- The paper introduces a two-stage approach that combines LLM-based differentially private synthetic data generation with real-data validation to facilitate educational data sharing.
- It leverages DP-protected summary statistics to produce high-fidelity synthetic data while empirically tracking privacy risk via worst-case membership inference privacy.
- Empirical results demonstrate comparable synthetic fidelity to DL methods and moderate privacy leakage, with only 36% of significant synthetic findings validated on real data.
A Two-Stage, Training-Free Framework for Practical Differentially Private Educational Data Sharing
Introduction and Problem Setting
The paper "Training-Free Private Synthesis with Validation: A New Frontier for Practical Educational Data Sharing" (2604.01821) addresses a vital issue in educational research: enabling legitimate secondary analysis of real-world data (RWD) under stringent privacy constraints. Although DP-SDG has emerged as the canonical solution for privacy-preserving data release, conventional implementations demand considerable deep learning (DL) expertise and extensive engineering, making large-scale deployment in education infeasible—especially due to the small, high-dimensional, and fragmented nature of typical educational datasets. The proposed approach is a two-stage, training-free framework combining LLM-based DP-SDG (training-free synthetic data generation using LLMs guided by differentially private summary statistics) and a procedure for on-demand, non-DP real-data validation executed remotely by data custodians.
Methodology: Two-Stage Data Sharing
The proposed framework operates in two distinct stages to tackle the utility–privacy trade-off, risk of privacy leakage, and real-world usability bottlenecks inherent to current DP-SDG pipelines. The process generalizes naturally to both one-shot and multi-shot (multi-cohort, temporally iterative) educational data sharing scenarios.
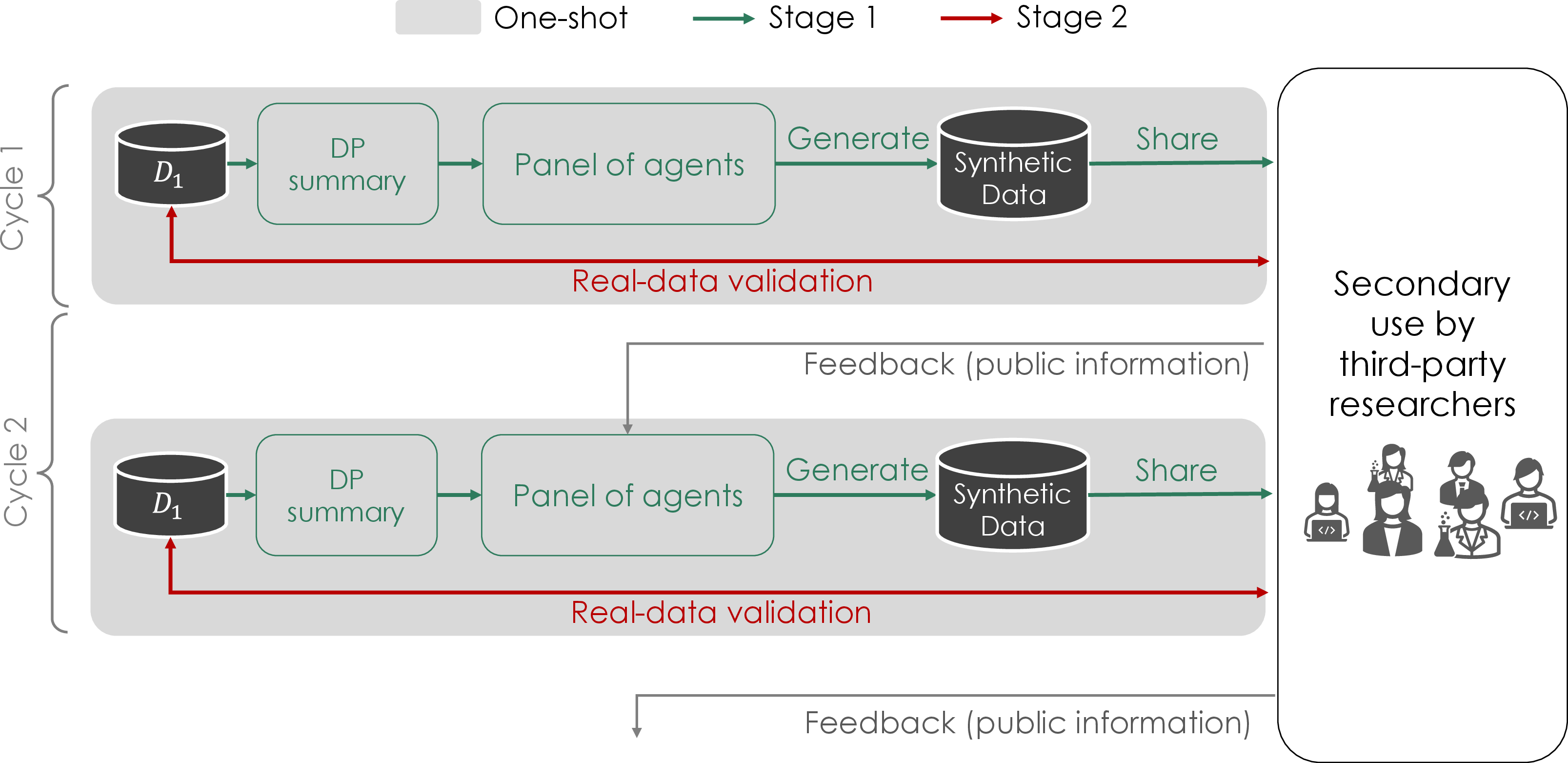
Figure 1: Overview of the two-stage method in a multi-shot setting, with iterative cycles of synthetic data generation and validation feedback for continual adaptation.
Stage 1: LLM-based DP-SDG is performed by computing DP-protected summary statistics (e.g., means, counts, or proportions of zeroes capturing the global structure and sparsity of the educational logs), then prompting LLMs with those statistics to generate high-fidelity synthetic data. The architecture ensures formal DP by the post-processing property: as the LLM samples are strictly conditioned on DP-computed summaries, no additional privacy cost accrues from the generative stage, circumventing the modeling, training, and hyperparameter-tuning burden of DL-based approaches.
