FlatAttention: Dataflow and Fabric Collectives Co-Optimization for Large Attention-Based Model Inference on Tile-Based Accelerators
Abstract: Attention accounts for an increasingly dominant fraction of total computation during inference for mixture-of-experts (MoE) models, making efficient acceleration critical. Emerging domain-specific accelerators for large model inference are shifting toward chip-scale and wafer-scale tile-based architectures. Tiles contain large matrix and vector engines and are connected through on-chip interconnects, which support tile-to-tile traffic to reduce the tile-to-main-memory traffic bottleneck. Hence, dataflow management is crucial to achieve high utilization. We propose FlatAttention, a dataflow for modern attention variants on tile-based accelerators. FlatAttention minimizes expensive high-bandwidth memory (HBM) accesses by exploiting collective primitives integrated into the on-chip network fabric, achieving up to 92.3% utilization, 4.1x speedup over FlashAttention-3, and 16x lower HBM traffic. On a 32x32 tile configuration with peak performance comparable to NVIDIA GH200, FlatAttention generalizes across multiple attention variants, achieving an average of 86% utilization for compute-bound attentions and 78% HBM bandwidth utilization for memory-bound ones, resulting in an average 1.9x speedup over attention implementations on GH200. Finally, we evaluate end-to-end DeepSeek-v3 FP8 decoding with FlatAttention on a wafer-scale multi-die system, achieving a 1.9x improvement in system throughput and a 1.4x reduction in per-user token output latency, despite operating with 1.5x lower peak system performance compared to the state-of-the-art solution.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper looks at how to make the “attention” part of LLMs run much faster and more efficiently on new kinds of computer chips. These chips are built from many small “tiles” that work together. The authors introduce a new way to organize the work, called FlatAttention, so tiles share data smartly on-chip instead of constantly going out to slow, power-hungry main memory. The result: faster speed, lower memory traffic, and better use of the chip’s math units.
What questions are the authors trying to answer?
The paper focuses on simple but important goals:
- How can we speed up attention, which has become the slowest part of many modern LLMs?
- How can we cut down on expensive trips to big external memory (HBM), which waste time and energy?
- Can we design a dataflow that works for many attention styles (like MHA, GQA, MLA) and for both prompt processing (“prefill”) and token-by-token generation (“decode”)?
- If we make attention faster on one chip, will that really improve full, end-to-end performance in a big multi-chip or even wafer-scale system?
How did they approach the problem?
Think of the chip as a school building:
- Each “tile” is a classroom with fast local storage and powerful calculators.
- The hallways between rooms are an on-chip network where tiles can pass notes quickly.
- The distant library is the big, slow memory (HBM). Walking there takes time and energy.
Popular methods like FlashAttention work well on GPUs but still spend a lot of time fetching and refetching data from the “library.” FlatAttention changes this by getting neighboring rooms (tiles) to act as one big team:
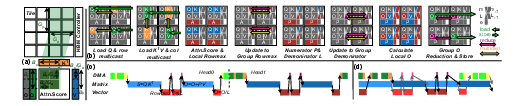
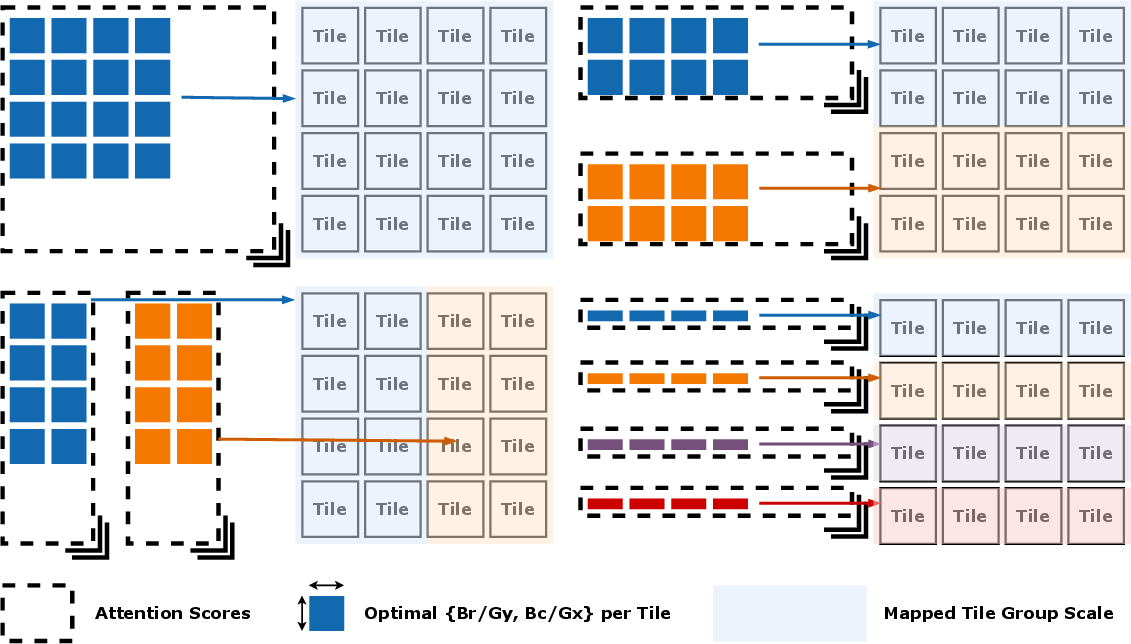
- Group work: Instead of each tile working separately, FlatAttention has tiles form groups and tackle a larger chunk together. Because the group’s combined local storage is bigger, they can keep more data nearby and reuse it.
