- The paper demonstrates a unified framework that fuses streaming CTC decoding, acoustic features, and LLM-based semantics to achieve low-latency turn detection.
- It employs a four-stage training strategy to align speech and text modalities, significantly reducing errors in noisy, overlapping dialogue scenarios.
- Experimental results show that the multi-modal fusion in FastTurn yields superior accuracy and reduced interruption latency compared to existing baselines.
FastTurn: Unifying Acoustic and Streaming Semantic Cues for Low-Latency and Robust Turn Detection
Introduction
Full-duplex spoken dialogue systems require robust and low-latency turn detection to support natural, real-time conversational interaction. Classic approaches either use voice activity detection (VAD), which lacks semantic interpretability and suffers from high error rates in complex environments, or explicit turn prediction modules relying on ASR transcripts, introducing latency and degrading in overlapped/noisy conditions. The paper "FastTurn: Unifying Acoustic and Streaming Semantic Cues for Low-Latency and Robust Turn Detection" (2604.01897) presents a unified framework, FastTurn, which integrates streaming CTC decoding with acoustic features and leverages a test set derived from real human dialogues with challenging interaction phenomena.
Architecture and Methodology
FastTurn consists of three principal components: FastTurn-Semantic, an acoustic adapter, and a turn detector, with an architectural progression from text-dominated CTC-based cascading toward multi-modal fusion.
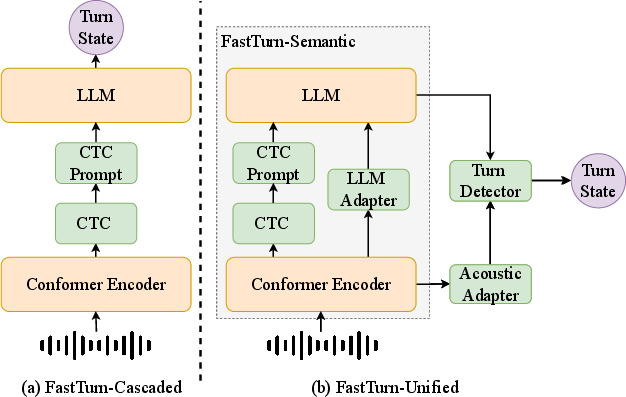
Figure 1: Model architecture: FastTurn integrates streaming CTC, acoustic, and LLM-based semantic modules for robust turn detection.
FastTurn-Cascaded provides low-latency decision-making by using streaming CTC to rapidly generate partial transcripts, which are then input to an LLM (Qwen3-0.6B) for early turn predictions. However, its heavy reliance on transcript quality limits robustness under CTC errors.
FastTurn-Semantic introduces high-level acoustic representations (via a Conformer encoder) projected into the LLM input space, allowing the LLM to perform turn reasoning grounded in both fast text (CTC) and speech-derived cues. This mitigates the impact of CTC inaccuracies in overlapping/noisy speech.
FastTurn-Unified fuses intermediate Conformer hidden states (processed by an acoustic adapter) with LLM hidden representations. The combined multi-modal features are fed into an MLP-based turn detector, enabling accurate turn-state prediction when lexical signals are insufficient and prosodic cues are paramount.
Training Strategy
The optimization process follows a four-stage curriculum to ensure stable training and optimal speech-text alignment:
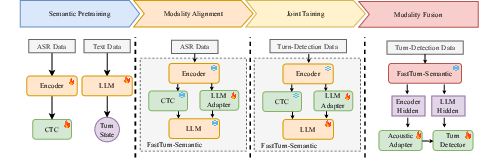
Figure 2: Training Strategy: Sequential curriculum from semantic pretraining through modality fusion for robust turn-state prediction.
- Semantic Pretraining: The Conformer encoder and CTC branch are trained on extensive ASR data. The LLM is fine-tuned to match the turn detection task, with a special turn-state token for efficiency.
- Modality Alignment: An LLM adapter is trained with the ASR objective to map acoustic encoder outputs into shared LLM space, harmonizing textual and speech semantics.
- Joint Training: The LLM and adapter are jointly optimized on both modalities. Prompt dropout is used to prevent over-reliance on CTC prompts, regularizing for better generalization.
- Modality Fusion: The acoustic adapter and turn detector are trained for integrated reasoning over both acoustic and LLM feature streams.
FastTurn Test Set
Existing turn-taking datasets lack dense, real-world annotations of conversational events (e.g., overlaps and backchannels). The FastTurn test set remediates this by combining dual-channel recordings, dense labels (speaker, emotion, pauses, etc.), and both real and synthetic samples (including rare "wait" states). This resource facilitates in-depth evaluation of turn detection models, especially under multi-party, overlapping, and noisy conditions.
Experimental Results
Turn Detection Accuracy and Latency
FastTurn was evaluated versus leading baselines (Paraformer+Ten Turn, Smart Turn, Easy Turn) across multiple test sets:
- FastTurn-Unified attains superior accuracy and lower interruption latency, especially in categories with complex conversational events (e.g., "Complete", "Backchannel").
- Semantic-only or text-dominant baselines (e.g., Paraformer+Ten Turn, FastTurn-Cascaded) manifest high miss/false alarm rates in non-ideal acoustic conditions.
- On the FastTurn test set, FastTurn-Unified outperforms Easy Turn and other semantic-acoustic models, underscoring the benefit of deep multi-modal fusion.
- Compared to Smart Turn, which achieves lowest latency but poor accuracy in real-world noisy conditions, FastTurn-Unified demonstrates a robust trade-off, retaining low latency while achieving top-tier accuracy.
ASR Decoding
- LLM-based autoregressive ASR decoding, while slightly trailing CTC in raw error rate, injects superior semantic information for downstream turn detection tasks, especially when equipped with 4-layer Transformer adapters.
- Training only the adapter (freezing other parameters) results in moderate performance, but the architecture’s flexibility facilitates highly efficient adaptation for turn detection via semantic-acoustic representation alignment.
Ablation Analysis
Progressively integrating acoustic features yields measurable improvements: FastTurn-Semantic outperforms Cascaded, and Unified further surpasses Semantic, especially under adverse acoustic conditions. This trajectory confirms the necessity of joint modeling of acoustic and semantic cues for low-latency, real-time dialogue processing.
Implications and Future Directions
The unified framework exemplified by FastTurn presents both theoretical and practical advances:
- Theory: Demonstrates that early semantic conditioning fused with direct acoustic representations can substantially elevate event detection accuracy in online dialogue, even as transcript quality fluctuates.
- Practice: Indicates the potential for deploying agentic speech interfaces in dynamically interactive, low-SNR environments with minimized response latency.
- The FastTurn test set, with rich multi-channel annotation, sets a high standard for future evaluation and paves the way for robust, generalizable benchmarking.
- Possible extensions include:
- Scaling to more diverse and multi-party conversational environments.
- Expanding language and acoustic domain coverage.
- Further reducing resource requirements for deployment on edge or embedded systems.
Conclusion
FastTurn delivers an effective, low-latency, and robust solution to real-time turn detection by unifying streaming semantic and acoustic cues. The framework’s architecture, multi-stage training, empirically validated robustness, and accompanying real-world test set create a compelling foundation for advancing practical full-duplex spoken dialogue systems (2604.01897).