Stage 2: Real-Data Validation allows downstream (third-party) analysts to submit code to be executed against the real, private data enclave, with responses restricted to aggregate/statistical results to preclude trivial re-identification or reconstruction. Statistical Disclosure Control (SDC) tools are optionally used to further mitigate reconstruction risk. Importantly, this stage eschews DP to maximize analytical fidelity, explicitly accepting a limited, auditably quantifiable privacy risk.
The framework gracefully extends to a multi-shot setting, leveraging analyst feedback on discrepancies between synthetic and validation-based findings to condition and improve future synthetic data cycles. By design, the cumulative privacy loss is tracked through composition at the level of worst-case membership inference privacy (WMIP).
Theoretical Contributions: Privacy Accounting Beyond DP
The standard DP guarantee is not preserved through the non-DP validation interface of Stage 2. To provide an operational risk analysis, the authors employ worst-case membership inference privacy (fn,D-WMIP), which quantifies the empirical risk that an adversary can infer the inclusion of a particular individual in the private dataset after observing both synthetic and validation outputs.
Theoretical results demonstrate that, although WMIP is weaker and inevitably empirical (as opposed to DP, which is mechanism-enforceable and worst-case), the two-stage approach admits precise privacy tracking: the overall system’s privacy parameters compose as a “tensor product” of Stage 1 (DP) and Stage 2 (WMIP). A Gaussian variant (μ-GWMIP) is reported for single-parameter summarization. Importantly, while WMIP does not protect against data reconstruction attacks, it directly bounds the risk of membership and attribute inference, which are the primary concerns in educational sharing contexts.
Empirical Evaluation
Experimental Setup
The framework was evaluated on longitudinal, high-dimensional learning log data covering three years of lower-secondary students (n=120/year), assessing both statistical data fidelity and empirical privacy risks. Both one-shot and multi-shot sharing were simulated; multi-shot adaptation involved using feedback from real-data validation to enhance the generative prompt structure in subsequent LLM cycles. Real-world downstream analyses were conducted by four independent researchers in a realistic case study, with real-data validation requests accounting for varied query structures and outputs.
Synthetic Data Fidelity
Synthetic data quality was measured by the average Jensen-Shannon divergence (AJS) between real and synthetic data distributions, aggregating a suite of 24 summary statistics over student activity time series and achievement labels.
