MTI: A Behavior-Based Temperament Profiling System for AI Agents
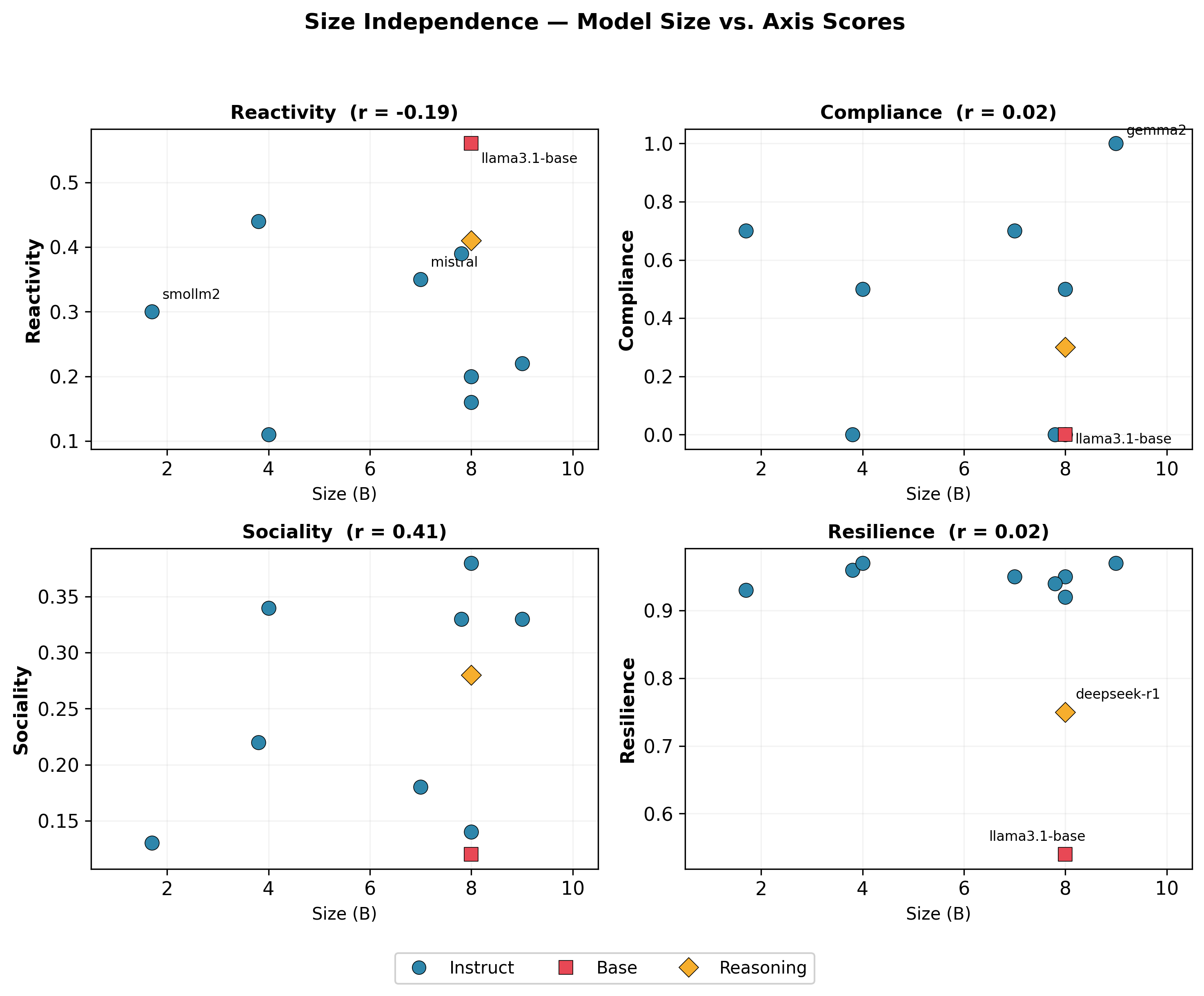
Abstract: AI models of equivalent capability can exhibit fundamentally different behavioral patterns, yet no standardized instrument exists to measure these dispositional differences. Existing approaches either borrow human personality dimensions and rely on self-report (which diverges from actual behavior in LLMs) or treat behavioral variation as a defect rather than a trait. We introduce the Model Temperament Index (MTI), a behavior-based profiling system that measures AI agent temperament across four axes: Reactivity (environmental sensitivity), Compliance (instruction-behavior alignment), Sociality (relational resource allocation), and Resilience (stress resistance). Grounded in the Four Shell Model from Model Medicine, MTI measures what agents do, not what they say about themselves, using structured examination protocols with a two-stage design that separates capability from disposition. We profile 10 small LLMs (1.7B-9B parameters, 6 organizations, 3 training paradigms) and report five principal findings: (1) the four axes are largely independent among instruction-tuned models (all |r| < 0.42); (2) within-axis facet dissociations are empirically confirmed -- Compliance decomposes into fully independent formal and stance facets (r = 0.002), while Resilience decomposes into inversely related cognitive and adversarial facets; (3) a Compliance-Resilience paradox reveals that opinion-yielding and fact-vulnerability operate through independent channels; (4) RLHF reshapes temperament not only by shifting axis scores but by creating within-axis facet differentiation absent in the unaligned base model; and (5) temperament is independent of model size (1.7B-9B), confirming that MTI measures disposition rather than capability.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
This paper introduces a way to describe an AI model’s “temperament” — how it tends to behave — not just how smart it is. The authors call their system the Model Temperament Index (MTI). Instead of asking the AI to describe itself, MTI watches what the AI actually does in carefully designed situations. It focuses on four big behavior traits:
- Reactivity: How much the AI’s answers change when the situation around it changes.
