- The paper introduces a Bayesian sequential testing framework that optimally orchestrates heterogeneous LLMs for binary hypothesis evaluation.
- It develops a convex optimization model showing that only two specialized LLMs are sufficient to balance cost, latency, and accuracy under high-confidence settings.
- The method integrates cost, latency, and error asymmetries to deliver scalable, real-time orchestration applicable to systems like content moderation and fraud detection.
Asymptotically Optimal Sequential Testing with Heterogeneous LLMs
The paper develops a Bayesian binary hypothesis testing framework for sequentially orchestrating multiple heterogeneous LLMs as information sources. Each LLM is parameterized by distinct per-query cost, sub-Gaussian response time (latency), and asymmetric accuracies for the two hypotheses, leading to the core quantities: (Ij,A,Ij,B), the expected information gain under each hypothesis for model j. This setup directly models practical settings such as test-time orchestration of diverse LLM APIs, layered content moderation, and fraud detection pipelines, where queries can be escalated among tools with varied reliability, cost, and latency profiles.
Classical literature on sequential testing (e.g., Wald’s SPRT) or adaptive experiment design (e.g., Chernoff’s or Naghshvar’s formulations) either assumes a homogeneous information source or does not address the full operational regime encountered in modern AI systems: source-specific monetary costs, random and nontrivial latency, and significantly asymmetric error profiles. The authors motivate the need to transcend one-shot model selection—replacing it with online sequential orchestration—by highlighting that real-world systems (e.g., OpenAI’s GPT-n routers, payment-fraud layers, agentic LLM pipelines) measure efficiency by balancing correctness, cost, and latency.
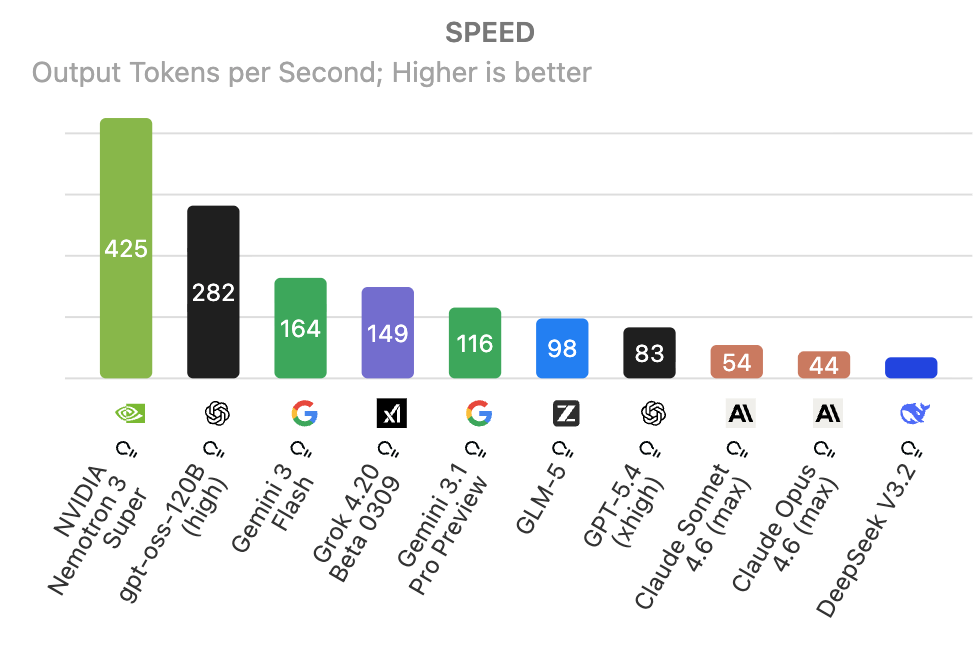
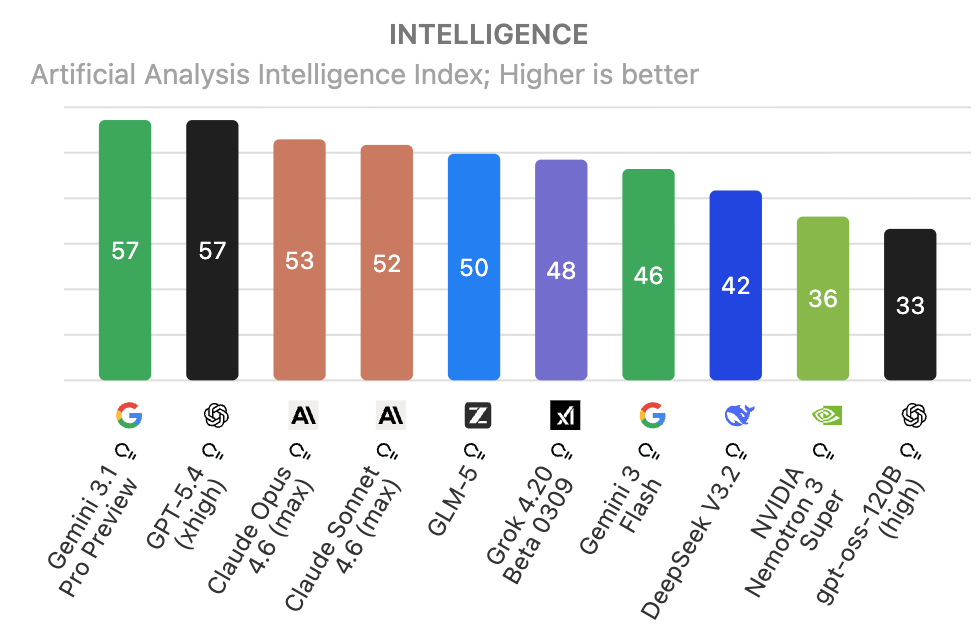
Figure 1: Left: Output speed distribution for leading LLMs; Right: Intelligence Index for LLMs on standard benchmarks, showing pronounced heterogeneity relevant for orchestration policies.
Sequential Policy Structure and Theoretical Contributions
