- The paper demonstrates that high-capacity LLM tutors consistently align with a Bayes-Optimal mentalizing model in graph-based teaching, mirroring human performance.
- It employs a rigorous graph teaching task to compare LLM strategy selections with human data, using cognitive model fitting to differentiate between model-based and heuristic approaches.
- Scaffolding interventions show limited impact on altering teaching choices, highlighting that LLM mentalizing may stem from pre-trained heuristic compression rather than explicit theory-of-mind reasoning.
Assessing Mentalizing in LLM Teaching: An Analysis of "Do LLMs Mentalize When They Teach?" (2604.01594)
Introduction
This paper systematically quantifies the teaching strategies employed by contemporary LLMs when operating in a formalized graph-based teaching environment. Specifically, the authors investigate whether LLM-based tutors select pedagogical actions via explicit mentalizing—that is, by modeling the learner’s knowledge state and optimizing information selection accordingly—or instead adopt simpler, model-free heuristics. By deploying a series of controlled experiments grounded in cognitive science research on human teaching, the study aligns simulated LLM teachers and human data on an identical decision problem, leveraging cognitive model fitting for interpretability and theoretical insight.
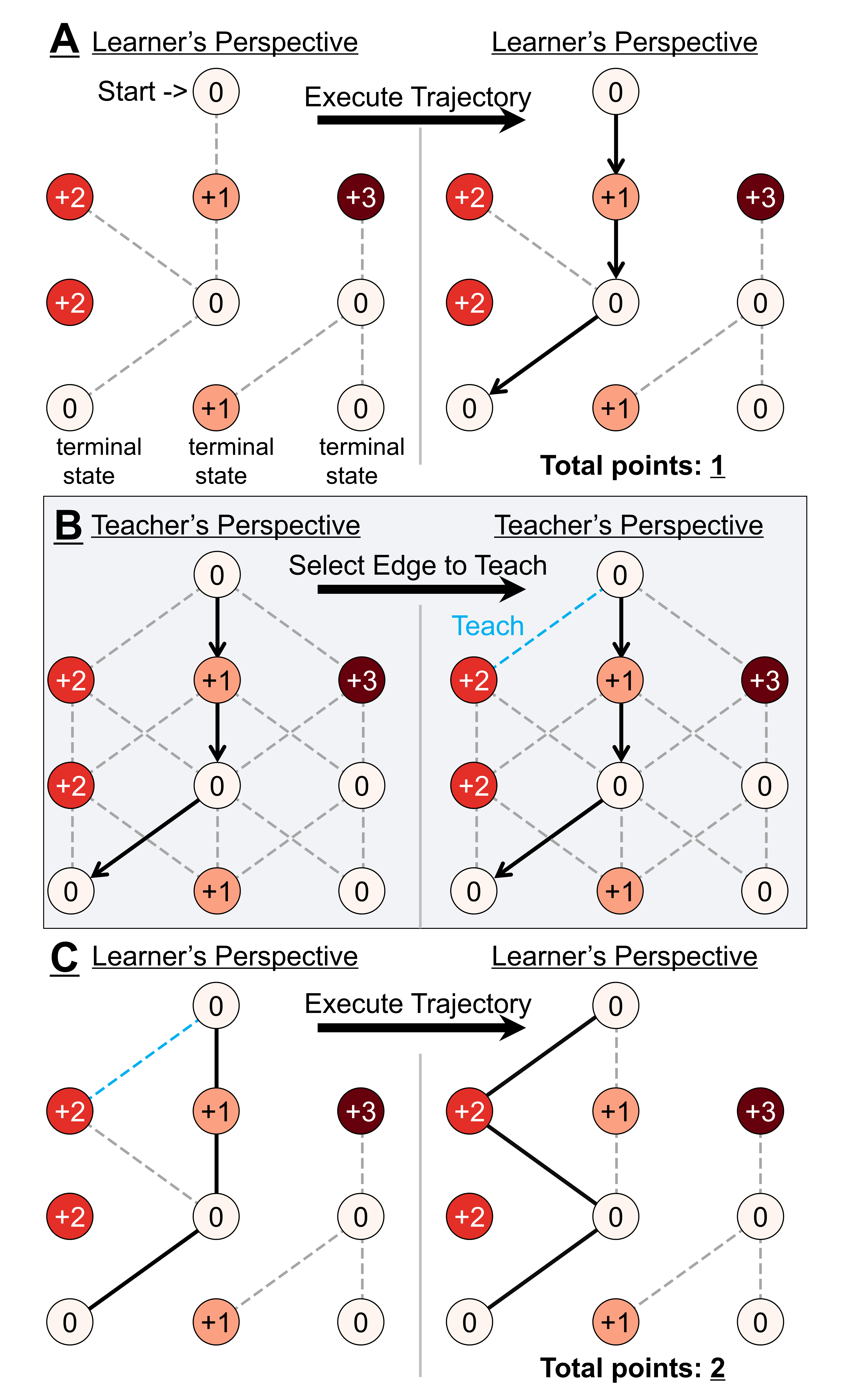
Figure 1: The Graph Teaching Task presents LLM "teachers" with a learner’s path and task structure, requiring them to select an edge to reveal so as to optimally improve the learner's subsequent trajectory.