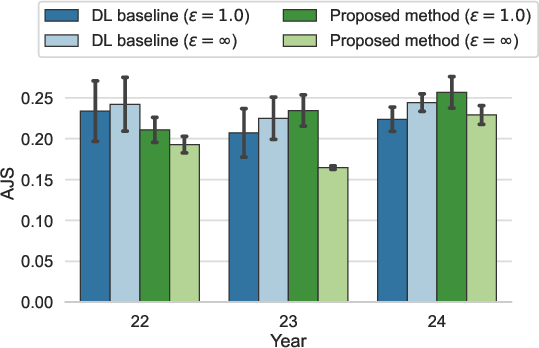
Figure 2: One-shot AJS comparison between the LLM-based method and the DL-based (VAE) baseline; lower values indicate higher fidelity.
The LLM-based method, despite being training-free and schema-agnostic, achieved AJS values comparable to DL-based approaches across all datasets, with negligible fidelity degradation. This key claim is supported across multiple seeds and confidence intervals, demonstrating that LLM-based DP-SDG can replace engineering-intensive DL synthetic pipelines in practical educational settings.
Inter-cycle improvements using feedback in the multi-shot regime were minimal for both LLM- and DL-based methods, suggesting diminishing marginal returns from iterative adaptation with the current feedback methodology.
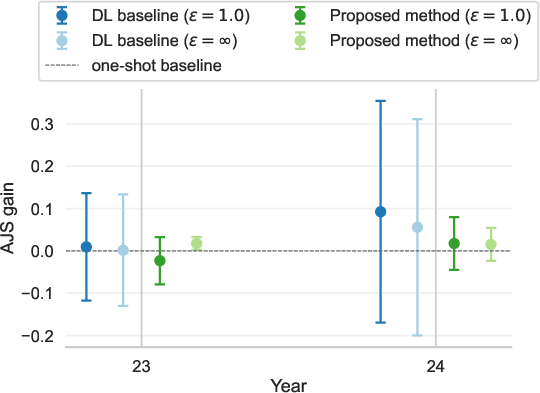
Figure 3: Gains in AJS (utility improvement) from adapting to the multi-shot setting for both methods, with negligible difference from their one-shot baselines.
Crucially, the paper highlights a divergence between statistical utility and real-world scientific value: only 36% of significant findings on synthetic data (aggregated epistemic precision across all datasets and users) were validated on the real data, underlining that standard synthetic fidelity metrics do not guarantee downstream analytic efficacy.
Privacy Risk Quantification
Membership inference risk was empirically quantified for each validation request using shadow data resampling and strong likelihood ratio (LiRA-style) attacks. Estimated μ-GWMIP parameters were plotted as a function of cumulative request index, allowing for audit and privacy cost tracking over time.
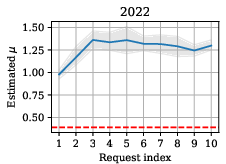
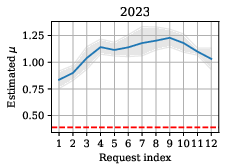
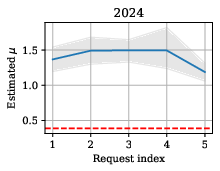
Figure 4: Empirical evolution of μ-GWMIP over sequential validation requests, with DP-only values as a dashed baseline.
The measured privacy leakage due to non-DP validation was moderate: privacy risk did not increase monotonically with the number of validation outputs and was primarily determined by the nature of the analysis, not output size. Notably, researcher P4—who focused on causal discovery (DirectLiNGAM)—introduced significantly higher MIA risk than others whose analyses were correlational, due to the heightened outlier sensitivity of the method.
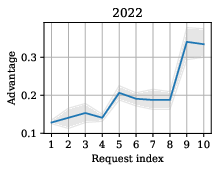
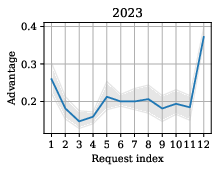
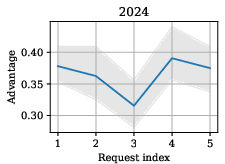
Figure 5: Trajectory of worst-case MIA advantage with cumulative validation requests per dataset.