The agent’s policy consists of: at each time, selecting an LLM jt, observing its noisy binary response, and accumulating the log-likelihood ratio (LLR); stopping occurs once the posterior probability of either hypothesis exceeds 1−α. The overall risk/cost includes both cumulative monetary expenditure and a convex-in-wait penalty (e.g., polynomial in total latency), modeling settings with strict delay constraints.
- Denote priors on θ∈{A,B} by (ξA,ξB), and LLM j's accuracies by (γj,A,γj,B).
- For selection history j1:t and outcomes Y1:t, the LLR is j0, with per-model increments j1 varying by ground truth, as LLM diagnostics are asymmetric.
- The drift under each hypothesis for model j2 is j3 and j4. These provide a two-dimensional information efficiency profile, crucial for sequential allocation.
The paper’s first technical result is a universal lower bound on attainable risk for any admissible policy: asymptotic risk as j5 is governed by solving a deterministic convex allocation over the j6 available LLMs to satisfy information budget constraints for both hypotheses. The minimal expected cost/penalty achievable is the value of the following program:
j7
where j8 are the expected queries to LLM j9 under each hypothesis, and jt0 encodes total expected cost and delay. The core insight: this convex program’s structure admits an optimal solution using at most two nonzero allocations—corresponding to at most two distinct LLMs.
Policy Class and Asymptotically Optimal Structure
The principal positive result identifies a sign-based policy jt1: the agent tracks the cumulative LLR and selects the “jt2-specialist” when belief favors jt3 (LLR jt4) and the “jt5-specialist” when it favors jt6. Upon entering the high-confidence region (LLR crossing a threshold), the policy effectively acts as a single-source SPRT with the optimal specialist, minimizing additional cost. Switching between two sources is necessary in generic settings due to information asymmetry and cost heterogeneity. The policy’s asymptotic risk matches the universal lower bound up to jt7 for a latency cost penalty of order jt8, with this remainder being minimax optimal among all admissible policies.
Detailed Mathematical and Algorithmic Insights
Key Mathematical Developments
- LLR Threshold Structure: Stopping is characterized by LLR exceeding jt9 or 1−α0, with thresholds depending on prior odds and the error tolerance.
