- The paper introduces BBC, a cache-efficient bucket-based result collector that enhances throughput by 1.4×–3.8× for large-k ANN searches.
- It addresses heap inefficiencies and degraded quantization pruning by using specialized re-ranking algorithms for bounded and unbounded methods.
- Empirical and theoretical results confirm minimal quantization error and maintained recall, supporting scalable vector search in large datasets.
Problem Statement and Motivation
The paper "BBC: Improving Large-k Approximate Nearest Neighbor Search with a Bucket-based Result Collector" (2604.01960) addresses the efficiency challenges associated with large-k approximate nearest neighbor (ANN) search over high-dimensional vector datasets. Large-k queries (k≥5,000) arise in critical applications such as candidate recall for recommendation, large-scale rerank pipelines in retrieval-augmented generation, and dataset construction in ML model training. While ANN search is well-studied for standard (small) k (k<1000), existing systems exhibit severe throughput degradation for large k due to two dominant factors: (1) priority queue-based top-k collectors suffering from cache inefficiency as k grows, and (2) declining pruning efficiency in quantization-based ANN, leading to growing re-ranking costs.
Empirical evaluation across several methods (IVF, IVF+PQ, IVF+RaBitQ, HNSW) reveals a 4.8×--5.7k0 drop in throughput when k1 increases from 100 to 5,000 at high recall levels (see Figure 1).
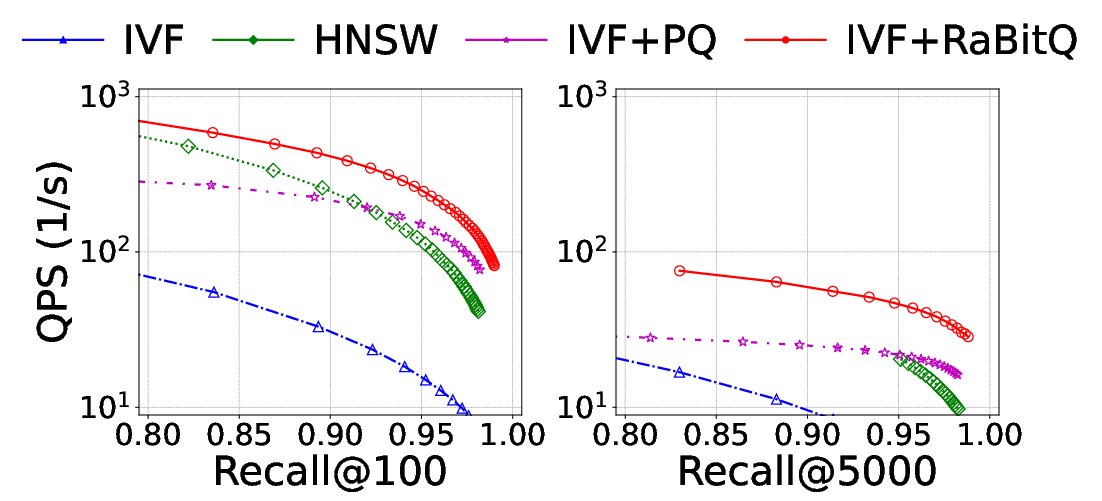
Figure 1: Querying performance of IVF, HNSW, IVF+PQ, and IVF+RaBitQ on the C4 dataset at k2 and k3.
The motivation for focusing on quantization-based methods stems from their superior resilience to elevated k4 as compared to graph-based algorithms (e.g., HNSW), whose design is inherently tuned for small-k5 retrieval via local neighborhood traversal.
Analysis of Bottlenecks
The performance bottlenecks for large-k6 ANN are twofold:
- Top-k7 Collector Inefficiency: Classic binary heap implementations for collecting the k8 nearest results incur k9 complexity per insertion and, crucially, increasingly frequent L1 cache misses when the heap (distance, id) pair array exceeds L1 capacity (k032KB). This effect is pronounced for k1, where L1 miss rates soar, and heap maintenance can dominate runtime (in IVF+RaBitQ, the share grows from 2% to 23% as k2 scales).
- Pruning Degradation: Quantization methods (bounded such as RaBitQ and unbounded such as PQ) both require expanding candidate pools as k3 grows. For bounded variants, overlap between bound intervals and threshold expands, requiring more frequent expensive re-ranking. Unbounded methods must linearly scale candidate pools relative to k4 to achieve target recall.
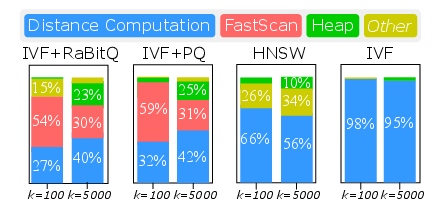
Figure 2: Time overhead breakdown at varying k5, showing increasing dominance of heap and distance computation as k6 increases.
BBC: The Bucket-based Result Collector
The paper introduces BBC—a cache-efficient, bucket-quantized result collector—designed to replace conventional heap-based top-k7 collectors in the ANN pipeline (IVF+PQ, IVF+RaBitQ). BBC comprises:
- Bucket-based Result Buffer: The candidate distance range is partitioned via one-dimensional quantization into k8 buckets, each storing candidates in linear buffers (IDs/distances). Candidates are only ordered across buckets (coarse order). Sequential insertion enables hardware prefetching and greatly reduces L1 cache miss rates. Updating the threshold bucket is amortized and localized.
- Specialized Re-ranking Algorithms: Distinct mechanisms for bounded (RaBitQ-style) and unbounded (PQ-style) quantizers:
BBC’s design is motivated by the distance concentration observed in high-dimensional settings: bucket partitioning using equal-depth quantization tightly bounds the error between the relaxed (bucket) threshold and the true threshold. Theoretical bounds demonstrate that for high k9 and moderate k≥5,0000, the quantization error is negligible.