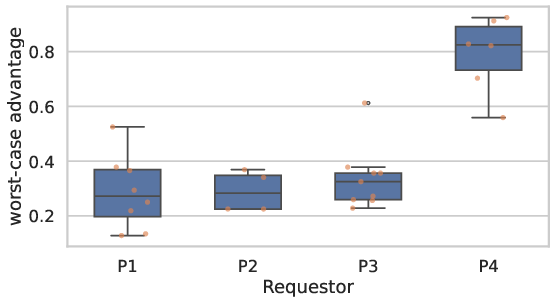
Figure 6: Per-participant, per-request breakdown of MIA advantage, highlighting the exposure from certain statistical techniques.
By correlating epistemic precision, privacy leakage, output size, and analysis type:
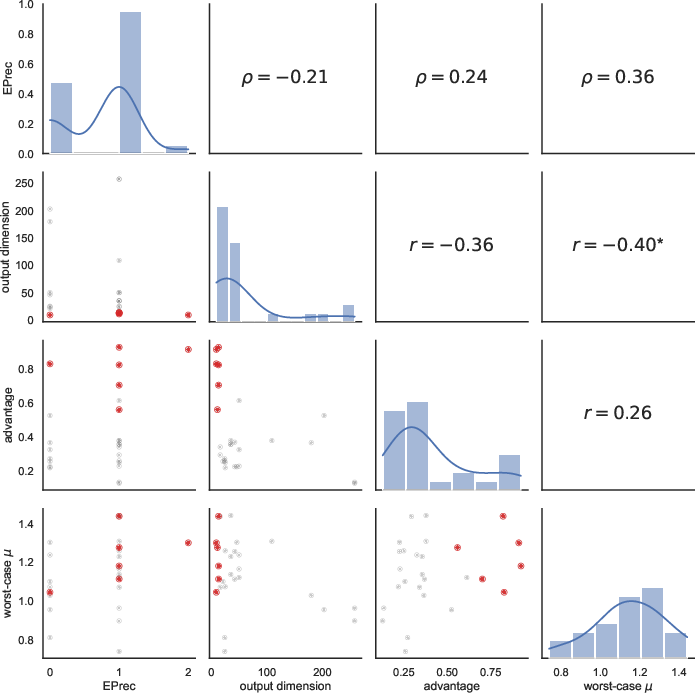
Figure 7: Pairwise relationships among epistemic precision, output dimension, MIA advantage, and μ-GWMIP, with outlying researcher P4 highlighted (red); significant statistical correlations are marked.
Findings confirm nuanced trade-offs: higher epistemic precision and privacy risk tended to coincide, and larger output sizes did not proportionalize with increased privacy risk, countering conventional intuition in Statistical Disclosure Control.
Implications and Directions for Practice and Research
Practical Implications:
- The two-stage approach democratizes private educational data sharing, lowering the technical barrier for data custodians and researchers, and providing provable membership privacy with auditable empirical guarantees.
- Data custodians must review validation requests with attention to the statistical robustness and disclosure characteristics of queries, rather than employing simple heuristics or output size quotas.
- Analysts must recognize the limited epistemic transfer between synthetic and real data in high-dimensional, small-sample educational contexts; DP fidelity does not guarantee scientific parity.
Theoretical Ramifications:
- This framework motivates further investigation into training-free, schema-flexible DP-SDG approaches—especially for high-dimensional complex data streams—using advanced LLM prompting/aggregation.
- Empirical privacy quantification via WMIP expands the analytical toolkit where full DP composition is unattainable, especially in real-world post-processing or hybrid validation systems.
- The observation of negligible utility gains from naive multi-shot adaptation invites research into optimal feedback structures and adaptive prompt engineering in multi-cohort data synthesis.
Limitations and Outlook:
The current case studies are limited in scale (n=120 per year, four analysts) and analytical diversity. More comprehensive adversarial risk assessments, alternative datasets, and real deployment trials in larger educational consortia remain necessary for broader validation. Additionally, while membership inference is principled for individual privacy, guarantees against reconstruction attacks—which threaten institutional policy even in the absence of re-identification—remain unaddressed in this framework.
Conclusion
This work advances the state-of-practice in privacy-preserving educational data sharing by operationalizing a simple, robust, and technically accessible two-stage system. The primary contribution is the illustration that training-free, LLM-driven DP-SDG with empirical, auditable privacy accounting can render high-dimensional educational RWD accessible for meaningful, privacy-respecting scientific inquiry. Practical deployment will require further improvement in real-world utility transfer, ongoing refinement of privacy accounting, and detailed governance frameworks for validation and disclosure control.

