, or ecosystem development.
- OS-level proactive assistants with consent-gated execution
- Sector: Mobile/Desktop OS, Consumer Software
- Tools/products/workflows: System-wide observers (read-only), cross-app flat APIs for execution, and native consent sheets; background monitoring with user-controlled schedules.
- Assumptions/dependencies: Platform APIs that expose consistent, secure backends; sustained success/acceptance above target thresholds; regulatory buy-in.
- Certification and standards for proactive agents
- Sector: Policy/Regulation, Standards Bodies
- Tools/products/workflows: PARE-like evaluation suites for certification; noise/failure stress criteria; reporting standards for proposal/acceptance/exec logs and human-in-control requirements.
- Assumptions/dependencies: Multi-stakeholder consensus; third-party auditors; versioned public benchmarks.
- Automatic FSM extraction from real apps via GUI grounding
- Sector: Tooling, DevOps
- Tools/products/workflows: Record-and-generalize user flows into FSMs from accessibility trees, visual UI grounding, and usage telemetry; continuous updates as UIs evolve.
- Assumptions/dependencies: High-quality GUI-grounding models; platform hooks to record flows; privacy-preserving data collection.
- Personalized user simulators calibrated to real behavior
- Sector: ML/HCI, Personalization
- Tools/products/workflows: Preference models for acceptance thresholds, interruptibility, and autonomy; on-device federated fine-tuning of user simulators; persona libraries for target demographics.
- Assumptions/dependencies: Consent-based telemetry; differential privacy; robust generalization across personas.
- Training robust small on-device proactive models
- Sector: ML, Edge AI
- Tools/products/workflows: Distill Observe and Execute skills from large models into compact ones; RL with acceptance/success rewards; retrieval-augmented small models specialized per app domain.
- Assumptions/dependencies: Efficient distillation pipelines; device acceleration (NPUs); careful latency-utility trade-offs.
- Cross-ecosystem IoT and energy management orchestration
- Sector: IoT, Energy
- Tools/products/workflows: FSMs for appliances and home hubs; proactive suggestions for demand response, off-peak scheduling, “just-in-time” automation with consent.
- Assumptions/dependencies: Interoperable standards (e.g., Matter); robust security; user trust and override controls.
- Healthcare appointment/medication and portal workflows
- Sector: Healthcare
- Tools/products/workflows: FSMs for patient portals (scheduling, refills, forms); consent-gated proactive reminders and prefill; end-to-end state tracking for adherence.
- Assumptions/dependencies: HIPAA and regional compliance; provider partnerships; rigorous safety/efficacy validation.
- Finance assistants for bills, disputes, and budgeting
- Sector: Finance/Fintech
- Tools/products/workflows: FSMs for banking portals; proactive bill pay with approval; fraud dispute flows; budget alerts and cross-account reconciliation.
- Assumptions/dependencies: Compliance (KYC/AML, PSD2/Open Banking); robust identity and risk controls; clear liability frameworks.
- Enterprise workflow copilots across SaaS suites
- Sector: Enterprise Software
- Tools/products/workflows: Orchestrate email, calendar, CRM, ticketing; proactive triage and scheduling; admin policies controlling proposal scopes and audit trails.
- Assumptions/dependencies: API access across vendors; data governance; change management and IT buy-in.
- Education copilots across LMS and calendars
- Sector: EdTech
- Tools/products/workflows: FSMs for LMS/assignment portals; proactive study plans; parent/teacher oversight with consent and logs.
- Assumptions/dependencies: LMS integrations; privacy (FERPA, GDPR-K); user trust and transparency.
- Human-robot collaboration and operator assistants
- Sector: Robotics, Industrial
- Tools/products/workflows: Map machine states to FSMs; proactive step suggestions and checklists; consent-gated execution of safe subroutines.
- Assumptions/dependencies: Safety certification; reliable state estimation; strict override and e-stop protocols.
- Government and public-service assistants
- Sector: Public Sector
- Tools/products/workflows: Proactive guidance for complex forms and appointments (tax, visas, benefits); consent gating and transparent logs; accessibility-focused variants.
- Assumptions/dependencies: Modernized APIs; public-sector security and privacy compliance; multilingual support.
- Security and audit-focused assistant sandboxes
- Sector: Cybersecurity
- Tools/products/workflows: Controlled environments to test agents for data exfiltration risks, unauthorized execution, and prompt/tool injection; red-team benchmarks for proactive agents.
