- The paper presents a hybrid controller that uses DRL for rapid task initiation and bounded extremum seeking for online adaptation post-contact.
- It combines DDPG-based manipulation with supervisory switching to handle nonstationary dynamics like variable friction and time-varying goals.
- Empirical results demonstrate that the ES-DRL approach significantly outperforms pure DRL in maintaining robust performance under distribution shifts.
Deep Reinforcement Learning for Robotic Manipulation under Distribution Shift with Bounded Extremum Seeking
Introduction
This work conducts a rigorous investigation into the integration of Deep Reinforcement Learning (DRL)—specifically Deep Deterministic Policy Gradient (DDPG)—with bounded Extremum Seeking (ES) for enhanced robust manipulation in the presence of distribution shift. Classical DRL approaches exhibit strong in-distribution capabilities on contact-rich manipulation tasks such as pushing and pick-and-place; however, they remain prone to significant performance collapse when exposed to systemic perturbations at deployment, including changes in contact conditions, spatially varying friction, or time-varying goal references. The authors introduce a supervisory hybrid architecture where RL provides fast task entry at the start of each episode, and, after contact initiation, bounded ES adapts the control law online in response to distributional mismatches unencountered during training.
The manipulation policies are developed within the Fetch Robotics simulation framework, leveraging the FetchPush and FetchPickAndPlace environments. DDPG is employed in a goal-conditioned setup with randomized object initial positions and goals to mitigate overfitting. The observation space accounts for all relevant proprioceptive and exteroceptive signals, including gripper state, relative object displacement, and velocities. Control is performed in a 4-dimensional action space comprising planar/vertical end-effector adjustments and gripper commands.
The reward structure incorporates shaped, dense feedback that explicitly penalizes distance from object-to-end-effector and object-to-goal, with a terminal bonus on goal attainment within tolerance δ=0.05.
Under these settings, DDPG achieves high asymptotic success rates across multiple tasks within the training distribution.
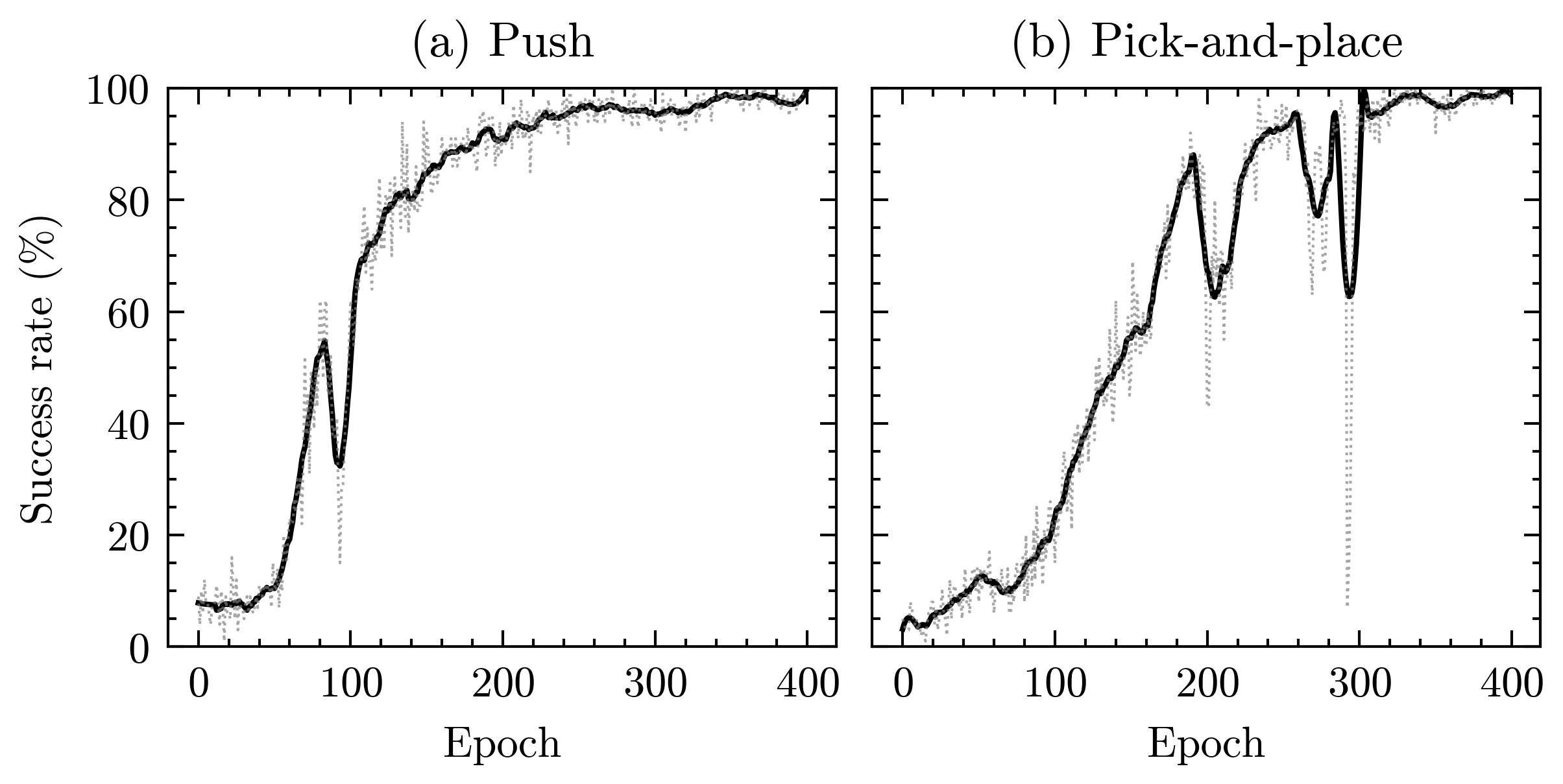
Figure 1: Training success rates for the Fetch push and pick-and-place tasks under DDPG; smoothed curves (solid) indicate convergence to high performance in-distribution.
Hybrid ES-DRL Controller Architecture
The ES-DRL controller utilizes two distinct feedback pathways. The RL component is responsible for rapid approach and reliable contact initiation, leveraging the latent task structure encoded during actor training. Once meaningful physical interaction is detected—signaled via a supervisor-generated binary flag—the ES module takes over, initialized from the last RL action to maximize continuity.
The core supervisor switching logic is as follows:
- Prior to contact, βt=1 and the executed action is purely RL.
- After contact acquisition (t≥tc), βt=0 and control is handed over to ES, which adapts only the Cartesian coordinates while holding the gripper fixed post-grasp.