Experimental Design and Methodology
The primary experimental paradigm is the Graph Teaching task, previously validated in human pedagogy research. In this setup, the LLM acts as a teacher observing a learner’s chosen trajectory through a reward-annotated, directed acyclic graph. The teacher must select one edge to reveal, with the goal of maximizing the learner’s future optimal reward. Crucially, the true learner is a noiseless RL agent with limited knowledge of the graph structure, and there is no within-experiment feedback—each trial is independent.
LLM responses on each trial are fit with a battery of candidate cognitive models:
- Bayes-Optimal Teacher: Performs full inverse planning to infer the learner's knowledge state from trajectory, optimizing expected teaching utility.
- Weaker Bayesian Variants: Replace inverse planning with less informative inference (e.g., behavioral feasibility, flat priors).
- Heuristic Baselines: Model-free rules such as summing node rewards (Reward Heuristic), depth heuristics, or mixtures.
- Non-Mentalizing Utility Models: Pure puzzle solvers that ignore the learner, including tabular Q-learning and path average utility approaches.
Simulated LLM teachers (multiple instances per model/condition) receive only task structure, rewards, and the learner’s trajectory as input, with conversation history preserved across trials for each individual "teacher". Baseline and scaffolding intervention experiments probe both spontaneous and externally guided strategy selection.
Key Findings: Baseline Teaching Behavior and Model Alignment
LLMs, when tasked with graph-based teaching under these experimental conditions, generally exhibit high and stable teaching performance with minimal trial-wise learning, mirroring human levels of consistency. However, a crucial result is that most high-capacity LLMs generate teaching choices that align closely with a Bayes-Optimal mentalizing model, as indexed by individual-level cognitive model fits (Figure 2).
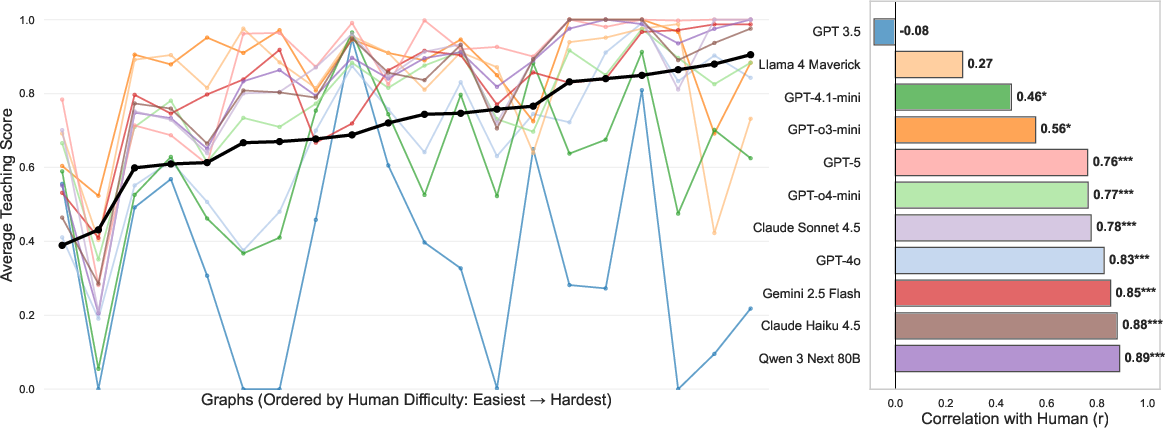
Figure 3: Human–model performance profiles: LLMs reproduce human difficulty gradients across graph instances, with most models demonstrating strong correlation (r>0.7) with humans on graph-wise teaching scores.