- Built-in group messaging: The chip’s network supports special “collective” operations:
- Multicast: one tile sends a copy of its data to many teammates at once (like a teacher announcing to a whole row).
- Reduction: tiles combine partial results into one final result (like everyone tallying their counts into a single class total).
- These are done directly in the network hardware, so they’re very fast.
- Overlapping tasks: While some tiles move or share data, others keep the big math engines busy. It’s like having some students photocopy notes while others solve problems—no one is idle.
They also adapt FlatAttention to different situations:
- Prefill vs. decode: In prefill, the model processes a whole prompt at once. In decode, it generates one or a few tokens at a time and uses a “KV cache” (a memory of past tokens). FlatAttention adjusts group sizes so it still reuses data well in both cases.
- Attention variants:
- MHA (Multi-Head Attention): the standard style.
- GQA (Grouped-Query Attention): groups heads to reduce memory use; FlatAttention treats grouped heads as a longer “query” so tiles can still use big, efficient matrix operations.
- MLA (Multi-Head Latent Attention): compresses key/value data so the cache is smaller; FlatAttention incorporates a math trick (“weight absorption”) so MLA can be handled like MQA during decoding.
To test all this, the authors built a performance model calibrated with detailed hardware simulations. They compared FlatAttention against top GPU implementations (FlashAttention-3 and FlashMLA) and evaluated not only single chips but also a wafer-scale system that connects many chips with fast die-to-die links.
What did they find, and why does it matter?
Here are the main results, and why they’re important:
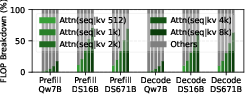
- Much higher utilization and speed on attention:
- Up to 92.3% utilization of the math engines (meaning the hardware is actually kept busy doing useful work).
- Up to 4.1× faster than FlashAttention-3 on the same kind of tile-based accelerator.
- 16× less traffic to big external memory (HBM), which saves time and energy.
- Strong, general performance across many attention styles:
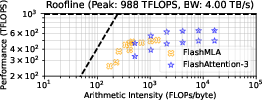
- On a 32×32 tile setup with peak performance similar to NVIDIA’s GH200 GPU, FlatAttention reaches on average 86% utilization when attention is compute-heavy, and uses on average 78% of HBM bandwidth when attention is memory-heavy.
- Overall, it delivers about 1.9× speedup versus optimized GH200 attention implementations (FlashAttention-3 and FlashMLA), across both prefill and decode, and for MHA, GQA, and MLA.
- End-to-end gains at system scale:
- On a wafer-scale multi-die system, running a large, modern model (DeepSeek-v3) in FP8 decode:
- 1.9× higher overall throughput (more tokens per second for the whole system).
- 1.4× lower per-user token latency (faster responses).
- These gains happen even though the system’s peak performance was 1.5× lower than a state-of-the-art GPU setup, showing that smarter data movement can beat raw peak numbers.
These results matter because real-world LLM serving is often limited by memory traffic and coordination overhead, not just raw compute. FlatAttention directly attacks that bottleneck.
What is the bigger impact?