Empirical results validate substantial gains:
- Speedup: BBC-integrated systems (IVF+PQ+BBC and IVF+RaBitQ+BBC) yield 1.4k≥5,0001–3.8k≥5,0002 throughput increases with recall@k≥5,0003=0.95, with the advantage expanding as k≥5,0004 grows, especially on large datasets (Figure 4).
- Collector Overhead: BBC reduces top-k≥5,0005 collection time by up to an order of magnitude versus heaps or sorted-buffer alternatives, halving L1 cache misses (Figure 5, Table 1).
- Re-ranking Efficiency: BBC’s greedy and early re-ranking algorithms reduce both the number of objects needing exact evaluation and per-object access cost, accelerating re-ranking by up to 1.8k≥5,0006.
- Accuracy Guarantees: Theoretical and empirical study show bucket thresholds deviate on the order of k≥5,0007 from the true value (Figure 6), preserving accuracy and strictly controlling recall loss (Figure 7).
- Small-k≥5,0008 Regime: BBC does not degrade performance for small k≥5,0009 (e.g., k0), matching or slightly outperforming heap-based approaches due to batch and prefetch advantages (Figure 8).
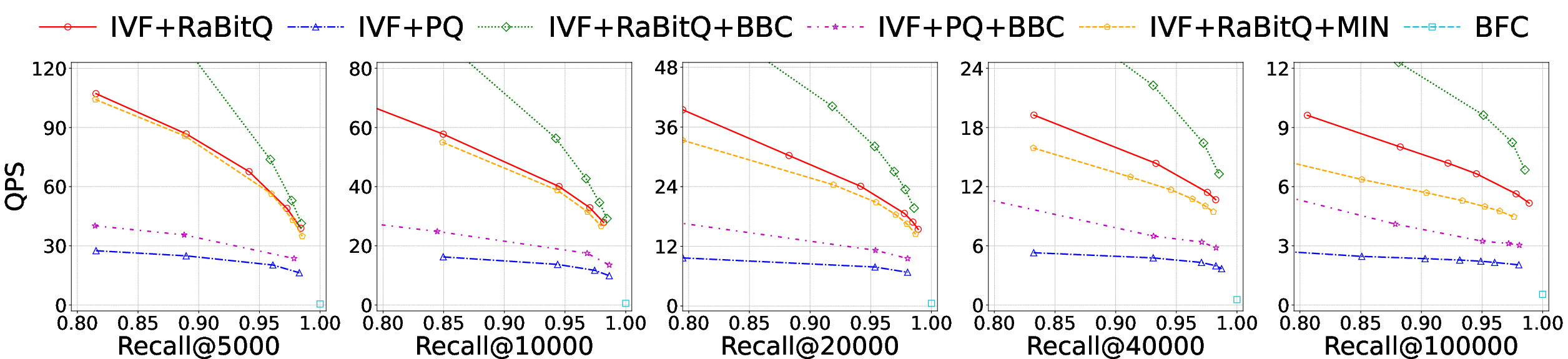



Figure 4: Accuracy-efficiency trade-off for varying k1. BBC consistently outperforms baselines, especially as k2 increases.
System Design and Implementation Choices
Selecting the number of buckets k3 is analytically tied to L1 cache capacity, quantization code footprint, and lookup table requirements. The paper provides an explicit formula balancing these constraints.
Bucket partitioning leverages equal-depth quantization via sampling over k4 to adapt to local distance distributions per query, essential for high-dimensional performance.
SIMD acceleration is exploited for code and threshold computation, further enhancing line-rate performance.
Theoretical and Practical Implications
Theoretical Implications
- BBC establishes the first formal result-collection framework explicitly optimized for large-k5 ANN, revealing the sharp interplay between memory hierarchy, quantization error, and algorithmic pipeline design.
- The results quantify a critical performance transition point in k6 where cache-aware design is mandatory, influencing the broader vector search literature on collector design.
- The separation of re-ranking logic by quantizer-type (bounded vs. unbounded) provides a template for future indexer design (particularly hybrid systems leveraging both).
Practical Implications
- BBC is compatible with all similarity metrics admitting order (Euclidean, inner-product, cosine), making it plug-and-play for prevailing quantization-based indexes and modern vector DBMSs (e.g., IVF, PQ, RaBitQ, etc.).
- The memory footprint of BBC is negligible compared to dataset scales, making it suitable for deployment in both memory- and disk-bound environments.
- Key applications include recommendation candidate generation at scale, multi-stage rerank pipelines for LLM-backed RAG, and iterative data mining over billion-scale datasets.
Future Directions
- Graph-based ANN Integration: Extending BBC’s bucketed collection strategies to graph-based ANN methods, which currently degrade dramatically on large-k7 due to unscalable heap dependence.
- GPU/Batch Processing: Adapting bucket partitioning and cache-centric logic for high-throughput GPU pipelines with warp-level collectors and multi-query batch collation.
- Algorithmic Generalization: Exploring variable-sized buckets, dynamic binning, or adaptive quantization codebook construction per query for further improvements.
Conclusion
The BBC framework, comprising a bucketed result collector and quantization-aware re-ranking strategies, resolves fundamental bottlenecks in large-k8 ANN search. Through a combination of cache model-aware data layout, quantization-driven bucket partitioning, and specialized re-ranking algorithms, BBC achieves up to 3.8k9 performance increase without recall tradeoff, maintaining or improving performance for small k<10000, and providing a formal methodology for collector design in scale-adaptive vector search infrastructure.
The approach stands as a new benchmark for scalable ANN design, with strong relevance for high-throughput AI workloads and modern vector-oriented data systems.