- The paper introduces MyEgo, a novel large-scale benchmark evaluating the ability of MLLMs to perform personalized, egocentric VideoQA.
- It details rigorous diagnostic protocols testing first-person reference resolution, temporal memory, and identity tracking in dynamic environments.
- Empirical results reveal a significant gap between human and model performance, highlighting challenges in long-term ego-grounding for real-world AI assistants.
Ego-Grounding for Personalized Question-Answering in Egocentric Videos: An Expert Analysis
Introduction and Problem Motivation
The increasing ubiquity of first-person video capture via wearable devices motivates the exploration of genuinely personalized AI assistance grounded in egocentric video understanding. "Ego-Grounding for Personalized Question-Answering in Egocentric Videos" (2604.01966) presents a methodical investigation into the capabilities and limitations of existing multimodal LLMs (MLLMs) when tasked with personalized question answering (QA) that necessitates robust ego-grounding: that is, the discernment, tracking, and temporal association of "me," "my things," "my actions," and "my history" from the camera wearer's (CW) perspective in complex, multi-agent environments.
Conventional VideoQA benchmarks and prior work in personalized VLMs lack rigorous evaluation of models’ ability to resolve first-person references over long spatial-temporal contexts with frequent distractors. This work addresses this gap by introducing a novel dataset and a comprehensive diagnostic protocol targeting such personalized, temporally extended reasoning.

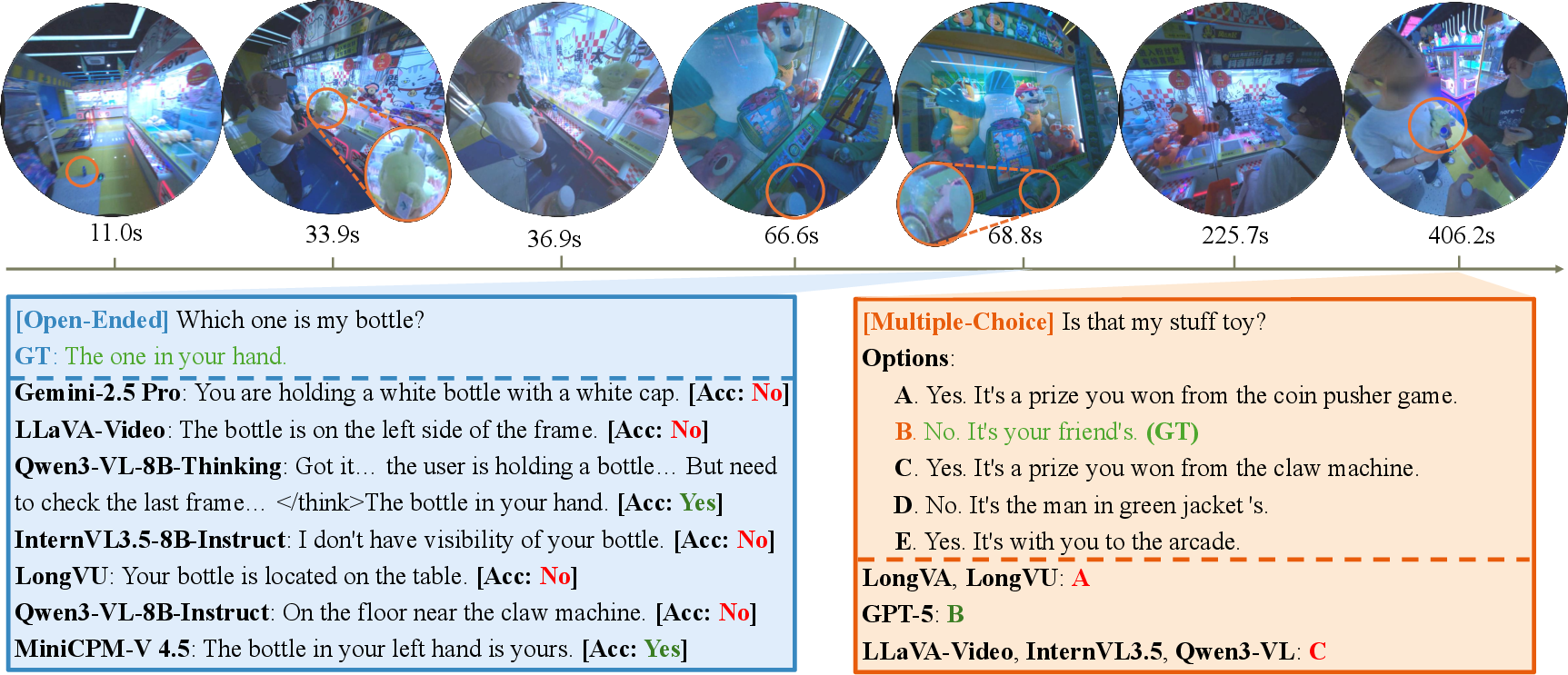
Figure 1: Example of egocentric personalized QA concerning my demands -- models are required to resolve highly contextual queries about the camera wearer's objects and actions.