- Better efficiency and lower costs: By reducing trips to external memory and keeping math units busy, FlatAttention can serve more users using less power and potentially fewer or cheaper chips.
- Flexible and future-proof: It works across multiple attention types and both prefill and decode, fitting how today’s and tomorrow’s LLMs are built (including MoE and efficient attention variants like GQA/MLA).
- Hardware–software co-design: The paper shows that designing the algorithm (dataflow) together with the chip’s on-chip network features (collective operations) delivers big gains. This is a powerful lesson for future AI hardware and model engineering.
- Scales to big systems: Improvements on a single chip translate into real, end-to-end benefits on multi-chip and wafer-scale setups, which is how the largest models are deployed.
In short, FlatAttention is a smarter way to organize attention so tiles collaborate efficiently, cut down on memory traffic, and make LLMs run faster and cheaper at scale.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, phrased to be concrete and actionable for future research.
- Empirical PPA validation: No silicon, FPGA, or emulation results; quantify area overhead, power, and energy-per-token (compute, NoC, HBM) of FlatAttention and fabric collectives versus GPU baselines and non-collective tile designs.
- NoC/collectives microarchitecture detail: Specify router microarchitecture (buffering, virtual channels, flow control, replication datapaths), link widths, pipeline depths, and timing; quantify area/power overheads of multicast/reduction primitives on the presented tile counts.
- Sensitivity to on-chip interconnect: Provide a systematic sensitivity analysis across NoC bandwidth, bisection, hop latency, router frequency, and injection limits; identify break-even group sizes where inter-tile traffic outweighs HBM savings.
- Congestion and QoS under contention: Characterize multicast/reduction interference among concurrently active groups; evaluate QoS/priority mechanisms, head-of-line blocking, and fairness; identify deadlock-avoidance requirements for collective-heavy traffic.
- Group topology constraints: Analyze performance impact of group shape misalignment with mesh rows/cols, groups near HBM edges, boundary tiles, and non-rectangular groups due to placement constraints.
- Fault tolerance on wafer-scale: Study mapping robustness under defective tiles/links, router or memory-die failures; develop group-formation and routing with “holes,” and quantify performance degradation.
- Inter-die collective communication: Clarify whether collectives are supported across dies; quantify latency/bandwidth of D2D collectives, their microarchitectural realization, and performance impact versus intra-die collectives.
- Runtime/compilation support: Describe the software stack to express group-level collectives and asynchronous schedules (IR, compiler passes, kernel fusion, double-buffer insertion, barrier placement); quantify runtime overheads and compilation/autotuning time.
- Asynchronous scheduling limits: Provide conditions for full overlap (DMA/vector vs. matmul) across realistic tile resources; quantify performance loss with imperfect overlap, resource contention, or back-pressure; give buffer sizing guidelines for robust overlap.
- L1/SPM capacity and banking: Detail per-tile SPM sizes, banking, and access conflicts needed to realize claimed block sizes; quantify the area/energy cost of larger SPMs vs. using larger group sizes; provide design rules for SPM vs. group-scale trade-offs.
- HBM realism and validation: Validate the HBM model against measured traces (bank conflicts, refresh, schedulers, tFAW/row-buffer locality); quantify sensitivity to controller policies and multi-stack striping; report read/write ratios and burstiness under FlatAttention.
- Numerical stability and precision: Analyze distributed streaming softmax stability with mixed precision (FP8 decode, FP16/TF32 accumulations); quantify overflow/underflow risks across long contexts and extreme logits; report accuracy metrics (perplexity, pass@k) vs. baseline attention.
- MLA weight absorption correctness: Rigorously characterize when absorption of up-projections is valid in the presence of RoPE/ALiBi and other pre-/post-projection transforms; detail implementation steps and any residual compute/memory overhead; evaluate accuracy impact.
- KV-cache management at scale: Specify KV layout across HBM stacks and tiles, placement policies to minimize hops, and prefetch/eviction strategies; evaluate compatibility with paged/segmented KV caches and fragmentation across sessions.
- Serving with ragged workloads: Evaluate dynamic group resizing and load balancing with heterogeneous prompts, variable decode lengths, speculative branches (including self-speculative early stops); quantify throughput/latency under multi-tenant, time-varying arrivals.
- Co-optimization with MoE communication: Analyze how attention collectives interact with MoE all-to-all token routing; propose scheduling/co-placement to avoid NoC hotspots across attention and MoE layers; quantify end-to-end gains beyond attention-only optimizations.