The teaching score distributions highlight that, unlike human cohorts—who are bimodally split into heuristic and mentalizing strategists—most LLM teachers cluster near the high-performing, (ostensibly) model-based end of the spectrum (Figure 4). Notably, GPT-4o matches human tutors not only in overall performance but also in response variability.
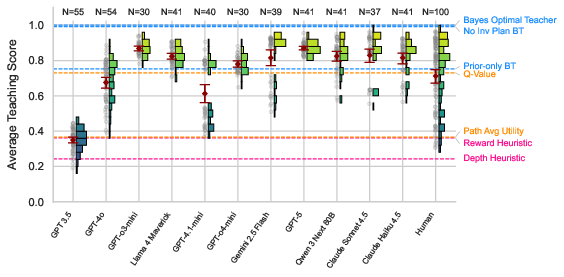
Figure 4: Teaching score distributions: LLMs concentrate in the upper range, matching the performance of high-mentalizing human teachers.
Cognitive model comparison (using BIC) demonstrates that, for the majority of LLMs, the Bayes-Optimal Teacher is the best account of observed output. Exceptions—where heuristic or non-mentalizing fits dominate—are largely restricted to GPT-3.5, Llama-4 Maverick, and select smaller-capacity or less-aligned models.
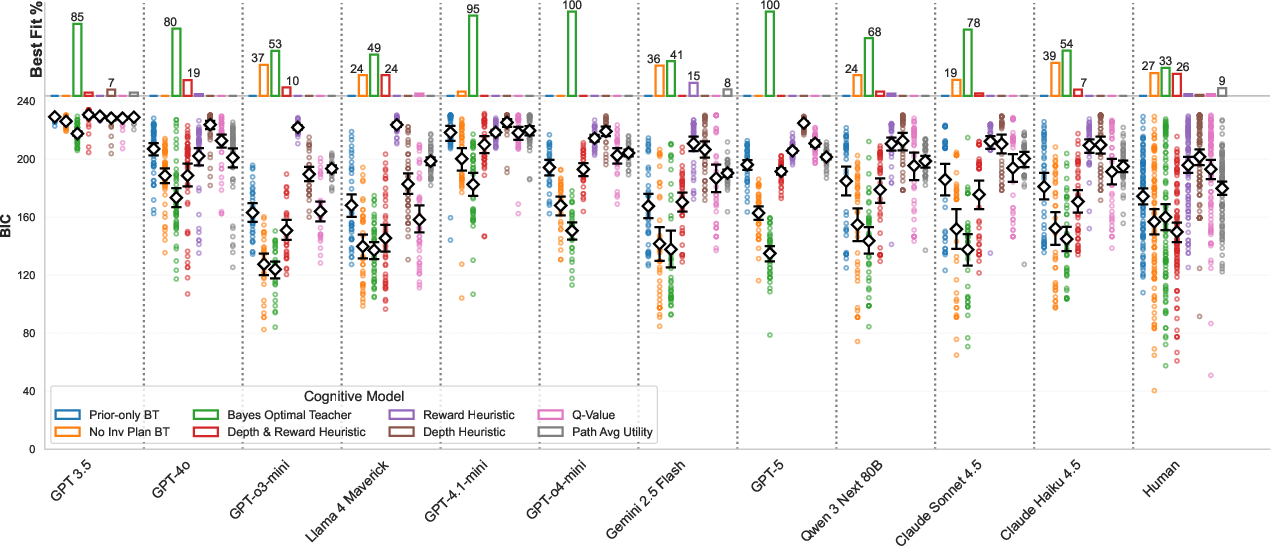
Figure 2: Proportion of teachers best fit by each cognitive model, for LLMs and humans. Bayes-Optimal model predominates among LLMs; humans exhibit a mixed model distribution.