- Information Budget Constraints: All admissible policies must collect at least 1−α1 (resp. 1−α2) expected information under 1−α3 (resp. 1−α4), up to 1−α5 corrections factoring in overshoot.
- Sparse Allocation Property: Via KKT analysis of the convex program, the authors prove that for any cost-risk surface defined by monotone convex 1−α6, optimal allocations have at most one nonzero 1−α7 and one 1−α8 for each hypothesis; if there is non-degeneracy (no exact resource ties), pure specialist policies are strictly optimal.
- Martingale and Concentration Analysis: Fine-grained concentration, including Freedman-type inequalities on LLR martingale parts, is used to control the random overshoot and additional cost induced by switching or uncertain stopping times.
Consequences for LLM System Design
- Only Two Sources Needed: For an optimal system, only two LLM APIs need to be orchestrated, regardless of the size of the available pool. The optimal specialists may differ for 1−α9 and θ∈{A,B}0 directions, capturing cost and information asymmetry.
- Practical Decision Guidance: The search for optimal orchestration reduces to identifying, for each possible true hypothesis, which LLM offers the best cost-adjusted information rate. Interleaving is only needed in the “ambiguous region” near the prior.
- Scalability: The structural result demonstrates that system complexity need not scale with the pool of available LLMs—avoiding the need for complex routing trees or dynamic ensemble selection.
Numerical and Operational Implications
The cost-risk scaling is controlled by the specified confidence θ∈{A,B}1. If the waiting time penalty θ∈{A,B}2 is polynomial (e.g., linear), the expected cost grows as θ∈{A,B}3 in the high-confidence regime—matching the information-theoretic optimum—even in the presence of nontrivial, heavy-tailed latencies. For higher exponents, e.g., quadratic costs, the dominant asymptotic term becomes θ∈{A,B}4. The analysis covers the regime relevant for real-time decision platforms, such as content moderation systems, automated safety/fraud escalation, and multi-agent reasoning orchestrations.
Broader Landscape, Contrasts, and Extensions
- Contrast with Prior LLM Test-Time Compute Work: Earlier studies emphasize empirical strategies (sampling, debate, verification, mixture-of-experts) but lack structural guarantees for multi-LLM sequential allocation under operational constraints [snell2024scaling, wu2024inference]. The present paper offers both a sharp theoretical framework and actionable scheduling guidance.
- Relation to Model Cascades and Routing: Previous literature on fixed model cascades or routing (e.g., FrugalGPT, RouteLLM) focuses on static or input-dependent one-shot assignments. The current sequential framework generalizes the setting to allow for interleaved querying with posterior-adaptive source selection and derives strong asymptotic optimality.
- Connections to Operations Research for LLM Serving: The work complements parallel efforts in task-level and system-level scheduling for LLM inference (e.g., [ao2025optimizing, jaillet2025online]), by addressing the information-acquisition subproblem faced at test time by a single job or query instance.
Future Directions
The framework opens multiple avenues for generalization: extension to multi-hypothesis or structured output spaces, modeling fully continuous accuracy/cost/latency tradeoffs, and incorporating model-roster learning (where the statistical profile is not fully known a priori). Analyzing finite-sample nonasymptotics, adaptive or bandit settings with online source characteristic estimation, and robustification to adversarial (non-IID) response structures would advance the theoretical interface between sequential experiment design and practical LLM system operations.
Conclusion
This work establishes a comprehensive, information-theoretically sharp blueprint for sequential orchestration of heterogeneous LLMs in binary hypothesis testing. By dissecting the two-dimensional information-cost tradeoff and demonstrating that at most two LLM specialists are required for high-confidence optimality, the paper delivers both novel theoretical principles and powerful practical guidance for multi-model AI system design. The integration of martingale analysis, convex program allocations, and explicit operational constraints advances the state of the art in LLM deployment science.
Figure 1: Left: Distributions of LLM output speed. Right: Distribution of Intelligence Index for major LLMs, highlighting test-time heterogeneity that motivates sequential orchestration.
References:
See (2604.01086) for full details. For related works: [snell2024scaling], [wu2024inference], [ao2025optimizing], and [huang2026optimal].