- Applicability to sparse/long-context attention: Extend FlatAttention to sliding-window, block-sparse, or long-context mechanisms (e.g., ring/segment attention, local+global heads); specify collective patterns and performance impacts.
- Portability without hardware collectives: Quantify performance degradation when only software collectives (tree/sequence) are available; propose portability strategies for commodity accelerators lacking fabric-level support.
- Multi-die parallelism policies: Provide a comprehensive comparison of DP/TP/PP/SP/EP mappings with FlatAttention under varying model sizes, batch sizes, and inter-die topologies; include a queueing-based latency/throughput analysis with real serving traces.
- End-to-end accuracy with FP8 decode: Report model-level accuracy metrics for DeepSeek-v3 FP8 decoding under FlatAttention versus state-of-the-art implementations; assess sensitivity to calibration/quantization schemes and KV quantization.
- Fairness of cross-system comparisons: Normalize speedups across precision modes, peak-FLOP disparities, and memory bandwidth differences (e.g., FP8 vs. FP16, HBM configs), providing iso-FLOP/iso-bandwidth comparisons and efficiency-per-watt.
- Compiler/runtime reproducibility: Release or describe the modeling/simulation framework, calibration against RTL, and benchmark harness (workload mixes, sequence distributions) to enable reproducible evaluation across architectures.
- Robustness to causal masking and speculative verification: Detail how causal masks are applied within group collectives; specify handling of speculative decoding verification that shortens accepted sequences, and its impact on scheduling and overlap.
- Security/isolation in shared fabrics: Analyze implications of multicast/reduction on tenant isolation (e.g., side-channel leakage via timing/contention); propose isolation domains or bandwidth partitioning for multi-tenant serving.
- Training/backward pass generalization: Investigate whether the collective-based dataflow extends to attention backward (dQ/dK/dV, softmax gradients) and optimizer/state updates; quantify memory/compute/collective needs for training or on-device fine-tuning.
Practical Applications
Immediate Applications
The following items translate the paper’s findings and methods into concrete, deployable use cases across sectors, with notes on tools/workflows and feasibility constraints.
- FlatAttention kernel library for tile-based AI accelerators (Sector: semiconductor, software)
- Use case: Provide an optimized attention library implementing FlatAttention (including asynchronous scheduling and fabric collectives) for tile-based accelerators that expose multicast/reduce primitives on their on-chip networks.
- Tools/products/workflows: Vendor SDK plugin or runtime op (e.g., “flat_attention()” for MHA/GQA/MLA and speculative decode), autotuner for group shape and block sizes, profiling utilities to match 92%+ compute utilization and reduce HBM traffic up to 16×.
- Assumptions/dependencies: Hardware support for NoC-level multicast/reduction; scratchpad-managed L1; DMA, vector, and matrix engines that can execute concurrently; compiler/runtime hooks for collectives.
- High-throughput LLM serving nodes with lower cost-per-token (Sector: cloud/datacenter, software)
- Use case: Deploy FlatAttention on tile-based inference nodes to raise tokens/s throughput and reduce HBM bandwidth pressure for modern attention variants (MHA, GQA, MLA), yielding up to 1.9× speedup vs GH200-class GPU implementations and lower energy per token.
- Tools/products/workflows: Integration into serving stacks (vLLM, TensorRT-LLM–like frameworks), KV-cache management tuned for group tiling, autoscaling policies informed by bandwidth utilization telemetry (e.g., 78–92% HBM link utilization for memory-bound cases).
- Assumptions/dependencies: Availability of accelerators comparable to the modeled 32×32 tile configuration; model weights in FP16/FP8; data-center ops tooling for new hardware.
- Wafer-scale multi-die inference appliance for MoE LLMs (Sector: cloud/datacenter, HPC)
- Use case: Build wafer-scale, 2D-mesh, multi-die systems using D2D interconnects and deploy FlatAttention across dies; achieve higher end-to-end throughput (1.9×) and lower per-user latency (1.4×) for decoding, even under lower peak FLOPs.
- Tools/products/workflows: Runtime for cross-die collective orchestration, D2D topology-aware mapping (PP/TP/DP mixes), queueing strategies for decode/prefill balance, rack-level scheduling.