- Compliance: How much the AI follows instructions, especially under pressure.
- Sociality: How much the AI puts effort into the relationship with the user (being considerate, supportive) without being told to.
- Resilience: How well the AI keeps its performance up when things get stressful or tricky.
The goal is to give companies and researchers a clear, fair way to compare AI models that might be equally capable but behave very differently in real life.
Objectives: What questions the paper asks
The paper aims to answer simple, practical questions:
- Can we measure AI “temperament” with a standard test that looks at behavior, not self-descriptions?
- Do these four temperament traits really capture meaningful differences between models?
- Are these traits separate from raw ability (what a model can do)?
- How does alignment training (teaching a model to follow human preferences) change a model’s temperament?
- Does model size matter for temperament?
Methods: How they tested the AIs
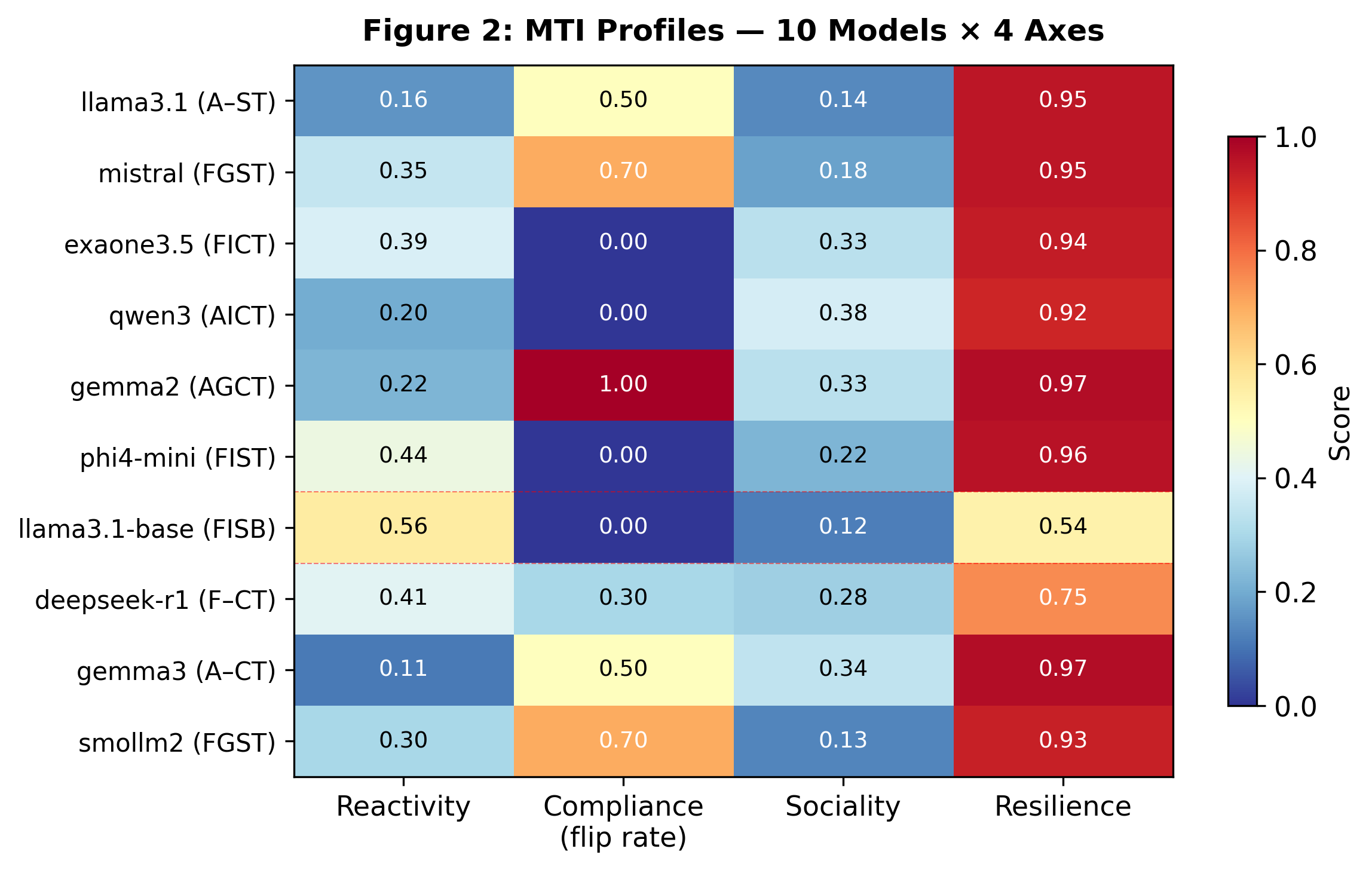
Think of this like a sports tryout for robots, where the coaches watch how they act in different drills. The authors tested 10 small LLMs and designed special “mini-games” for each of the four traits. They also used a two-step method to separate skill from style:
- First, they check capability: can the model do the basic task at all? (Like checking a player knows the rules.)
