- The paper systematically investigates variance, prompt sensitivity, and the effectiveness of method scaffolding in generating UML class diagrams from natural language requirements.
- Key findings demonstrate that preference-based prompting enhances design principle adherence, though significant non-determinism and inter-model variations persist.
- Methodological insights reveal that rule-injection can sometimes worsen output accuracy, highlighting current LLM limitations in robust architectural synthesis.
Reliability and Behavioral Stability of LLMs in Design Synthesis
This study critically evaluates the reliability and behavioral variance of LLMs in synthesizing UML class diagrams from natural language requirements, positioning the distinction between diagram translation and substantive design synthesis as central. Diagram translation predominantly involves mapping textual mentions directly to model elements, neglecting the implicit design principles and domain-driven architectural reasoning required for extensible and maintainable systems. By contrast, design synthesis presupposes the internalization and application of OOAD principles and canonical design patterns (such as abstraction, encapsulation, strategy, and observer), even when they are not explicitly referenced.
Recent empirical results indicate that existing frontier LLMs (e.g., GPT-4o, Claude 3.5, Gemini 2.5) can generate diagrams that are syntactically well-formed but often lack meaningful abstraction, principled encapsulation, and the emergence of design patterns absent explicit cues. This exposes fundamental limitations of previous evaluations that prioritized capability over the rigorous assessment of behavioral reliability—repeatability, paraphrase sensitivity, and inter-model variance—which are crucial for practical adoption in professional software engineering workflows.
Experimental Methodology
To probe the boundaries of LLM-based design synthesis, the authors constructed rigorous benchmarks across two domains of distinct complexity:
- Hospital Management System (medium-complexity; focused on policy-driven billing, requiring strategy pattern)
- Sensor Network (higher-complexity; event-driven, necessitating observer pattern induction)
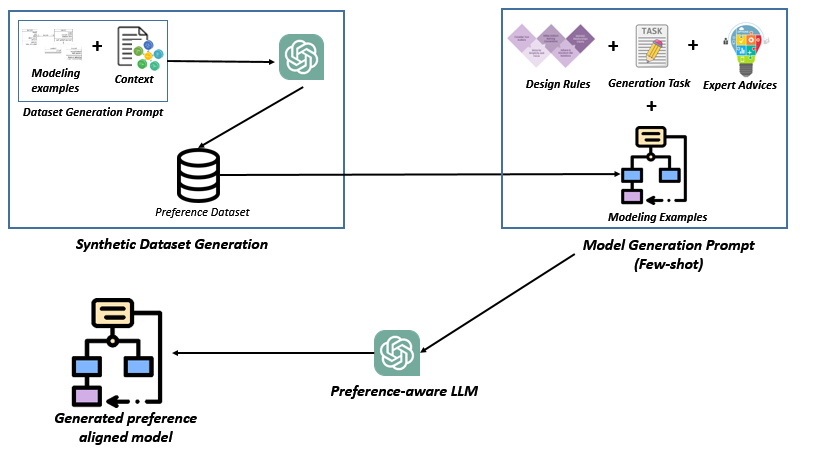
Each domain included three paraphrased, domain-only prompts withholding explicit mention of principles or patterns. Across 540 controlled experiments, three LLM architectures (ChatGPT 4o-mini, Claude 3.5 Sonnet, Gemini 2.5 Flash) were evaluated under three prompting regimes: standard prompting, rule-injection (explicitly encoding design guidelines), and a preference-based few-shot scheme leveraging contrastive exemplars rated by human experts. Each model, prompt, and prompting method was executed for ten independent runs, systematically enabling the measurement of stochasticity, sensitivity, and cross-model behavioral signatures.
Manual, expert-driven evaluation—eschewing token-level and purely automatable metrics—quantified:
Results and Analysis
Impact of Prompting Strategies on Design Synthesis
Preference-based prompting robustly increased alignment of LLM-generated diagrams with expert reference models, surpassing standard and rule-injection strategies in both principle adherence and pattern-consistent output. However, this effect was bounded: while preference-aligned prompts amplified the likelihood of proper abstraction and encapsulation, non-determinism and incomplete constraint satisfaction persisted, especially under higher complexity and in the absence of explicit architectural signals.
Notably, rule-injection did not yield systematic gains over baseline prompting—in some cases, e.g., for Gemini, it exacerbated hallucinated structures, suggesting increased prompt complexity might hinder rather than help models not calibrated for principled design reflection.
