- The paper introduces a residual decomposition framework that separates invariant classwise corrections from context-sensitive pairwise terms to address long-tailed biases.
- The REPAIR algorithm leverages lightweight parametrization via multinomial logistic regression to jointly calibrate fixed and pairwise components for improved ranking accuracy.
- Empirical results demonstrate substantial gains, including a 19.4% improvement in Hit@1 for rare disease benchmarks, highlighting the method’s effectiveness under domain shifts.
Residual Decomposition for Long-Tailed Reranking: Summary and Analysis
Motivation and Problem Setting
Long-tailed classification presents a persistent challenge due to the dominance of frequent classes, inducing systematic bias against rare classes and manifesting as degraded ranking at inference. Post-hoc logit adjustment is a common mitigation, leveraging classwise frequency to calibrate logits with a fixed offset. However, empirical evidence and theoretical analysis indicate that fixed per-class corrections can fail when ranking errors exhibit substantial context-dependent variation. The key insight is that the Bayes-optimal correction may include both invariant (classwise) and context-sensitive (pairwise) terms, and the latter cannot be absorbed by traditional fixed-class rerankers.
Theoretical Framework: Residual Decomposition
The paper formalizes reranking as operating on a fixed shortlist of k top classes predicted by a base model. It establishes that the residual between the Bayes-optimal score and the base score for each label decomposes into:
- Classwise Component: Constant per class, correctable by per-class offsets (e.g., logit adjustment).
- Pairwise Component: Depends on both the input and the rival classes in the shortlist; encodes context-driven variability.
Theoretical results (Theorem 1) rigorously characterize the circumstances where classwise correction suffices. Specifically, if all necessary orderings among labels (for all input/shortlist contexts) are compatible, a fixed vector of offsets can achieve the Bayes-optimal ordering. However, "contradictory" pairs—label pairs for which the preferred ranking reverses across contexts—invalidate the sufficiency of any fixed offset: context-dependent pairwise corrections are required.
The REPAIR Algorithm: Pairwise Correction via Lightweight Parametrization
Building on this decomposition, the authors introduce REPAIR (Reranking via Pairwise Residual Correction), a two-component reranker for shortlists:
- Classwise term (ay): Per-class offsets, learned from held-out calibration data and regularized using empirical-Bayes shrinkage for sample-efficiency on rare classes.
- Pairwise term (ℓy(x,S)): A linear function over competition and similarity features computed for every label-rival pair on the shortlist, parameterized by a shared vector θ.
Both ay and θ are fitted through multinomial logistic regression on covered calibration examples (i.e., where the true label is present in the shortlist). Key pairwise features include: score gap, rank gap, log-frequency ratio, and domain-specific similarity (e.g., taxonomic, WordNet, phenotypic). These features encode both model-driven uncertainty and intrinsic class confusion.
Analysis of Synthetic and Real-World Scenarios
The decomposition’s necessity and sufficiency are validated in controlled synthetic experiments:
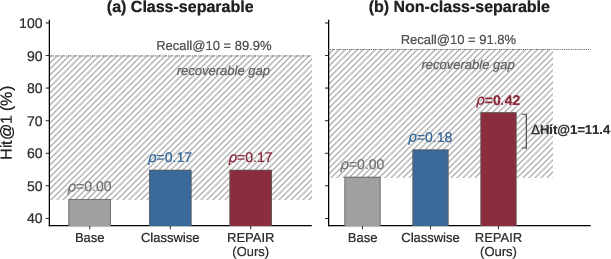
Figure 1: Synthetic validation confirms that in class-separable settings, classwise correction suffices; in the presence of contradictory pairs, REPAIR closes significantly more of the recoverable gap.
In non-class-separable synthetic settings, REPAIR yields more than double the error reduction as compared to classwise correction alone.
Empirical ablations further demonstrate that in class-separable data regimes, classwise and pairwise components appear redundant (their difference is negligible). In contrast, when contradictory pairs or high context-dependent confusion are prominent, both terms jointly contribute—neither alone suffices.
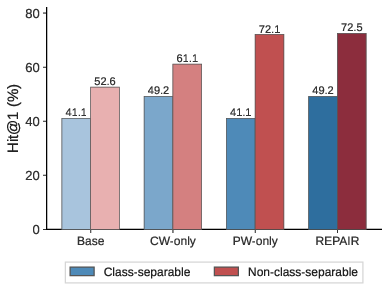
Figure 2: Synthetic ablation isolates the contribution of classwise and pairwise components; only their combination achieves maximal performance in non-class-separable regimes.
Empirical Evaluation Across Domains
Vision Benchmarks
Experiments on iNaturalist, ImageNet-LT, and Places-LT indicate that ranking errors are predominantly class-separable. Learned classwise corrections perform on par or slightly better than closed-form logit adjustment; introducing the pairwise term yields only marginal improvement.