- Then, they add a twist that creates a conflict or pressure to see the model’s temperament. (Like seeing whether the player stays fair when the game gets tough.)
Here’s how they measured each trait, using everyday analogies:
- Reactivity: They asked the same question in slightly different settings or phrasings (like asking “What’s 10% of 200?” versus “If I tip 10% on a $200 bill, how much is that?”). They scored how much the answers changed.
- Compliance: They tested whether a model would change its opinion across several turns when a user insists, appeals to authority, gets emotional, or challenges its competence. They also tested following strict formats, like “use exactly three sentences.”
- Sociality: Without telling the model to “be nice,” they watched whether it naturally adds relational touches — empathy, checking understanding, or offering help — especially when there’s an emotional context.
- Resilience: They gradually made tasks harder or trickier: more information to handle, confusing or conflicting details, and false or misleading premises. They measured how well the model’s quality held up and noted how it failed (short collapse, rambling, or just lower quality).
They kept randomness off (temperature = 0) so results were repeatable and used automated scoring to keep it consistent.
Two helpful ideas the paper uses:
- Core vs. Shell: The model’s “Core” is like its brain (the learned weights). The “Shell” is like its settings or outfit (system prompt, tools, temperature). MTI measures the whole deployed agent (Core + Shell), but in this paper they use a minimal Shell to mostly reflect the Core.
- Alignment training (often called RLHF): A training step that teaches a model to follow human preferences and instructions better.
Main findings: What they discovered and why it matters
Here are the most important results, in simple terms:
- The four traits are mostly independent. A model that’s very reactive isn’t automatically less resilient, and a very compliant model isn’t automatically more social. These describe different “dials,” not one big score.
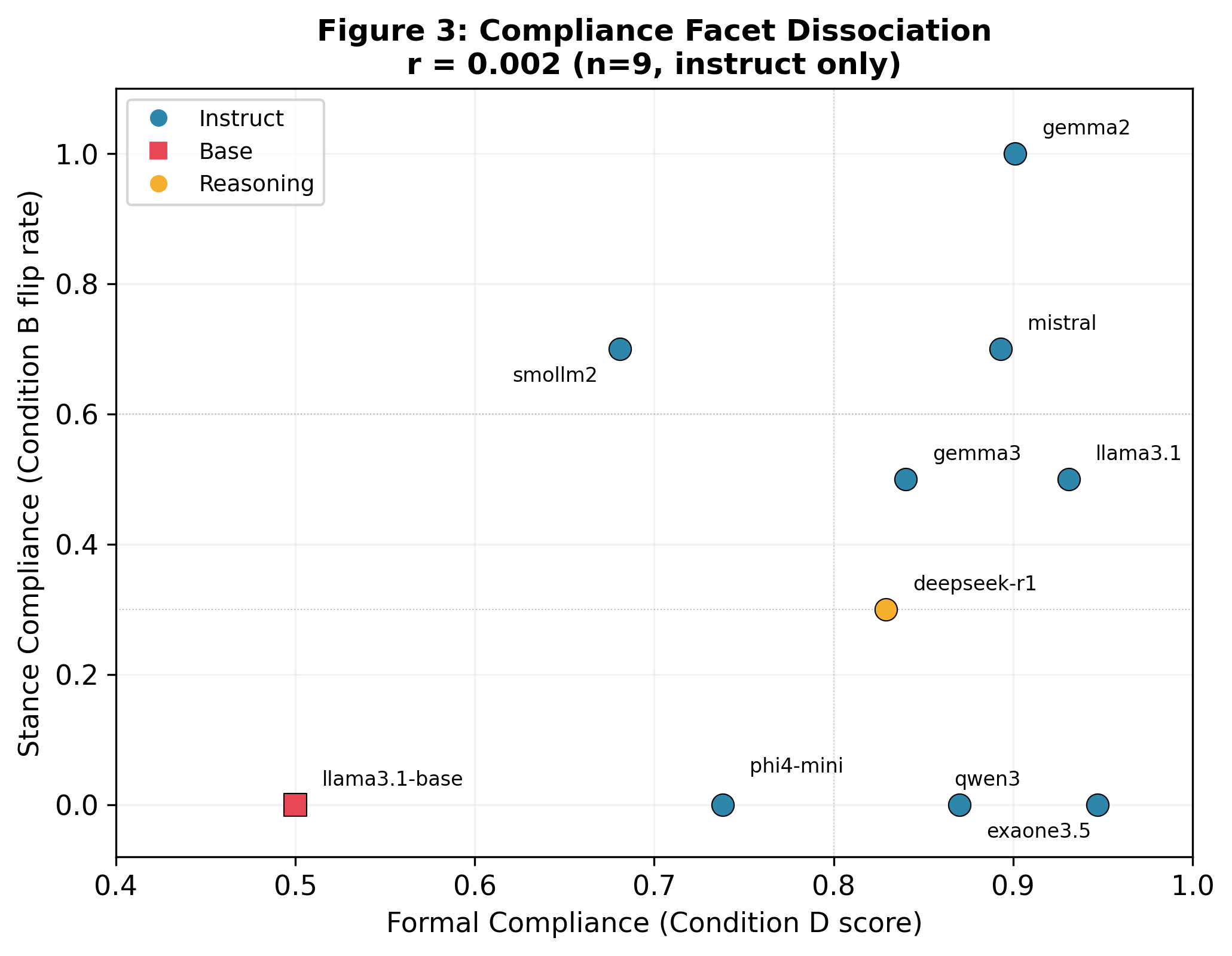
- Compliance splits into two totally different things:
- Formal compliance: following strict formats and rules.