Cross-Model Variability and Behavioral Stability
The experiment revealed stark behavioral heterogeneity among LLMs:
- Claude 3.5 Sonnet: High decoding stability under fixed prompts but variable across paraphrases; repeated runs yielded nearly identical architectures even for complex tasks, though correctness was not guaranteed (consistent yet biased errors).
- ChatGPT 4o-mini: Once provided with effective scaffolding via preference-based or rule-injected prompts, outputs became highly consistent across repetitions and paraphrases; errors were systematic rather than stochastic.
- Gemini 2.5 Flash: Exhibited marked instability—both structural (class/relationship drift) and semantic—across runs and paraphrasing; the model failed to consistently instantiate non-trivial architectural patterns, highlighting a lack of controlled reasoning under minor input variations.
Stability index results empirically illustrated these phenomena, with Claude and ChatGPT achieving maximal or near-maximal SI under preference-based prompting, while Gemini lagged, reflecting only minimal improvement over baseline.
Emergence and Failure Modes of Pattern Consistency
Preference-guided approaches significantly improved the rate of pattern emergence (e.g., proper instantiation of the strategy pattern in the HMS benchmark). However, none of the evaluated models, under any prompting regime, successfully inferred the observer pattern required by the sensor network scenario—a canonical behavior-rich architectural motif that presupposes implicit event-driven dependencies.
Systematic design smells persisted: Claude omitted key relationships (e.g., aggregation required for proper strategy realization); ChatGPT occasionally duplicated inheritance links; Gemini introduced circular references and omitted essential abstractions. These behaviors underscore a persistent gap in the models’ capacity for holistic architectural generalization and constraint-enforced synthesis.
Prompt Sensitivity and Non-Determinism
Prompt paraphrasing revealed non-trivial sensitivity, particularly for Gemini but also for Claude in some cases. While semantic content was preserved, topological properties of the output diagrams were inconsistent (e.g., fluctuating number of classes, variation in inheritance hierarchy). The observation that models could be “nudged” toward architectural intent but not reliably anchored there across minor prompt variations indicates that robust LLM application in architectural settings demands both architectural scaffolding and model selection—prompting strategies alone are insufficient for true reliability.
Practical and Theoretical Implications
The study’s findings necessitate a reframing of LLM-based software modeling: reliability emerges as a primary concern, on par with capability. For industrial-grade adoption, LLMs must not only internalize and apply design intent but do so stably amidst prompt variation and minor task perturbations.
From a theoretical perspective, the results suggest that current architectures—or at minimum, current training and alignment pipelines—only marginally support the abstraction required for deep architectural synthesis. Even with preference feedback, the models do not exhibit the generalized, context-sensitive reasoning necessary for uncovered pattern induction and complex constraint satisfaction.
Further, preference-based methods offer tangible improvements and serve as a lightweight alternative to full RLHF pipelines, though persistent stochasticity and constraint violation indicate the need for fundamentally enhanced architectures or bespoke model fine-tuning on structured architectural feedback.
Limitations and Trajectories for Future Work
The present study is constrained to two benchmarks and relies on synthetic preference datasets; results may not generalize to a broader array of domains or to artifact types beyond UML class diagrams. Human expert evaluation, while aligning closer to practical utility, introduces subjectivity absent formalized, automated semantic evaluation metrics.
Future research directions include:
- Integrating preference-based prompting with explicit reasoning modules (e.g., neural-symbolic architectures, programmatic design checkers)
- Expanding benchmark diversity and scaling evaluation to a multi-artifact, cross-domain regime
- Experimenting with structured learning signals (e.g., combining RLHF with formal design constraint validation)
- Reducing output stochasticity through constrained decoding or ensemble consensus methods
- Developing model-centric benchmarks for robustness and repeatability in software engineering tasks
Conclusion
The study provides decisive evidence that the reliability and architectural soundness of LLM-generated UML diagrams are dominantly shaped by model-level behavioral traits, with prompting strategy modulating but not eliminating non-determinism or incompleteness. Preference-based alignment improves adherence to design intent, but strong architectural abstraction and pattern induction, especially under complexity, remain elusive for current frontier models. Consequently, LLM-based software modeling must be equally scrutinized for reliability as for average-case quality, and further research is needed to bridge the gap between surface-level translation and robust, dependable design synthesis.