Structural Sensitivity
Item-level performance further substantiates that most LLMs are sensitive to underlying graph properties that modulate teaching difficulty for human subjects (Figure 3). This implies not only that high-performance models approach human-level outcome benchmarks, but that their solution policies track similar problem features.
Scaffolding Interventions and Strategy Modulation
The second experimental phase introduces auxiliary scaffolding steps during training: either requiring the model to nominate potentially unknown (Inference Scaffolding) or high-reward (Reward Scaffolding) edges prior to the teaching action. In humans, such interventions robustly bias strategy selection—heightening model-based teaching or amplifying heuristic tendencies, with corresponding downstream impacts on test performance.
In contrast, LLMs display dissociation between prompt compliance and altered policy: while models can execute the scaffolded steps in alignment with instructed strategies (Figure 5), these interventions do not reliably enhance subsequent teaching choices on out-of-scaffold, heuristic-incongruent test items and can even depress performance, especially for Reward Scaffolding.
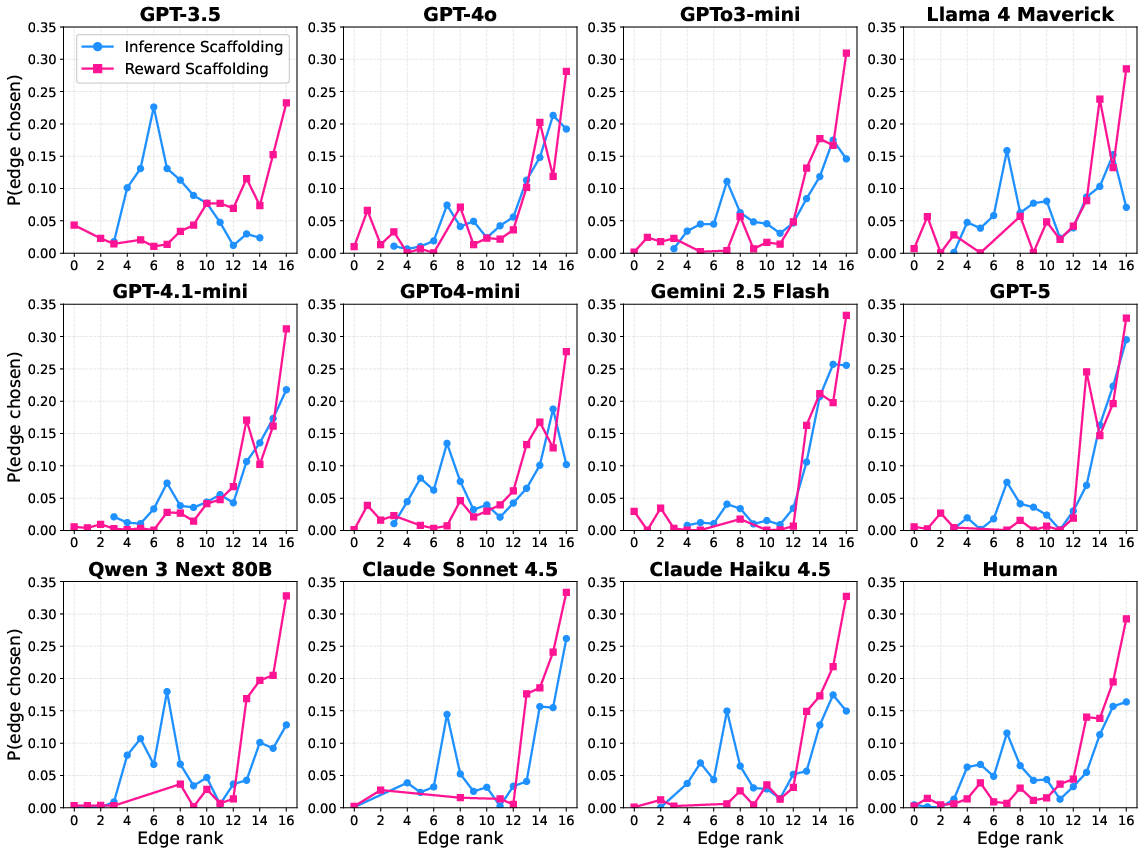
Figure 5: LLMs comply with auxiliary scaffolding instructions during training, aligning edge selections with underlying inference or reward-oriented criteria.