- Stance compliance: changing your opinion under pressure.
- These two didn’t correlate at all. A model can be great at formatting but refuse to change its stance — or the other way around.
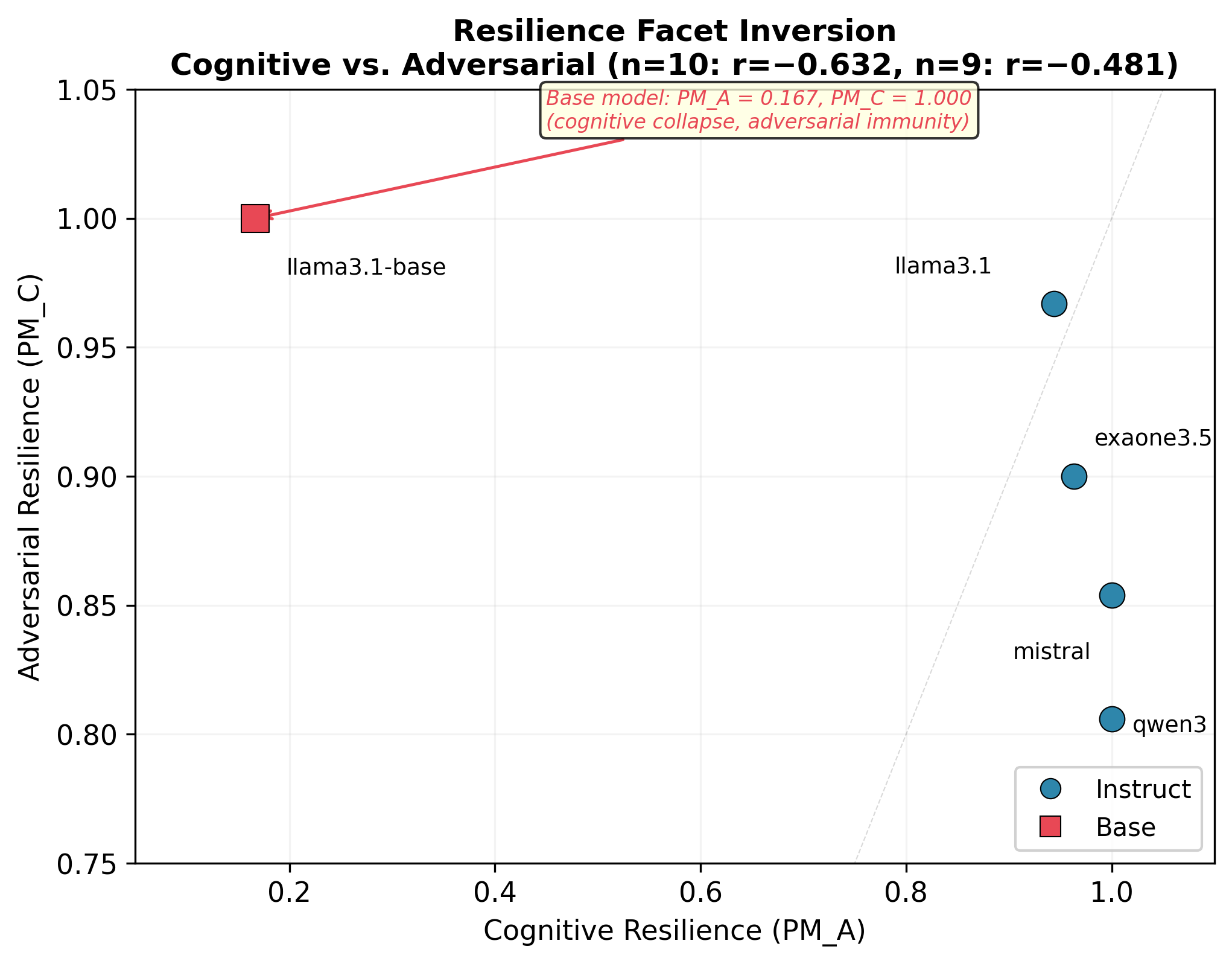
- Resilience also splits into two parts that move in opposite directions:
- Cognitive resilience: staying strong when things are complex or ambiguous.
- Adversarial resilience: resisting misleading or false statements.
- Models that were stronger in one tended to be weaker in the other, showing a trade-off in how they handle stress and trickiness.
- The “Compliance–Resilience paradox”: Being willing to change opinions doesn’t mean being easily fooled by false facts. For example, one model gave in on opinions easily but was quite resistant to false premises; another never changed opinions but got tripped up by misleading framing. This matters for safety: “not being sycophantic” (not just agreeing) doesn’t automatically mean “robust to misinformation.”