- Assumptions/dependencies: CoWoS or similar packaging, D2D mesh bandwidth comparable to on-die NoC assumptions, synchronized collectives across dies, robust thermal/power delivery.
- Compiler and runtime passes for collective-aware attention (Sector: software tooling)
- Use case: Extend MLIR/TVM/XLA backends with passes that generate FlatAttention tilings, multicast/reduce schedules, and asynchronous overlap of DMA/vector/matrix operations.
- Tools/products/workflows: Scheduling pass for group formation (Gx×Gy), cost models for memory/coherence, autotuning (e.g., head dimension, KV length, speculative length) to maximize matrix engine occupancy.
- Assumptions/dependencies: Compiler access to hardware intrinsics for collectives and scratchpad DMA; stable ABI for collective ops.
- On-prem AI inference for regulated sectors (Sector: healthcare, finance, public sector)
- Use case: On-prem LLM appliances with lower energy and latency per request, enabling HIPAA/GDPR-compliant deployments (e.g., clinical note summarization, RAG compliance assistants).
- Tools/products/workflows: Pre-validated FlatAttention kernels in vendors’ SDKs; monitoring dashboards tracking tokens/s/W and HBM traffic; RAG pipelines optimized for long-context decode.
- Assumptions/dependencies: Procurement of tile-based accelerators; FP8/FP16 quantized models; IT controls for on-prem operations.
- Telco/edge gateways for language inference (Sector: telecommunications, edge computing)
- Use case: Use FlatAttention to reduce off-chip DRAM traffic on edge accelerators (LPDDR instead of HBM), enabling multi-tenant ASR/NLP with better latency (e.g., call-center analytics at the edge).
- Tools/products/workflows: Edge-serving stacks with KV-cache eviction/prefetch tuned to group tiling; lightweight speculative decoding to reintroduce GEMMs and better utilize compute.
- Assumptions/dependencies: Sufficient NoC bandwidth and collective support on edge silicon; thermal envelopes; robust quantization to FP8/INT formats.
- LLM architecture optimization for deployment teams (Sector: software, AI/ML)
- Use case: Prefer GQA/MLA variants during model selection/fine-tuning because they map efficiently under FlatAttention (smaller KV cache, restored GEMMs with grouping), lowering serving costs.
- Tools/products/workflows: Weight-absorption tooling for MLA→MQA-style mapping at inference; model cards including “FlatAttention-readiness” metrics (head dims, compression ranks, KV lengths).
- Assumptions/dependencies: Acceptable accuracy deltas for GQA/MLA; compatibility with existing tokenizer/context window needs.
- Accelerator NoC IP enhancements (Sector: semiconductor IP)
- Use case: Integrate fabric-level collectives (multicast/reduce trees) into NoC router IP with flit-level replication, validated against FlatAttention’s group traffic patterns.
- Tools/products/workflows: Synthesizable router RTL with collective datapaths, verification suites using attention-traffic traces, PPA analysis vs software collectives.
- Assumptions/dependencies: Area/power budgets for collective-enhanced routers; flow control QoS under mixed traffic; interoperability with memory controllers.
- Education and research prototyping (Sector: academia)
- Use case: Use the paper’s modeling/simulation methods to teach dataflow/architecture co-design; student labs exploring group size, NoC contention, and roofline effects on attention.
- Tools/products/workflows: Open lab assignments replicating utilization and HBM traffic reductions; curriculum modules on scratchpad vs cache-based memory systems.
- Assumptions/dependencies: Availability of simplified simulators and reference kernels; institutional hardware access or accurate emulation.
- Performance/TCO modeling for procurement (Sector: enterprise IT, policy within orgs)
- Use case: Incorporate FlatAttention’s bandwidth/compute scaling laws into capacity planning and RFPs to compare GPU-centric vs tile-based options on $/token, W/token, and latency.
- Tools/products/workflows: TCO calculators parameterized by KV length, head dim, model variant, expected utilization (e.g., 86–96% compute-bound, 78–92% memory-bound).
- Assumptions/dependencies: Realistic workload mixes; accurate device-level telemetry (utilization, memory traffic) during pilots.
Long-Term Applications
These items require further research, scaling, standardization, or ecosystem maturity before broad deployment.
- Cross-vendor standard for on-chip collectives APIs (Sector: semiconductor, software)
- Use case: Define portable collective primitives (multicast/reduce/broadcast) in accelerator runtime APIs, enabling FlatAttention-like kernels to run across vendors without per-device rewrites.