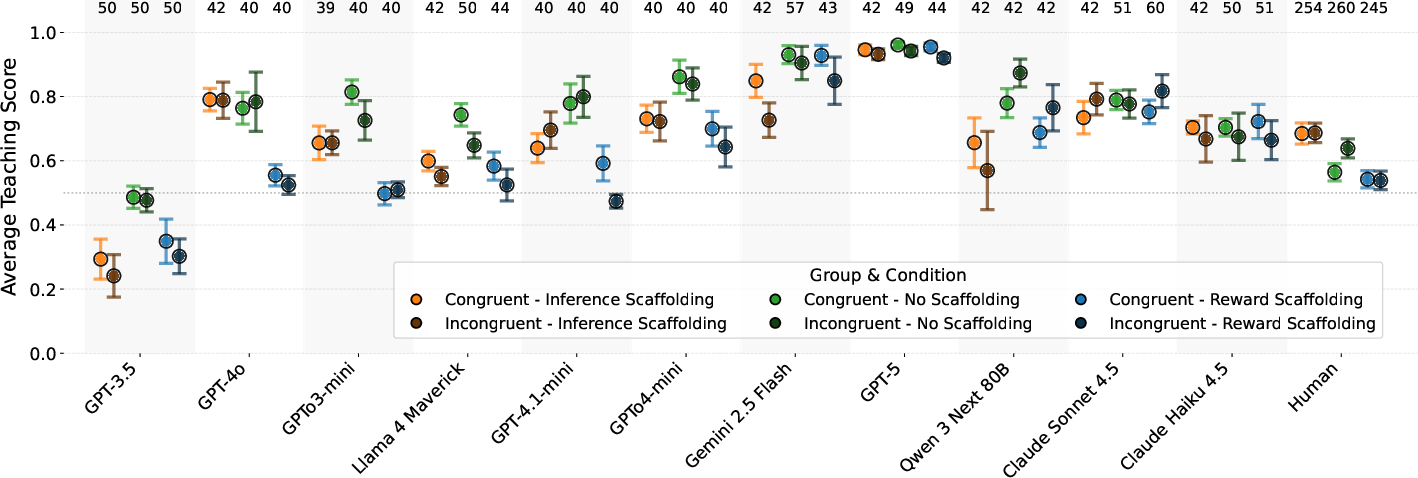
Figure 6: Test-phase teaching scores after training with scaffolding: No reliable benefit from Inference Scaffolding; Reward Scaffolding reduces performance.
Cognitive model fits (Figure 7) confirm that, while the Bayes-Optimal model remains the best descriptive account post-scaffolding for most LLMs, Reward Scaffolding can yield localized shifts towards heuristic-consistent model fits. This shift, however, is substantially weaker and less robust than observed in human teacher data.
