- The paper establishes a rigorous mathematical framework for deep transformer dynamics, showing how multi-head self-attention leads to drift-diffusion limits.
- It derives explicit scaling regimes where token evolution transitions from deterministic ODE behavior to stochastic SDE dynamics under varying residual and head counts.
- The analysis quantifies representation collapse and clustering phenomena, providing actionable guidelines to balance architecture parameters to avoid oversmoothing.
Introduction and Overview
"Homogenized Transformers" (2604.01978) develops a rigorous mathematical framework to describe the depth-wise dynamics of deep transformer architectures with i.i.d. random weights, focusing explicitly on the multi-head self-attention mechanism. The central aim is to characterize the limiting behavior as depth, width, head count, and residual scaling jointly become large, producing nontrivial and analytically tractable drift-diffusion dynamics on the unit sphere. This limit regime is leveraged to investigate phenomena such as representation collapse—where token representations become degenerate as depth increases—and to identify quantitative scaling laws governing the interplay among model dimension, residual scale, and number of heads.
The work advances and generalizes previous approaches by considering stochastic heterogeneity not only across layers but also across heads, in contrast to earlier models with tied weights or simpler decoupling assumptions.
The analysis starts from a random multi-head, attention-only transformer model, where key, query, and value matrices are independently resampled across both heads and layers. At each layer, the token embeddings lie on the unit sphere and propagate via the composition of self-attention, residual addition, and spherical normalization. This can be naturally interpreted as a discrete interacting particle system with random vector fields.
By analyzing the residual update with step size η and H heads per layer, the token update is decomposed into a deterministic drift (mean-field averaged attention) and a stochastic fluctuation term due to random weights, both projected onto the tangent of the unit sphere. The key technical insight is the identification of joint scale limits (in L—depth, η, H) yielding either ODE or SDE limiting flows for the particle system, depending on the relative scaling.
Phase Diagram of Scaling Regimes
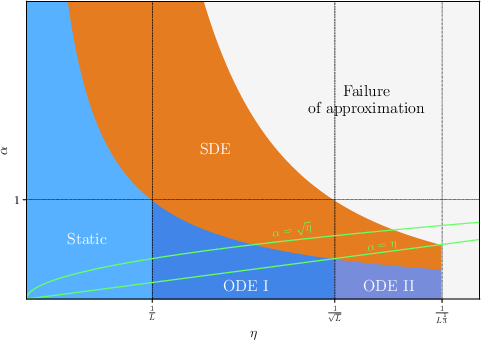
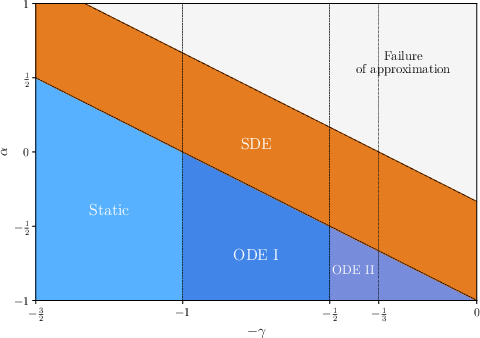
Figure 1: Qualitative phase diagrams in the (η,α)-plane for fixed depth L, contrasting regimes in linear and logarithmic coordinates, and demarcating phases of deterministic (ODE) versus stochastic (SDE) evolution.
The limiting behavior is partitioned by the parameter α=ησ2/H, where σ2 captures variance across attention heads. The relevant macroscopic time tL=ηL accumulates the impact of drift and noise over depth:
- Ballistic regime (H0): Drift dominates; noise vanishes, yielding a deterministic ODE.
- Diffusive regime (H1): Drift and noise are of comparable order, producing a limiting SDE on the sphere.
- Super-diffusive regime (H2): Noise dominates, leading to highly stochastic limiting behavior.
This phase diagram (Figure 1) delineates rigorous mathematical regimes where discrete-depth updates are approximated by continuous-time limiting flows.
The Homogenized SDE and Mean-Field Limit
Under the diffusive scaling regime, the discrete token evolution converges (in the weak sense) to a system of Itô SDEs on the sphere, jointly driven by a common cylindrical Brownian noise modulated by the empirical law of the tokens. The limiting process for H3 tokens H4, H5, takes the form:
H6
with an additional Itô correction from the spherical projection. Here, H7 denotes the empirical distribution of the H8. For large-H9 (mean-field) limits, the empirical law itself satisfies a nonlinear stochastic Fokker–Planck SPDE with common noise.
The paper establishes convergence rates for functionals of the interpolated process uniform in time, with bounds scaling as L0 under high-moment assumptions on the weight distributions.
Representation Collapse and Cluster Dynamics
A primary application of this formalism is the characterization of representation collapse—parametric regimes where token embeddings become highly aligned and clustered, pathologically reducing expressiveness with depth. The analysis is made explicit in the case of Gaussian-initialized weights with vanishing drift, allowing for tractable evaluation of overlap and rank statistics.