This division reflects the complementary strengths of RL (effective in known regimes, sparse reward navigation) and ES (model-free online adaptation robust to analytic uncertainty and nonstationarity).
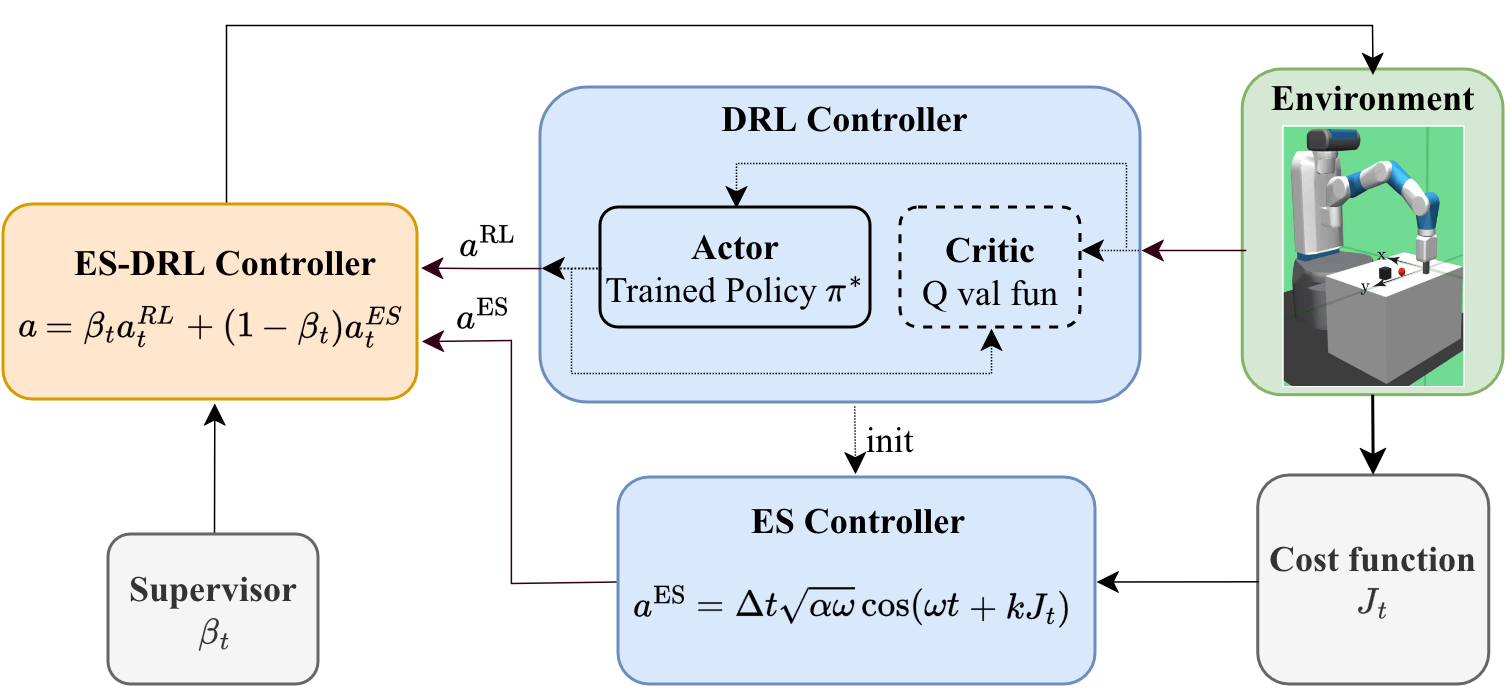
Figure 2: Architecture of the ES-DRL controller, with a supervisor governing the binary handoff from RL to ES upon contact detection.
Robustness under Distribution Shift
Spatially Varying Friction
To quantify policy robustness, evaluation is conducted on a workspace partitioned into zones of heterogeneous friction, (μ=0.8,1.2,1.5), while both RL and RL+ES policies are trained under a nominal single friction coefficient. In the fixed-goal scenario:
- RL-only degrades substantially upon entering high-friction regions due to the induced mismatch in end-effector to object motion mapping, losing contact entirely after coping with only moderate frictional shift.
- Standalone ES fails to establish a meaningful task-oriented frame and can even drive the object out of the workspace due to lack of prior knowledge or informative reward gradients in free space.
- The hybrid ES-DRL controller preserves effective object transport, tracking to the goal despite gross changes in frictional properties not encountered during training.
Moreover, with a time-varying goal, RL-only again fails early as the nonstationary reference and frictional nonuniformity jointly exceed the policy's generalization envelope. ES-DRL, by contrast, adapts online, maintaining trajectory tracking significantly closer to the moving target.