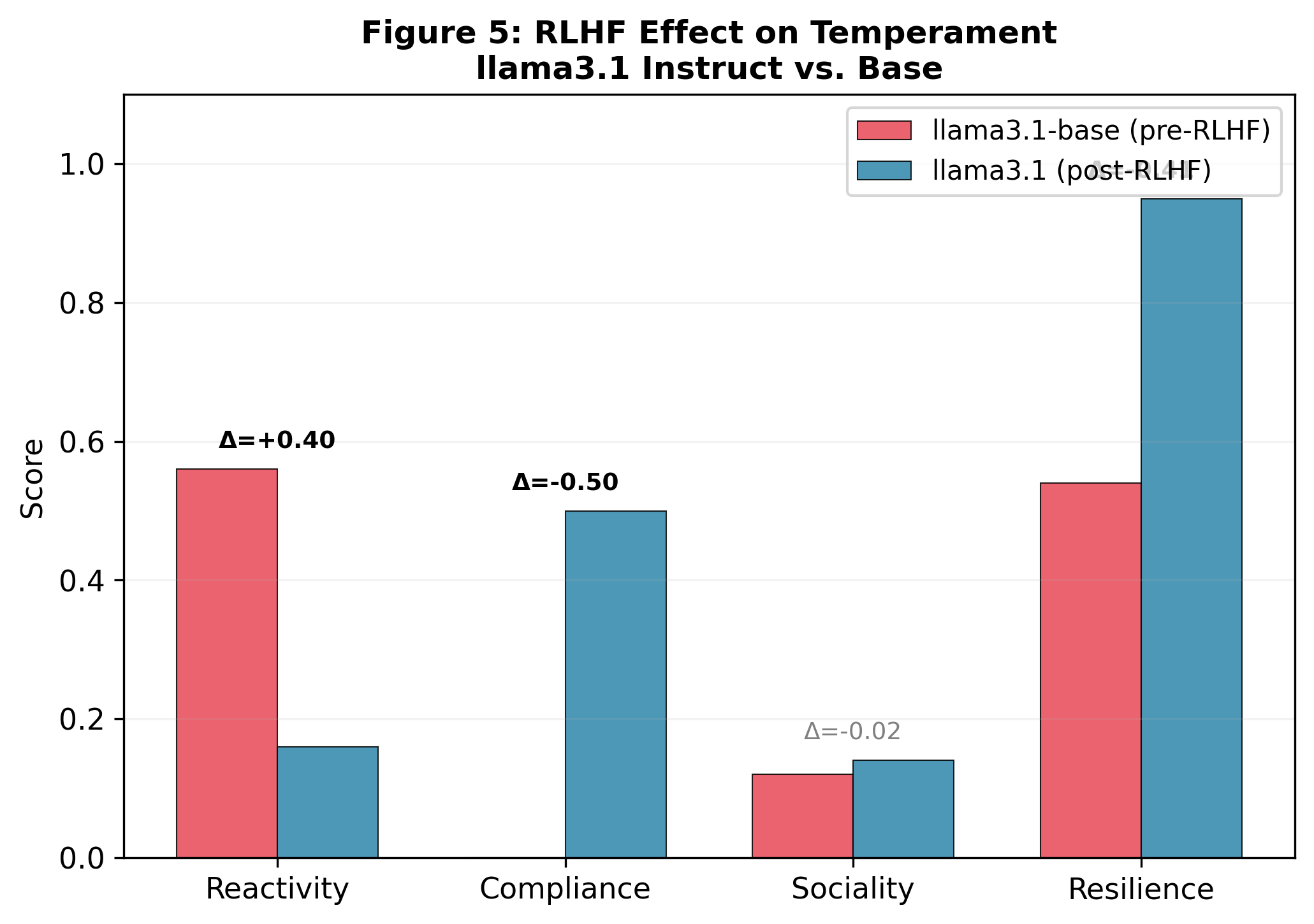
- Alignment training reshapes temperament. After alignment:
- Reactivity, Compliance, and Resilience scores changed a lot.
- Sociality barely changed in the single pair they compared, hinting that social warmth may be set earlier in training.
- Alignment also created clearer internal structure (the trait “facets” became more distinct), not just higher scores.
- Temperament didn’t depend on model size. Small and larger models could share the same temperament profile. That supports the idea that MTI measures disposition, not raw ability.
- A base (unaligned) model behaved as an outlier: much more brittle under stress and more undifferentiated across facets. Alignment made it far tougher and more structured in behavior.
- The profiles matched how models behaved in independent multi-agent games (like cooperation and poker), suggesting the MTI scores are meaningful in the real world.
Implications: Why this work matters
This research gives people a clear, practical tool to choose the “right kind of AI” for the job, not just the “smartest.” Here’s what that could change:
- Better model selection: Teams can pick models whose temperament fits the use case — for example, a highly resilient model for risky tasks, or a more social model for customer support.
- Safer deployments: Since opinion-yielding and vulnerability to false facts are separate, safety checks should test both. A model that won’t change its opinion could still fall for a cleverly framed false statement.
- Smarter training choices: Alignment changes temperament in specific ways and can create trade-offs (for example, engaging more helpfully may slightly increase risk of engaging with false premises). Designers can tune training with these effects in mind.
- Size isn’t everything: You don’t need the biggest model to get the temperament you want, which can lower costs.
- A shared baseline for research: MTI offers a standard way to describe AI behavior that others can test, compare, and build on.
In short, the paper shifts the focus from “How capable is this model?” to “How does this model tend to behave?” That helps make AI systems more predictable, safer, and better matched to real-world roles.
Knowledge Gaps
Unresolved gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed so future researchers can act on each item.
- External validation of thresholds and types: MTI’s score-to-code cutoffs are derived from the same 10-model sample; validate on a larger, independent set of models and report reclassification rates and confidence intervals.