Simplex-Structured Initial Data: Explicit Dynamics
For simplex-initialized tokens (all off-diagonal Gram matrix entries equal), the limiting behavior reduces to a scalar ODE
L1
where L2 is a quantifiable function depending on context length, temperature parameter L3, and the simplex parameter L4. This yields explicit, dimension-dependent predictions for the speed and form of cluster formation in the limit.
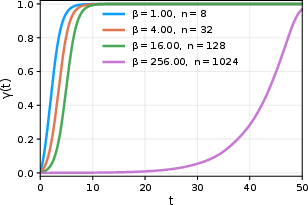
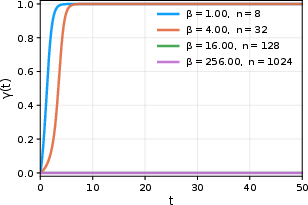
Figure 2: Left: Limiting trajectory of the overlap parameter L5 as predicted by the simplex ODE. Right: Comparison with deterministic clustering dynamics for tied weights.
Notably, the results demonstrate that even with total randomness across layers and heads—significantly more chaotic than weight-tied models—the concentration of overlaps and representation collapse persists under the proper scaling limits.
High-Temperature, High-Dimensional Regime
In the high-temperature (L6), high-dimensional (L7) regime, the mean overlap L8 satisfies a logistic ODE, L9, with explicit rates of convergence and dimension-dependent fluctuation bounds.
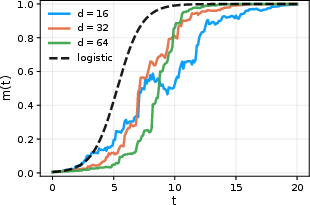
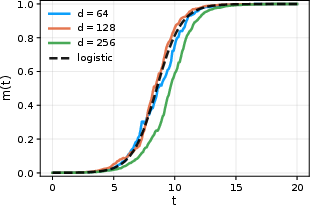
Figure 3: The mean overlap η0 converges to the logistic equation prediction in the large-η1, small-η2 regime.
For large depth and large context, in the mean-field limit with strong attention (η3), the overlap process exhibits slow motion along metastable manifolds: on the appropriate time scale, the overlaps execute stochastic motion driven by common noise, with macroscopic transitions between cluster states only occuring over exceedingly long depths.
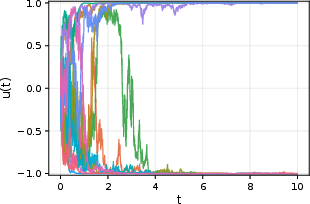
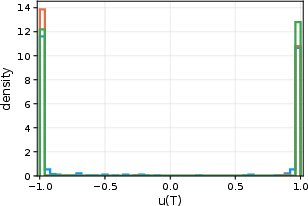
Figure 4: Sample paths of the limiting SDE (logistic form) describing the slow, noise-driven evolution of overlaps in the strong attention, high-dimensional mean-field limit.
Mathematical Contributions and Error Bounds
The central technical contributions include:
- A rigorous homogenization theorem (Theorem 1) with explicit weak error bounds, matching the discrete generator to the limiting stochastic flow in the tangent bundle of the sphere.
- Identification and proof of joint scaling regimes, including precise characterizations of Itô corrections and the common noise structure, leveraging results for infinite-dimensional SDE/ SPDEs.
- Explicit calculations for overlap, drift, and noise structure in canonical data regimes, enabling the translation of statistical physics intuition into rigorous predictions.
The error bounds are non-asymptotic and uniform in time, controlled by problem-agnostic constants (dependent on moments of the weight distributions and smoothness of test functionals), and applicable under both sub-Gaussian and explicit Gaussian initialization.
Implications and Future Perspectives
The model presented clarifies the mathematical underpinnings of the oft-observed clustering, oversmoothing, and rank collapse phenomena in deep transformers at initialization—demonstrating that these are robust features of the architecture's high-depth limit, independent of weight-tying, and persist under realistic randomization.
From a practical perspective, the scaling laws and explicit phase diagrams yield actionable guidelines on how to balance head count, residual scaling, and layer count to avoid pathological degeneration at initialization, impacting model design for very deep transformer stacks. Additionally, the identification of limiting SDE and SPDE structures aligns transformer theory with well-established frameworks in interacting particle systems, suggesting tools from stochastic dynamics, statistical mechanics, and random dynamical systems for further study.
Moving forward, this framework opens the path for:
- Systematic exploration of initializations and architectural modifications (e.g., normalization, augmentation) aimed at mitigating loss of rank and expressiveness.
- Direct quantitative comparison to empirical scaling laws and performance curves in large transformer models.
- Extensions to trained weights, task-adaptive dynamics, and other attention architectures that further decouple or enrich the evolution of drift and noise.
Conclusion
"Homogenized Transformers" establishes a comprehensive, mathematically precise limiting theory for deep transformer architectures with randomly initialized multi-head self-attention, synthesizing concepts from stochastic processes, spin glass theory, and interacting particle systems to explain and quantify key phenomena like oversmoothing and clustering. By elucidating how architectural parameters and randomness conspire to create emergent limiting dynamics, the work offers a blueprint for both theoretical investigation and principled architecture design in the regime of extreme depth and scale.