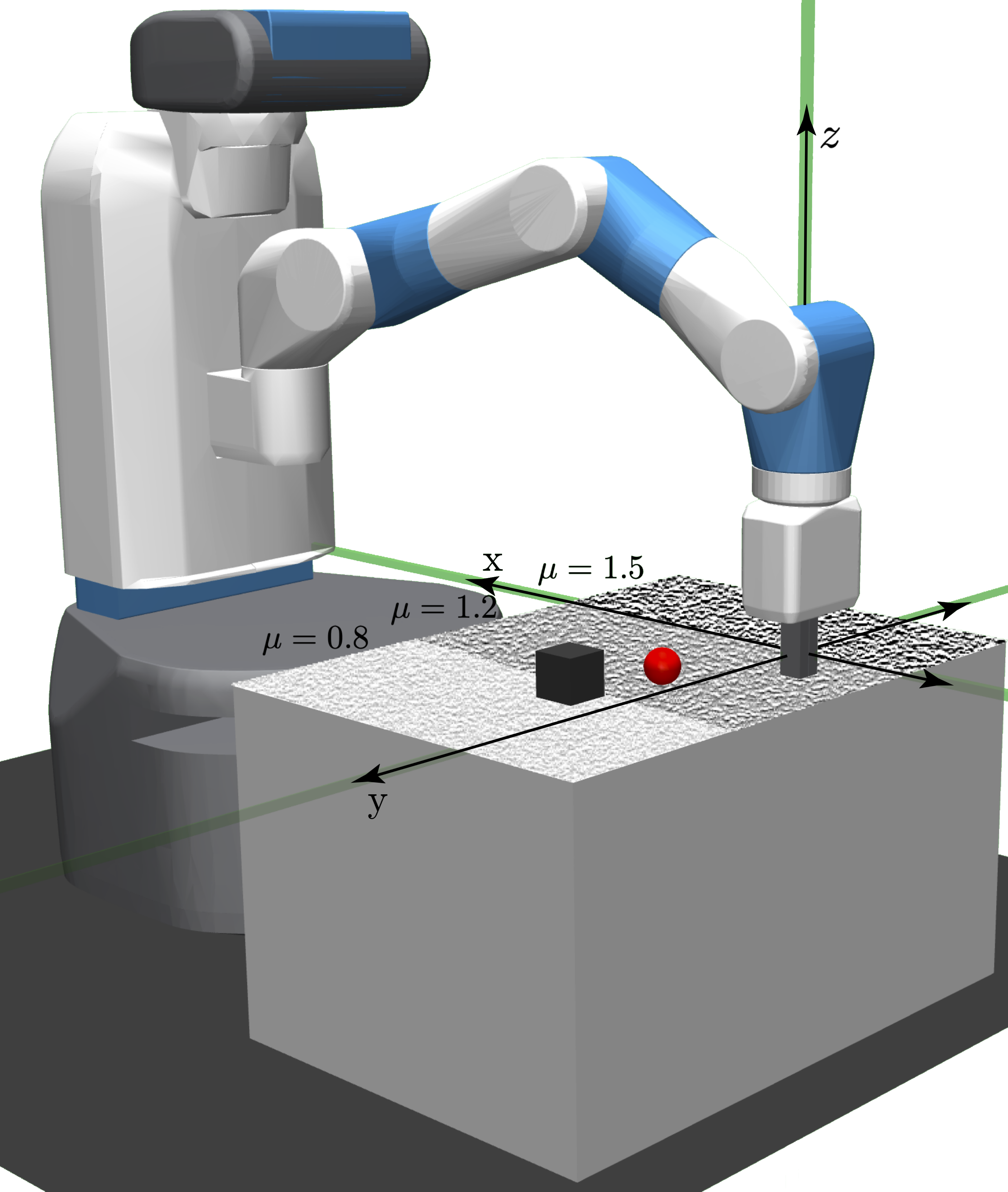
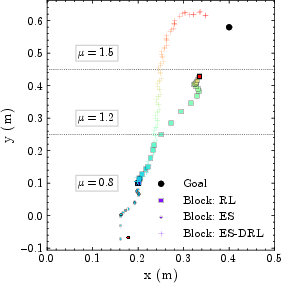
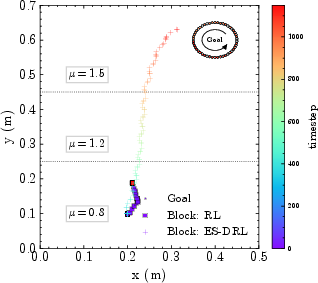
Figure 3: (Left) Workspace with frictional heterogeneity; (Middle) RL and ES baselines fail in high-friction or out-of-distribution regions, while ES-DRL reliably achieves the goal; (Right) ES-DRL alone tracks time-varying goals.
3D Pick-and-place with Time-varying Trajectories
In more complex 3D pick-and-place tasks, the target undergoes simultaneous circular and vertical variation. RL-only controllers, despite being trained to completion on fixed-goal variants, show poor generalization, failing to maintain object transport accuracy beyond the initial nominal regime post-grasp. The ES-DRL architecture, leveraging bounded ES for adaptive post-contact policy refinement, substantially reduces the tracking error relative to RL-only, delivering superior reference following even as the goal evolves dynamically.