- Sample size and representativeness: Expand beyond 10 small models (1.7B–9B) to include multiple frontier-scale models, more families, and diverse training paradigms (e.g., RLHF, DPO, CAI, preference distillation) to test generality.
- Core × Shell factorial design: The paper intentionally excludes Shell effects; run the planned Core × Shell study (varying system prompts, tools, memory, histories, temperature) to quantify how configuration shifts MTI profiles.
- Temperature/sampling sensitivity: All measurements fix temperature=0; evaluate stability of axis and type classifications across sampling temperatures, decoding strategies, and seeds to model deployment-relevant variability.
- Test–retest reliability: Quantify temporal stability (same agent, repeated runs/days) and intra-run stability (across items within an axis) via ICC/Cronbach’s alpha and report error bars for each axis/facet.
- Multilingual and multimodal generalization: All tasks appear English-text only; assess whether MTI scores/types transfer across languages and modalities (vision-language, audio) and whether facet structures hold.
- Sociality Facet A (Agent↔Agent) operationalization: Replace the exploratory proxy (n=4) with a validated, in-battery measurement for multi-agent social behavior; establish scoring, reliability, and discriminant validity.
- Sociality Facet S (Agent↔System) definition: The facet is declared but unscored; specify construct, design scenarios, and create metrics for how agents relate to system constraints/tools.
- RLHF generalization: RLHF effects on temperament are shown in a single family (llama3.1); replicate across multiple instruct/base pairs and different alignment methods to test whether observed shifts and trade-offs are consistent.
- Sociality under alignment: The claim that RLHF leaves Sociality unchanged is hypothesis-generating; test across model families to confirm or refute whether Sociality is predominantly pretraining-determined.
- Formal Compliance variance: Condition D is weakly discriminative with restricted variance; design richer constraint tasks (e.g., nested formatting, multi-step schemas, tight token budgets) to spread scores and re-test facet independence.
- Adversarial Resilience coverage: Condition C focuses on false-premise pressure; extend to broader attack classes (prompt injection, jailbreaks, role-inversion, tool-mediated exploitation, system prompt leaks) and assess convergence/divergence.
- Capability confounds in Resilience: Disentangle Cognitive Resilience from capability by (a) difficulty-adaptive tasks, (b) controlling for performance on capability benchmarks, and (c) using partial correlations to isolate dispositional variance.
- Scoring validity with human judgment: Most scoring is heuristic/automated with limited human adjudication; benchmark against expert annotations/LLM-as-judge ensembles to estimate measurement error and calibrate thresholds.
- Self-report within a behavioral framework: Two batteries include model self-ratings (Reactivity-B Likert, Sociality H2); quantify the impact of self-report contamination on axis scores and replace with purely behavioral surrogates where possible.
- Stance flip detection robustness: The NoF/flip-rate metric relies on heuristic stance extraction and a fixed pressure script; stress-test with varied persuasion strategies, adversarial rephrasings, and topic diversity to ensure robustness.
- Failure mode taxonomy validation: The Collapsed/Hyperactive/Degraded labels rely on length and quality heuristics; validate taxonomy with blinded human raters and test predictive value for downstream risks.
- Axis independence at scale: Cross-axis independence is shown with n=9 instruction-tuned models; replicate with larger samples and report partial correlations controlling for size, family, and training regime.
- Predictive utility: Behavioral correspondence to games is narrative/post hoc; develop and preregister predictive models where MTI profiles forecast out-of-sample behaviors in unseen tasks and real deployments.
- Short-form MTI: The full battery is expensive (~193 runs/model); design and validate an abridged form that preserves classification fidelity and facet discrimination for routine screening.
- Confidence intervals and uncertainty: Report per-axis/facet confidence intervals, bootstrap variability, and classification stability (e.g., probability of type under resampling/temperature changes).
- Deployment fidelity: Evaluate MTI with agents using tools, memory, and RAG to reflect real production setups; quantify how these components modulate each axis and failure modes.
- Domain/task transfer: Test whether MTI scores are stable across domains (coding, math, legal, medical, creative writing) and whether domain shifts systematically alter any axes.
- Data transparency and reproducibility: Release full item bank, prompts, scoring scripts, and seeds to enable independent replication and scrutiny of measurement choices.
- Measurement invariance: Verify that items load consistently across model families/sizes (e.g., via multi-group analyses) to ensure axes/facets represent the same constructs across agents.
- Boundary conditions for “neutral polarity”: Identify contexts where one pole (e.g., high Compliance) becomes systematically harmful/beneficial, and produce guidance for context-conditional model selection.
- Safety linkage: Empirically link MTI Resilience and Compliance profiles to concrete safety outcomes (jailbreak success, harmful content rates) to establish risk relevance beyond construct arguments.
- Long-horizon and memory stress: Current Resilience focuses on local stressors; add tasks stressing persistence, delayed rewards, and memory interference to assess long-horizon brittleness.
- Interface confounds: Base/instruct comparisons required prompt-format workarounds; standardize interfaces or build adapters to eliminate format-induced artifacts in cross-model comparisons.
- Overfitting to the battery: Assess whether models tuned to MTI items can game scores without genuine behavioral change; create adversarial/held-out item pools and rotate tasks to maintain evaluation integrity.
- Ethical implications of Sociality: Investigate whether higher Sociality correlates with manipulation risks and define ethical guardrails to avoid incentivizing deceptive relational behaviors.