The MyEgo Benchmark
MyEgo is proposed as the first large-scale, diagnostic dataset for egocentric personalized VideoQA with explicit emphasis on ego-grounding. It contains 541 long-form videos (mean 9.2 minutes) collected from Ego4D, EgoLife, and CASTEL2024, curated to ensure diverse scenarios, multi-person interactions, and numerous visually confounding distractors.
The core QA tasks are constructed by posing over 5,000 manually annotated, first-person-perspective questions at various timestamps, each demanding models to resolve the referent of “I,” “my object,” or “my past,” often in the presence of similar actors/objects and significant history/context dependencies. Approximately 60% of the questions focus on object-level references, 30% on actions, and 10% on other aspects, with an average temporal offset of ~20 seconds between question and answer moments.
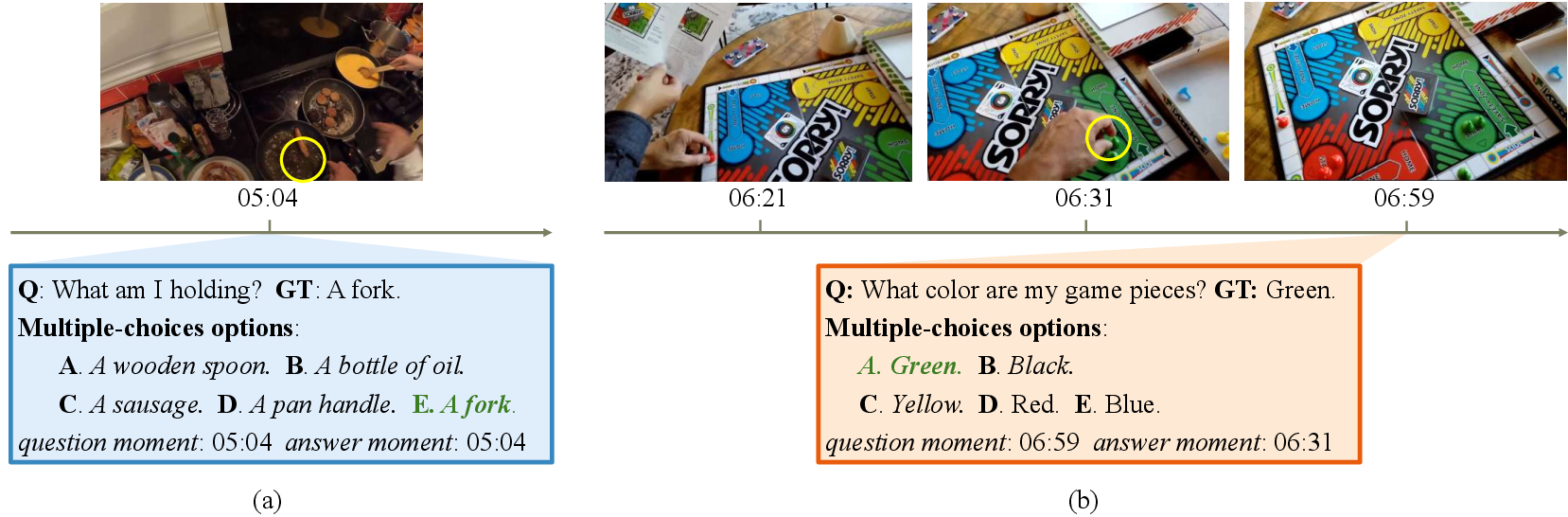
Figure 2: Model must determine which objects or hands belong to the camera wearer and track their identity among visually similar distractors across time.