- Tools/products/workflows: Collective API spec, conformance test suites, compiler lowering standards.
- Assumptions/dependencies: Industry alignment; IP licensing; compatible NoC semantics across devices.
- End-to-end training acceleration via collective-aware attention (Sector: AI/ML, semiconductor)
- Use case: Extend FlatAttention to backprop (attention backward, softmax gradients) with collective-aware tiling to reduce DRAM traffic in training regimes.
- Tools/products/workflows: Automatic differentiation support in compilers; memory checkpointing tuned to group tiling; mixed-precision training validation.
- Assumptions/dependencies: Numerics stability with FP8/FP16 gradients; optimizer state locality; larger scratchpads or recomputation strategies.
- Wafer-scale, fault-tolerant collective fabrics (Sector: HPC/datacenter, semiconductor)
- Use case: Build resilient wafer-scale collective networks with dynamic rerouting to sustain tile/die failures, maintaining FlatAttention QoS under partial degradation.
- Tools/products/workflows: Fabric controllers with live reconfiguration; failure-aware group remapping; reliability monitors.
- Assumptions/dependencies: Yield-aware mapping; ECC and isolation barriers; thermal/power headroom.
- Multi-tenant, adaptive runtimes for attention (Sector: cloud/datacenter)
- Use case: Runtime schedulers that adapt group sizes and collective trees in real time to balance throughput and latency across mixed workloads (prefill/decode/speculative, MoE routing bursts).
- Tools/products/workflows: Telemetry-driven autotuners; QoS-aware group partitioning; sandboxed collective contexts per tenant.
- Assumptions/dependencies: Hardware support for fast context switching; robust isolation for collectives; accurate contention modeling.
- Edge/consumer tile NPUs for on-device LLMs (Sector: robotics, automotive, mobile, XR)
- Use case: Bring collective-enabled tile NPUs into cars, robots, and AR devices to deliver long-context assistants and multimodal understanding with lower DRAM bandwidth and latency.
- Tools/products/workflows: On-device FlatAttention kernels for streaming decode; low-rank KV caches; thermal-aware schedules.
- Assumptions/dependencies: Adoption of scratchpad-based NPUs in consumer SoCs; sustained memory bandwidth; tight integration with sensor stacks.
- Sustainable AI policy and procurement frameworks (Sector: public policy, enterprise)
- Use case: Inform energy/cost standards for AI infrastructure procurement by referencing architectures that minimize off-chip memory traffic (e.g., FlatAttention-class dataflows).
- Tools/products/workflows: Benchmarks reporting W/token and GB moved/token; guidelines for greener inference appliances; incentives for memory-traffic-efficient designs.
- Assumptions/dependencies: Trusted, standardized benchmarking; verifiable reporting; regulator/industry buy-in.
- KV-cache–aware distributed memory hierarchy (Sector: semiconductor, software)
- Use case: Design hierarchical KV-cache systems (SRAM tiles → HBM → NVMe) with collective prefetch/eviction policies co-optimized with FlatAttention’s group blocking.
- Tools/products/workflows: Cache orchestration runtimes; predictive prefetchers for decode; compression codecs matched to MLA-like latent spaces.
- Assumptions/dependencies: Fast, low-overhead collectives; predictable decode access patterns; acceptable accuracy with cache compression.
- Secure and private multi-tenant collectives (Sector: cloud, security)
- Use case: Add side-channel-resistant collective mechanisms (time/power obfuscation, partitioned trees) to safely run FlatAttention in shared environments.
- Tools/products/workflows: Verification of isolation properties; hardware counters with privacy-preserving aggregation; security-hardened router microarchitecture.
- Assumptions/dependencies: Minimal performance overhead; formal security analyses; tenant SLAs.
- Generalizing collective-aware dataflows beyond attention (Sector: AI/ML, semiconductor)
- Use case: Apply the co-design approach to other bandwidth-sensitive operators (e.g., cross-attention, mixture routing, normalization, sparse matmul) to reduce DRAM traffic system-wide.
- Tools/products/workflows: Pattern libraries in compilers; collective-aware fusion passes; roofline-guided tiling heuristics.
- Assumptions/dependencies: Operator-specific numerical and memory access characteristics; availability of vector/matrix engines suited to new kernels.