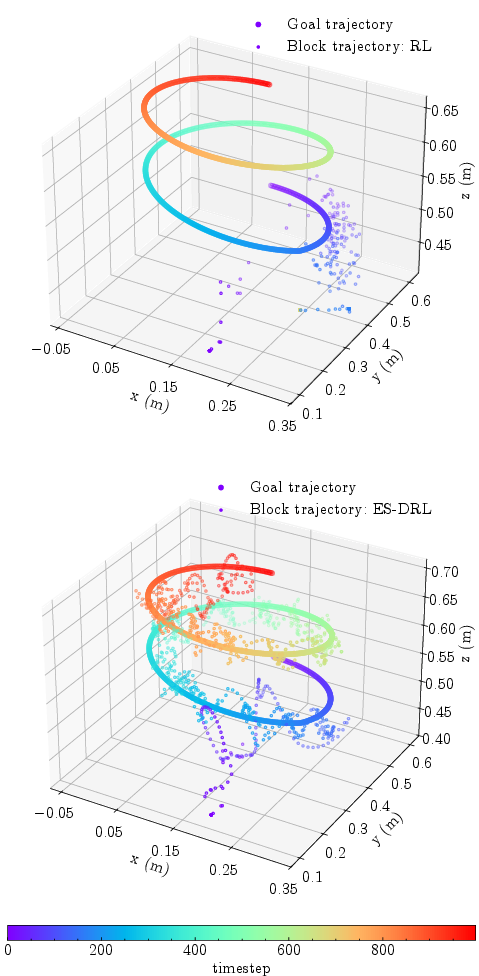
Figure 4: RL-only fails at tracking a time-varying 3D goal post-contact, whereas ES-DRL maintains tight adherence to the reference trajectory.
Theoretical Guarantees and Controller Properties
The authors provide a stability proposition for the ES phase post-contact. Under mild technical conditions, for any performance tolerance ϵ>0, appropriate selection of the ES gain and excitation frequency guarantees convergence to an ϵ-ball around the goal, regardless of unknown spatial friction, as long as contact is maintained. The switching law is proved to preserve continuous adaptation and ensures that ES-enhancement does not stall as long as the distribution shift is primarily encountered after contact initiation.
Implications and Future Directions
This research advances the state-of-the-art in DRL for robotic manipulation by introducing inference-time policy adaptation without retraining or explicit domain randomization. Notably, it demonstrates that:
- Out-of-distribution performance in contact-rich tasks is significantly enhanced by hybridizing end-to-end RL with model-free, bounded ES adaptation.
- ES-DRL controllers maintain robustness under abrupt or persistent contact condition changes, including high friction and nonstationary references, which are infeasible to cover exhaustively during RL training alone.
- Critically, the architecture leverages RL where it is most sample-efficient and adaptive control where RL's generalization fails, producing a principled and highly modular design.
Practical deployment of the ES-DRL hybrid could allow manipulation stacks to operate reliably under nonstationarity, unmodeled wear, or other phenomena that drive the system off-policy at inference. Theoretically, the modular handover approach invites further research into more nuanced supervisor policies, e.g., repeated RL/ES switching or confidence-triggered handoffs, and generalization to other partially observable or hybrid dynamical systems. Extending bounded ES to support piecewise or repeated interaction cycles offers a promising direction for future adaptive manipulation frameworks.
Conclusion
The hybrid ES-DRL controller studied here substantively improves the distributional robustness of robotic manipulation by pairing high-capacity RL policies with bounded extremum seeking adaptation at deployment. Empirical results—encompassing spatial heterogeneity and dynamic references—demonstrate that this modular approach is capable of both rapid policy execution and robust online correction in the face of distribution shift. Theoretically, the approach enjoys bounded performance guarantees post-contact. This methodology is a compelling candidate for robust manipulation in settings where analytic models and exhaustive RL retraining are infeasible.