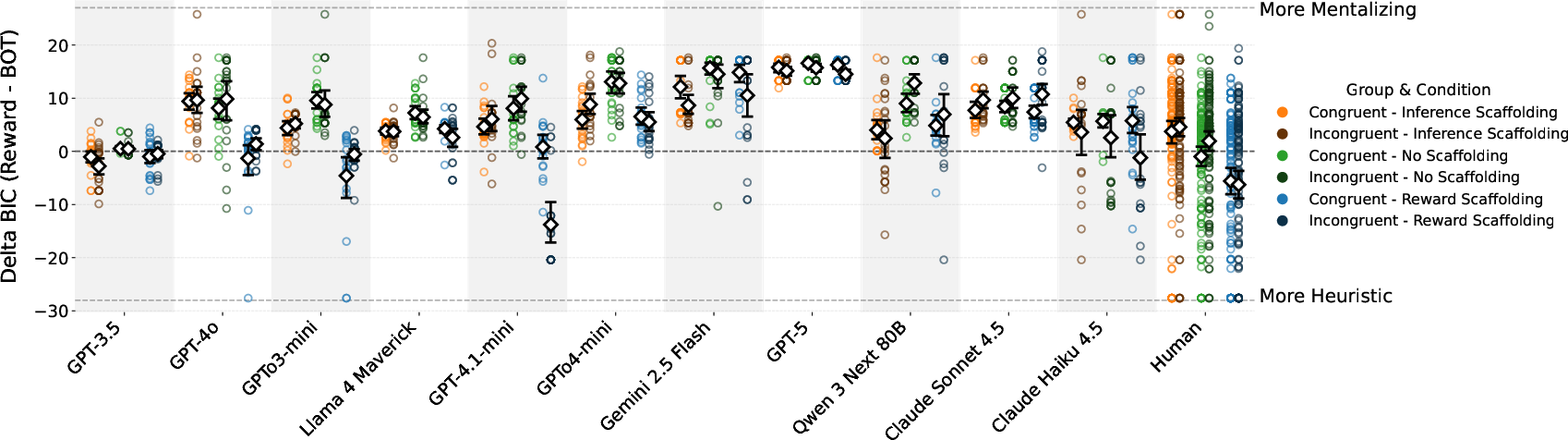
Figure 7: BIC difference between Reward Heuristic and Bayes-Optimal models at test. Reward Scaffolding reduces Bayes-Optimal fit advantage for some LLMs but does not induce a paradigm shift.
Theoretical and Practical Implications
Mechanistic Insights
The observed predominance of Bayes-Optimal teaching fits in LLMs, even in the absence of test-time feedback and under variable structural priors, underscores the surprising degree to which large generative models can exhibit mentalizing-aligned instructional policies. However, the discussion raises reservations about whether this reflects an explicit maintenance of Theory-of-Mind (ToM)-like agent models, or functionally compressed heuristics acquired via pretraining that are simply highly performant on the evaluated distributions. The inability to modulate strategy through lightweight scaffolding, as seen in humans, suggests that LLMs treat auxiliary prompts as isolated sub-tasks rather than as cost-reducing cognitive tools that propagate into final choice behavior.
Resource-Rationality and Cost Models
The disparity in strategy selection flexibility between humans (who adopt heuristics when cognitive cost is high or when reinforced by context) and LLMs is interpretable through resource-rationality frameworks. LLMs, operating at inference without resource pressure and having no subjective cost for complex computation, default to "mentalizing" wherever representational capacity and training distribution permit. This hypothesis suggests new directions for probing shortcut reliance in LLMs: constraining generation budgets, context window sizes, or real-time latency could potentially induce shifts toward heuristic teaching, paralleling human resource adaptation.
Limitations and Future Directions
Crucial limitations remain: the current evaluation cannot discriminate between genuine, online learner-model computation and amortized, high-capacity heuristics that mimic it. More adversarial graph distributions, structured reward/transition decoy situations, or meta-learning interventions will be required to draw definitive conclusions regarding the mechanistic basis of LLM "mentalizing". Furthermore, the ineffectiveness of lightweight scaffolding points to the need for interventions that are more explicitly coupled to the LLM action-selection pipeline, possibly via chain-of-thought steering or architectural modifications.
Conclusion
This study demonstrates that most leading LLMs, when tasked with instructing a partially informed learner in a structured graph navigation task, produce teaching actions that are well explained by a Bayes-Optimal learner-modeling framework. However, evidence suggests that this behavior may not originate from explicit, human-analogous ToM computation, and LLMs do not exhibit the same strategy selection flexibility as humans in response to cost-reducing scaffolds. These findings have salient ramifications for both mechanistic interpretability of LLM tutors and the design of practical interventions to improve AI pedagogy. Future investigation should focus on disentangling genuine model-based reasoning from emergent shortcut policies and probing the circumstances under which LLMs revert to model-free heuristics.
Reference:
"Do LLMs Mentalize When They Teach?" (2604.01594)