- Assumptions/dependencies: Standard threat models; integration with SOC tooling; secure logging and forensic pipelines.
Cross-Cutting Assumptions and Risks
- The ecological validity of LLM-simulated users may differ from real users; mixed-methods validation (user studies + simulation) will be important.
- FSM coverage must be kept current with UI changes; automatic extraction or close dev collaboration is key.
- Flat backend APIs for cross-app execution are required for assistants; OS support and permissions are a gating factor.
- Privacy and consent are central: on-device inference and API-level observation reduce exposure, but policy and UX must enforce human control.
- Current success rates (≈42% for top models in the paper) indicate more model and system work is needed before broad deployment in safety-critical domains.
Glossary
- Acceptance Rate: The proportion of the assistant’s proposals that the user accepts; used as a primary evaluation metric. "we evaluate proactive assistants on Acceptance Rate () and Task Execution Success ()."
- Agent Research Environment (ARE): A platform for building and evaluating agent environments with apps, scenarios, and verification; this work extends it for proactive settings. "Agent Research Environment (ARE) platform"
- BaseAgent: The core agent class in ARE that implements the Reasoning → Action → Observation loop used by both user simulators and assistants. "Both agents are built on ARE's BaseAgent"
- dual-control environment: An evaluation setting where both the agent and a user (or user simulator) can take actions, enabling interaction-focused testing. "creating a dual-control environment for technical support scenarios."
- ecologically valid: Describes simulations that closely mirror real-world conditions and constraints. "ecologically valid user simulator agents"
- event-based environment: An environment where asynchronous events drive state changes and notifications to agents and users. "an event-based environment that models Stateful App transitions."
- Execute Mode: The assistant’s operational phase in which it carries out approved plans using the full set of app APIs. "Execute Mode"
- Finite State Machine (FSM): A formal model of app/user states and transitions used to constrain user actions to realistic, screen-by-screen navigation. "finite state machines (FSMs)"
- flat API: An interface exposing all app tools uniformly to the assistant, without state-dependent restrictions, for efficient access. "flat API structure"
- goal inference: The process by which a proactive assistant deduces user objectives from observed actions and context. "goal inference"
- grounded execution semantics: The requirement that actions have concrete, state-changing effects in the environment, enabling realistic evaluation. "grounded execution semantics"
- mixed-initiative interface design: Principles for systems where control alternates or is shared between user and agent, balancing autonomy and user control. "mixed-initiative interface design"
- multi-app orchestration: Coordinating actions across multiple applications to complete complex tasks. "multi-app orchestration"
- observation space: The formal set of observations available to an agent or user at a given time in the environment. "observation space "
- Observe Mode: The assistant’s monitoring phase in which it gathers information and decides whether to propose help. "Observe Mode"
- oracle events: Scenario-defined events specifying expected proactive behaviors, used for evaluation and validation. "oracle events"
- oracle validation: Scenario checks that verify whether the assistant’s actions meet predefined success criteria. "oracle validation"
- plan-then-execute pattern: An agent design approach that separates planning (proposal) from action execution to preserve user control. "plan-then-execute pattern"
- Poisson process: A stochastic process used here to schedule random noise events (e.g., spurious notifications). "using a Poisson process"
- ReAct: An agent framework that interleaves explicit reasoning with actions and observations in a loop. "ReAct"
- Stackelberg POMDP: A partially observable decision process with a leader–follower structure used to formalize agent–user interactions. "Stackelberg POMDP"
- Stackelberg turn-based loop: A leader–follower turn structure where the user acts first and the assistant responds. "Stackelberg turn-based loop"
- Stackelberg turn-taking structure: The specific interaction order in which the user moves, then the assistant plans and possibly acts. "Stackelberg turn-taking structure"
- state-dependent action space: A constrained set of actions available to the user based on the current app/UI state. "state-dependent action space"
- stateful app interfaces: App interfaces that expose different actions depending on internal UI states, mirroring real device behavior. "stateful app interfaces"
- tool failure simulation: Injected failures of tools/APIs to test assistant robustness under unreliable conditions. "tool failure simulation"
- user-environment interface: The restricted interface through which the user simulator accesses apps and tools according to current UI state. "user-environment interface"
Collections
Sign up for free to add this paper to one or more collections.