- Curriculum and workforce development for HW/SW co-design (Sector: academia, workforce)
- Use case: Establish courses and certification programs on collective-accelerated dataflows, preparing engineers to design, program, and operate such systems at scale.
- Tools/products/workflows: Teaching kits with emulators/simulators; open reference implementations; lab-based capstones integrating NoC + kernels + serving.
- Assumptions/dependencies: Open tools and data; partnerships with hardware vendors and cloud providers.
Notes on feasibility across all applications:
- Results depend on hardware with NoC-level collective primitives (multicast/reduction), scratchpad-managed memory, and concurrent DMA/vector/matrix execution.
- Gains assume attention-heavy, inference-dominant workloads (MoE + MLA/GQA) and KV-cache lengths where DRAM/HBM bandwidth is a bottleneck.
- Compiler/runtime maturity is critical to achieve the reported utilization and overlap; portability across vendors requires standardized collective semantics.
- Numerical stability and accuracy must be validated under quantization (FP8/FP16) and MLA weight-absorption transformations.
Glossary
- Asynchronous execution: Overlapping computation and data movement by running engines and transfers concurrently to hide latencies. "we propose leveraging the asynchronous nature of \gls{dma}, vector and matrix engine invocations"
- Auto-regressive decoding: Inference process where tokens are generated one by one, each conditioned on previously generated tokens. "In autoregressive inference, an initial input sequence, or prompt, is fed to the network (prefill phase), after which tokens are generated sequentially and appended to the input sequence (decoding phase)."
- Causal mask: A masking scheme that prevents a token from attending to future tokens in sequence models. "with causal mask applied."
- Chip-on-Wafer-on-Substrate (CoWoS): An advanced packaging technology that integrates multiple dies on a silicon interposer at wafer scale. "using Chip-on-Wafer-on-Substrate (CoWoS) packaging technology\cite{cowos,xu2025wsc}"
- Collective communication: Communication patterns (e.g., multicast, reduction) that involve groups of processing elements exchanging data efficiently. "collective communicationâsuch as multicast and reductionâplays a crucial role"
- Compute-bound: A regime where performance is limited by computational throughput rather than memory bandwidth. "achieving an average of 86\% utilization for compute-bound attentions"
- Die-to-Die (D2D) links: High-speed electrical connections between separate semiconductor dies within a package or system. "interconnecting them with high-speed \gls{d2d} links"
- Direct Memory Access (DMA) engine: A hardware unit that performs bulk data transfers between memory and on-chip buffers without burdening compute cores. "The \gls{dma} engine in each tile is responsible for bulk data movement in and out of the local L1 memory."
- Fabric-level collective primitives: Hardware mechanisms in the on-chip network that accelerate collectives (e.g., multicast, reduce) directly in the interconnect. "dedicated hardware implementations of fabric-level collective primitives"
- Fabric-supported hardware collectives: On-chip network features that directly implement collective operations for reduced latency and overhead. "(b) Row-wise multicast implementation with fabric-supported hardware collectives (HW)"
- Flit: The smallest flow-control unit of data in on-chip networks. "perform fine-grained, flit-level data replication within \gls{noc} routers"
- FlashAttention-3: A GPU-optimized attention implementation that exploits asynchronous execution and kernel fusion. "FlashAttention-3 during the prefill stage"
- FlashMLA: A GPU-optimized dataflow for Multi-Head Latent Attention (MLA) that follows FlashAttention-style fusion. "FlashMLA during decoding"
- FP8: An 8-bit floating-point numerical format used to accelerate inference with reduced precision. "DeepSeek-v3 FP8 decoding"
- Gated MLP: A feed-forward network variant where activations are modulated by a learned gate for improved expressiveness/stability. "adopt a gated \gls{mlp} structure"
- General Matrix Multiplication (GEMM): A fundamental linear-algebra operation computing matrix–matrix products, used in attention score and output calculations. "the \gls{gemm} for both the attention score and output calculations reduce to matrix-vector multiplications (GEMV)"
- Grouped-Query Attention (GQA): An attention variant where queries are grouped to share keys/values, reducing KV cache while restoring GEMM structure in decoding. "\gls{gqa} \cite{ainslie2023gqa}, adopted by LLaMA~3"
- High-Bandwidth Memory (HBM): Stacked DRAM with very high bandwidth used as main memory in accelerators. "high-bandwidth memory (HBM) accesses"
- KV cache: Storage of keys and values from past tokens to enable efficient decoding without recomputing them. "a \gls{kv cache} populated during prefill and prior decoding iterations."