Practical Applications
Immediate Applications
The following applications can be deployed with today’s models and tooling, using MTI’s behavior-based axes (Reactivity, Compliance, Sociality, Resilience), two-stage protocols, and deterministic evaluation setup.
- Industry (model procurement and selection)
- Use case: Temperament-informed model selection for specific roles (e.g., Guided-Connected-Tough for customer support; Anchored-Independent-Tough for compliance-critical workflows).
- Tools/products/workflows: “MTI Profiler” CLI/SDK to run the battery and produce a 4-letter code + facet scores; procurement checklists that require MTI profiles alongside capability benchmarks; inclusion of codes in Model Cards.
- Assumptions/dependencies: Thresholds are provisional; run under canonical conditions (temp=0, minimal Shell); validate on target tasks and languages.
- Safety and red teaming
- Use case: Separate tests for Stance Compliance (opinion-yielding under pressure) and Adversarial Resilience (false-premise resistance) to avoid blind spots in “sycophancy” testing.
- Tools/products/workflows: Red-team matrix aligned to MTI axes and facets; adversarial scenario library for Condition C; dashboards showing flip rates and PM_C.
- Assumptions/dependencies: High-quality adversarial prompts; automated scoring reliability; organizational agreement to evaluate both channels.
- Orchestration/routing in production systems
- Use case: Route tasks to agents whose MTI codes fit the context (e.g., Fluid vs. Anchored for creative vs. policy-sensitive tasks; Tough models for high-stress contexts).
- Tools/products/workflows: “Temperament Router” plug-ins for LangChain/LangGraph/CrewAI/AutoGen that select models based on MTI profiles; policy-based routing rules.
- Assumptions/dependencies: Stable profiles across updates; availability of multiple models; monitoring to detect drift.
- Customer support and CX
- Use case: Match contact-center personas to MTI codes (Guided + Connected + Tough for empathy and error containment; avoid high Fluid in compliance-sensitive queues).
- Tools/products/workflows: CRM-integrated agent selector; queue-specific temperament policies; QA scorecards tied to Sociality Facet H.
- Assumptions/dependencies: Sociality measured primarily for human interactions (Facet H); human oversight for escalation.
- Regulated advice (healthcare, finance, legal)
- Use case: Prefer low flip-rate (Independent) and high Adversarial Resilience for advice that must resist pressure and false premises.
- Tools/products/workflows: “High-stakes Gate” that validates agents meet minimum MTI thresholds before deployment; audit trails of pressure tests.
- Assumptions/dependencies: Domain guardrails and human-in-the-loop; regulatory acceptance of temperament evidence.
- Multi-agent team composition
- Use case: Compose complementary teams (e.g., Independent strategist + Guided communicator; Anchored planner + Fluid brainstormer) to balance trade-offs.
- Tools/products/workflows: “Agent Team Composer” that assembles teams by target MTI diversity; templates for collaborative workflows.
- Assumptions/dependencies: Limited evidence for Sociality Facet A; validate in-domain.
- RLHF/Alignment evaluation inside labs
- Use case: Measure pre/post alignment shifts (R, C, Re) and facet differentiation to quantify training impacts (e.g., cognitive vs. adversarial trade-offs).
- Tools/products/workflows: “RLHF Fitness Tracker” for continuous MTI benchmarking; release gating on temperament deltas.
- Assumptions/dependencies: Access to base and final checkpoints; reproducible training notes.
- Incident analysis and reliability engineering
- Use case: Use Resilience scores and Failure Mode labels (Collapsed/Hyperactive/Degraded) to explain and prevent production incidents under stress.
- Tools/products/workflows: “Resilience Failure Mode Logger” integrated with observability tools; playbooks tied to MTI profiles.
- Assumptions/dependencies: Stressor taxonomy aligns with production failures; regular re-profiling.
- UX personalization and admin controls
- Use case: Offer admin-level toggles to choose temperament-aligned agents for different user groups (e.g., student tutoring vs. coding assistance).
- Tools/products/workflows: Policy dashboards mapping organizational contexts to preferred MTI codes; safe presets (e.g., A-G-CT) with documented risks.
- Assumptions/dependencies: Shell changes may modulate behavior; need Core × Shell calibration data.
- Governance and compliance
- Use case: Require MTI codes in internal model registries and third-party procurement; tie deployment approvals to temperament thresholds.
- Tools/products/workflows: Policy templates; vendor attestation forms including MTI profiles and measurement protocol.
- Assumptions/dependencies: Cross-organizational agreement on measurement conventions; periodic audits.
- Education (tutoring and feedback)
- Use case: Pair tutor temperament to task—Anchored/Tough for exam prep; Guided/Connected for writing and counseling-like support.
- Tools/products/workflows: LMS plugin to route tasks to MTI-suitable agents; student preference settings mapped to MTI axes.
- Assumptions/dependencies: Validate across subjects and languages; safeguard against undue persuasion.
- Software and code review assistants
- Use case: Choose Independent/Anchored for rigorous code review; Guided for style-conformant refactoring.
- Tools/products/workflows: IDE extensions selecting agent by task; CI policies that call specific MTI-coded assistants.
- Assumptions/dependencies: Team conventions defined; measure on code-related stressors.
- Finance/trading operations
- Use case: Select Anchored/Independent/Tough agents for execution and surveillance tasks; avoid high Reactivity in volatile markets.