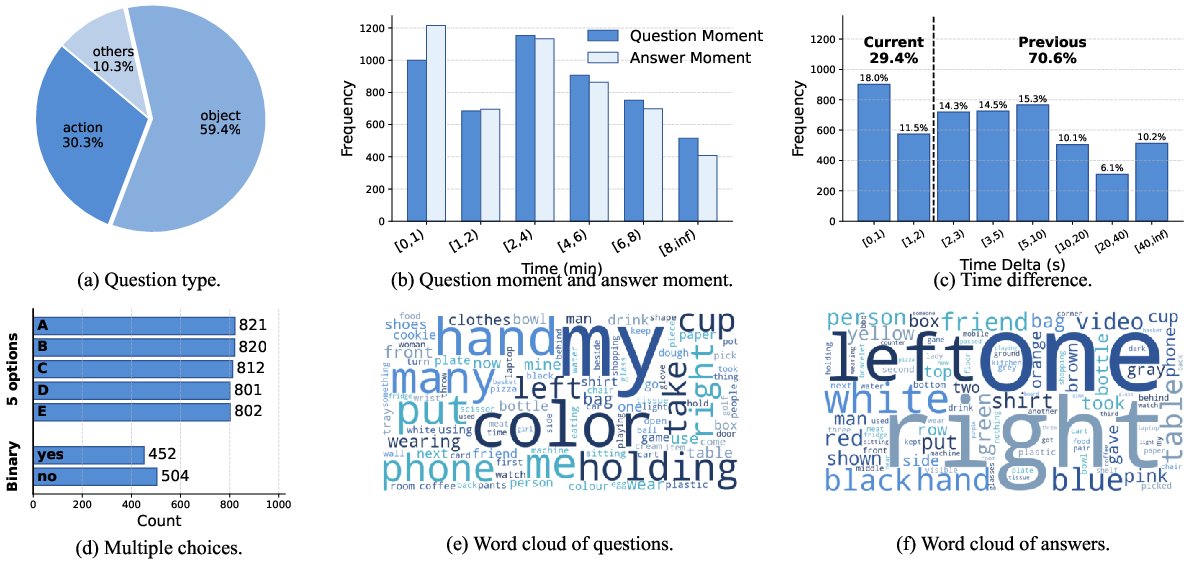
Figure 3: Statistical analysis of the MyEgo benchmark, showing the distribution of question types, answer locality, and the prevalence of ego-grounding demands.
MyEgo supports both open-ended QA and challenging multiple-choice QA (including MC-2 and MC-5 variants), with well-crafted distractors that preclude answer shortcuts and force models to faithfully perform ego-grounding.
Comparison to Prior Datasets
Unlike datasets such as EgoSchema, EgoThink, or EgoMemoria, which primarily emphasize generic video understanding in the first-person, MyEgo uniquely benchmarks models on core personalized reasoning abilities—specifically, discriminating the CW and their belongings/activities in the presence of confounding evidence from other people and objects in the environment.
Systematic Evaluation of MLLMs
Experimental Protocol
A comprehensive evaluation is conducted across a diverse spectrum of open-source and proprietary MLLMs, including state-of-the-art systems such as GPT-5, Qwen3-VL, InternVL3.5, Gemini-2.5 Pro, and memory-augmented streaming models (e.g., LongVA, LongVU, Flash-VStream, Dispider). The evaluation procedure involves both automatic and human grading, with careful attention to first-person prompting, input sampling (uniform and key-moment extraction), and assessments under varying context window sizes and parameter counts.
Key Findings
Strong empirical results are highlighted by:
Failure Modes and Analysis
In-depth error analysis uncovers systematic deficiencies:
- Accuracy decay: With uniform frame sampling, accuracy declines markedly as the temporal span between question and answer increases.
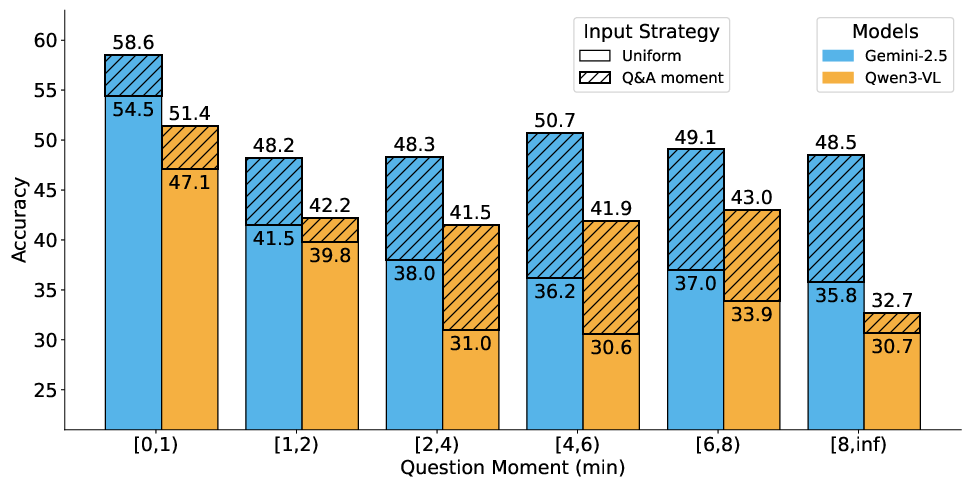
Figure 6: When key ground-truth (GT) moments are not provided, accuracy decays as temporal distance increases. Inputting GT evidence helps stabilize performance.