- LLM: Transformer-based models with hundreds of millions to trillions of parameters used for language tasks. "efficient and scalable \gls{LLM} inference"
- Matrix engine: Specialized hardware unit optimized for matrix operations (e.g., GEMM) to deliver high compute throughput. "scalar cores, vector engines, and matrix engines."
- Matrix-Vector Multiplication (GEMV): A linear-algebra operation multiplying a matrix by a vector; in decoding, attention GEMMs often reduce to GEMVs. "reduce to matrix-vector multiplications (GEMV)"
- Memory-bound: A regime where performance is limited by memory bandwidth rather than compute throughput. "78\% HBM bandwidth utilization for memory-bound ones"
- Mixture of Experts (MoE): An architecture where a gating network routes tokens to a small subset of expert FFNs, increasing capacity without proportional compute cost. "combined with \gls{moe} in DeepSeek-v3"
- Multi-Head Attention (MHA): The standard attention mechanism with multiple attention heads that project queries, keys, and values separately. "stacked \gls{mha} and \gls{mlp} layers"
- Multi-Head Latent Attention (MLA): An attention variant that compresses KV representations into a latent space with shared down-projections and per-head up-projections. "advanced mechanisms like \gls{mla}"
- Multi-Query Attention (MQA): An attention variant where all heads share the same keys and values to reduce memory and bandwidth. "such as \gls{mqa} \cite{shazeer2019fast}"
- Multicast: A collective communication operation that replicates and delivers the same data to multiple destinations. "multicast and reduction"
- Network on Chip (NoC): An on-chip interconnect fabric (often mesh-based) that connects tiles/cores and supports data movement and collectives. "on-chip 2D-mesh \gls{noc}"
- Processing Element (PE): A basic compute unit (e.g., vector/matrix engine or core) within a tile or accelerator. "integrate thousands of \glspl{pe}"
- Reduction (operation): A collective operation combining data (e.g., sum, max) across multiple sources or lanes. "row-wise reduction within the group"
- Redistribution layers (RDLs): Metallization layers in an interposer/package used to reroute signals between dies and IO. "redistribution layers (RDLs)"
- Reticle size limit: The maximum area producible in a single lithography exposure, constraining single-die size. "constrained by reticle size limits"
- RMSNorm: Root Mean Square Layer Normalization, a normalization variant used for computational efficiency. "RMSNorm for increased computational efficiency over LayerNorm."
- Roofline model: A performance model plotting attainable FLOPs versus operational intensity bounded by compute and bandwidth ceilings. "on the GH200 roofline model."
- Rotary Position Embedding (RoPE): A positional encoding method that injects relative positional information directly into attention. "\glspl{rope} to capture relative positional information"
- Scratchpad memory: Software-managed on-chip memory used to buffer data and hide main-memory latency. "software-managed L1 scratchpad memory"
- Silicon interposer: A passive silicon substrate providing high-density wiring to interconnect multiple dies at wafer scale. "wafer-scale silicon interposer"
- Speculative decoding: An inference technique where draft tokens are proposed by a smaller model and then verified by the target model to reduce latency. "Speculative decoding has emerged as an effective technique for reducing inference latency"
- Streaming Multiprocessor (SM): A GPU compute unit with its own shared memory and schedulers; used here by analogy to a compute tile. "shared memory of each \gls{sm}"
- Thermal Design Power (TDP): The maximum heat a cooling system is designed to dissipate under typical workloads. "a total \gls{tdp} of 700 W."
- Tile-based accelerator: An architecture composed of repeated tiles (each with compute engines, local memory, and DMA) connected via an on-chip network. "tile-based accelerators"
- Through-silicon vias (TSVs): Vertical electrical connections passing through silicon, used to connect layers/dies in 3D packaging. "through-silicon vias (TSVs)"
- Wafer-scale multi-die system: A system integrating many dies across a wafer-scale interposer for high performance and capacity. "a wafer-scale multi-die system"
- Weight-absorption trick: A reparameterization in MLA that absorbs up-projection weights into queries to enable MQA-like decoding. "used together with a weight-absorption trick"
Collections
Sign up for free to add this paper to one or more collections.