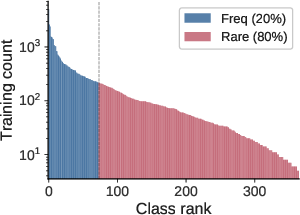
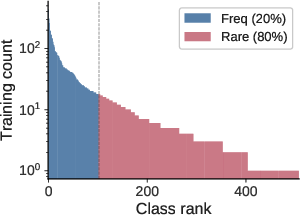
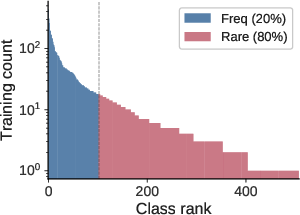
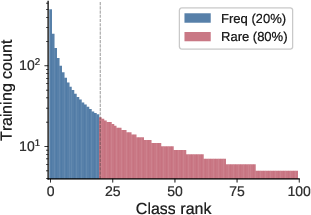
Figure 3: Results on iNaturalist demonstrate that pairwise correction adds little incremental gain, supporting the near-class-separable diagnosis in large-scale vision data.
Rare Disease Diagnosis
Conversely, in clinical benchmarks (GMDB, RareBench), both ranking error rates and pairwise confusion are elevated, especially under distributional shift (e.g., the text-only OOD RareBench). Here, REPAIR achieves substantial gains: on RareBench, Hit@1 is increased by 19.4% (absolute, 66.2% → 85.6%), and the hardest-rival flip rate more than triples. Bootstrap analysis confirms statistical robustness. Component ablations show that neither term alone can approach the full model's accuracy—joint learning is essential.
Diagnostics: Quantile and Shrinkage Analyses
The framework introduces "threshold dispersion" Dy as a quantifier of per-class context-dependent variability: classes with high Dy are more susceptible to contradictory pairs. Stratification by Dy quintile reveals that REPAIR’s gains over classwise correction are highly concentrated in high-variance classes, consistent across synthetic and real datasets (notable on GMDB and, to a lesser extent, ImageNet-LT and Places-LT).
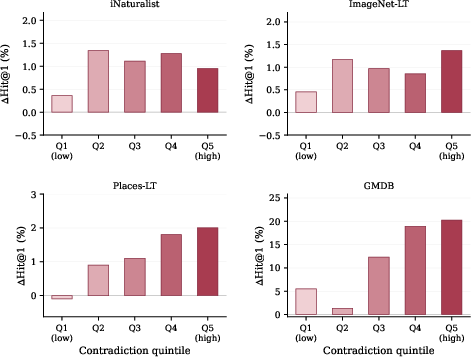
Figure 4: On real benchmarks, the advantage of REPAIR over classwise correction grows with the mean threshold dispersion ay0, especially in GMDB and ImageNet-LT, precisely where theory predicts.
Additionally, shrinkage diagnostics confirm that empirical-Bayes regularization is particularly beneficial for rare classes with limited calibration data, reducing variance in learned offsets and improving tail accuracy.
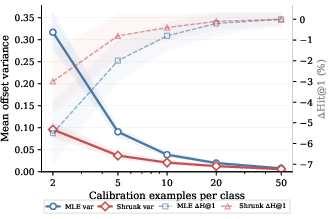
Figure 5: Shrinkage is most critical when rare classes have very few calibration samples, reducing offset noise and improving head-tail trade-off.
Implications and Future Directions
Practical implications include:
- Post-hoc deployability: REPAIR operates on fixed base model shortlists and does not require model retraining, making it lightweight and easily deployable in real systems.
- Domain flexibility: By separating general competition-based features from domain-specific similarity metrics, REPAIR is adaptable to a range of problem settings, though potential gains hinge on the quality and appropriateness of available features.
Theoretical implications are twofold:
- The delineation of when logit adjustment must necessarily fail suggests a direction for benchmarking and dataset analysis: quantifying context-driven contradiction structures in real data can predict the expected utility of pairwise reranking.
- REPAIR’s success motivates further exploration of richer pairwise or higher-order interactions, possibly leveraging embedding similarity or learned relational structures between classes, moving beyond hand-crafted features.
Conclusion
This work formalizes and empirically validates a residual decomposition view of post-hoc reranking for long-tailed classification. The resulting REPAIR method achieves state-of-the-art reranking performance on rare disease diagnosis and robust, competitive results on large-scale vision tasks, explained directly by the prevalence (or lack thereof) of pairwise context-dependent confusion. These insights clarify both the limits of frequency-based calibration and the importance of tailoring reranking methods to dataset-specific competitive structures, with practical deployment value for real-world, high-stakes applications in rare event and clinical domains.