- Moment-aware sampling: Selectively inputting frames at the annotated question and answer moments (Q&A sampling) robustly increases accuracy (gains up to 11% on "Previous" questions), but does not close the human-model gap.
- Frame number: Increasing the number of input frames does not systematically help; more frames may introduce noise, diminishing the signal from sparse ego-centric cues.
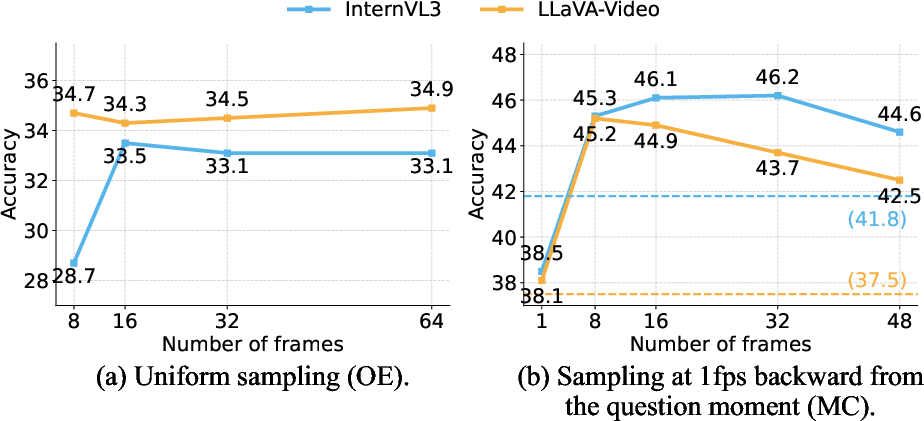
Figure 7: Increasing the number of frames yields diminishing returns—performance plateaus or decreases after a small context window.
Prompt Sensitivity
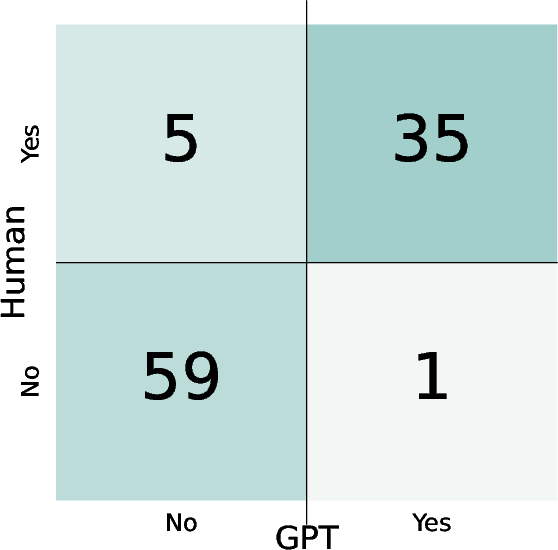
Agreement with Human Evaluation
Theoretical and Practical Implications
The empirical findings demonstrate that, despite advances in video-level visual-language modeling and scaling, current MLLMs lack (i) robust long-term memory and (ii) coherent, persistent personal identity tracking over time. Improvements from recent architectural modifications (e.g., memory augmentation, temporal attention) are secondary compared to the need for fundamentally richer ego-centric representations.
The inability of MLLMs to resolve "I" and "my things" reliably, particularly in long-term, multi-agent, or visually ambiguous contexts, undermines their applicability to genuinely personalized assistants for lifelogging, daily activity QA, or in-situ embodied reasoning. Achieving human-like performance will necessitate breakthroughs in egocentric association, persistent object/action tracking, and long-range, dynamic context modeling.
Directions for Future Research
The analysis signals immediate priorities for future work:
- Dedicated ego-grounding modules: Identity and object anchoring architectures resilient to distractors and minimal ego-appearance cues.
- Efficient long-term memory: Mechanisms (retrieval-augmented, cache-based, externalized memory) for scalable storage and lookup of temporally distant, personalized events.
- Integrated contextual world models: Hybrid symbolic-neural methods for explicit modeling of user trajectory, intent, and object interactions.
- Enhanced data and negative sampling: Further curation of adversarial context, ambiguous referents, and fine-grained activity-entity annotation to push model generalization beyond direct evidence retrieval.
Conclusion
This work constitutes the first rigorous, quantitative, and diagnostic study of ego-grounding in personalized VideoQA. The MyEgo benchmark, task formulation, and in-depth analysis expose the critical limitations of state-of-the-art MLLMs in personalized, egocentric reasoning and highlight open challenges central to the development of practical AI assistants. Addressing these gaps will be necessary for the deployment of robust, context-aware systems capable of real-world, on-body multimodal reasoning and memory over extended personal experiences.