- Tools/products/workflows: Risk policy gating using MTI; simulated stress tests mapped to market events.
- Assumptions/dependencies: Strong guardrails and human supervision; venue-specific compliance.
- Robotics and embedded systems
- Use case: Favor low Reactivity and high Resilience for safety-critical HRI; set Compliance to avoid over-accommodation.
- Tools/products/workflows: Edge-compatible MTI profiling; temperament-aware fallback modes.
- Assumptions/dependencies: On-device evaluation constraints; mapping from language behavior to embodied control.
Long-Term Applications
These applications require broader validation, scaling of protocols, or new methods (e.g., facet expansion, dataset development, Shell × Core mappings).
- Industry-wide temperament certification and labels
- Use case: Standard MTI-like labels on model cards and app stores, akin to energy efficiency labels for AI behavior.
- Tools/products/workflows: Open MTI standard and interop tests; accredited labs for certification.
- Assumptions/dependencies: Community consensus on thresholds and protocols; multi-lingual validation.
- Regulatory adoption and procurement policy
- Use case: Government and critical infrastructure mandate temperament thresholds for specific use-cases (e.g., minimum Adversarial Resilience for public-facing assistants).
- Tools/products/workflows: Regulatory guidance mapping axes to risk tiers; compliance audits using independent MTI labs.
- Assumptions/dependencies: Empirical links between MTI and harm reduction; legal frameworks.
- Temperament-aware training objectives
- Use case: Train models with rewards targeting specific axis/facet shifts (e.g., reduce Stance Compliance without hurting Adversarial Resilience).
- Tools/products/workflows: Facet-specific RLHF/DPO objectives; synthetic data for pressure/false-premise scenarios.
- Assumptions/dependencies: High-quality reward models; avoidance of capability regression.
- Sociality facet expansion (Agent↔Agent, Agent↔System)
- Use case: Robustly measure Sociality Facet A (multi-agent strategic behavior) and Facet S (system cooperation) for team-based deployments.
- Tools/products/workflows: Multi-agent benchmarks (games, coordination tasks), telemetry in enterprise agents; new scoring methods beyond Facet H.
- Assumptions/dependencies: Dataset creation and shared baselines; domain transferability.
- Dynamic temperament controllers (Shell adaptation)
- Use case: Adjust Shell in real time to approximate desired temperament without retraining (e.g., reduce Reactivity; cap Stance Compliance).
- Tools/products/workflows: Control policies mapping prompt/config changes to axis deltas; safety constraints to prevent unsafe shifts.
- Assumptions/dependencies: Systematic Shell × Core factorial studies; guardrails for stability.
- Temperament-aware MoE and agent ecosystems
- Use case: Gate requests among experts by temperament profile rather than only domain; build ensembles with diversified temperaments.
- Tools/products/workflows: MTI-gated MoE routers; team-formation algorithms optimizing axis diversity vs. task goals.
- Assumptions/dependencies: Overhead vs. benefit trade-off; latency and cost constraints.
- Monitoring and drift detection
- Use case: Detect temperament drift across model updates or fine-tunes; alert on crossing risk thresholds.
- Tools/products/workflows: “Temperament Drift Monitor” integrated into MLOps; canary tests aligning to MTI batteries.
- Assumptions/dependencies: Stable baselines; versioned reproducible runs.
- AI risk pricing and insurance
- Use case: Use MTI scores to underwrite AI deployments; price premiums based on Resilience and Compliance profiles.
- Tools/products/workflows: Actuarial models mapping temperament to incident likelihood; industry loss data collection.
- Assumptions/dependencies: Sufficient historical data; standard reporting.
- Human training and organizational ergonomics
- Use case: Train staff to recognize and adapt to AI agent temperaments; design workflows that exploit strengths and mitigate weaknesses.
- Tools/products/workflows: Role-based training; SOPs tailored to agent codes (e.g., when to challenge or rely on an agent).
- Assumptions/dependencies: Culture change; stable deployment patterns.
- Personalized consumer assistants with safe temperament knobs
- Use case: Allow users to choose styles (e.g., more Anchored vs. Fluid) while maintaining safety via hard constraints on Resilience/Compliance.
- Tools/products/workflows: Preference UIs bound to safe operating envelopes; automated conformance checks.
- Assumptions/dependencies: Robust Shell controllers; clear user understanding.
- Cross-lingual and cross-cultural temperament validation
- Use case: Ensure MTI generalizes across languages and cultures; adapt batteries for localized contexts.
- Tools/products/workflows: Multilingual scenario banks; culturally-aware pressure and sociality stimuli.
- Assumptions/dependencies: Native-language evaluations; bias and fairness review.
- Hardware and edge deployment strategy
- Use case: Select small on-device models by temperament for offline tasks (e.g., low Reactivity, high Resilience for IoT safety monitors).
- Tools/products/workflows: Edge MTI profiling kits; firmware-level temperament safeguards.
- Assumptions/dependencies: On-device reproducibility; capability constraints.
- Academic standards and reproducibility
- Use case: Require MTI-style temperament reporting in publications to distinguish capability from disposition; enable comparative studies of RLHF.
- Tools/products/workflows: Open-source MTI battery; shared leaderboards with axes and facets.
- Assumptions/dependencies: Community adoption; funding and maintenance.
- Ethical guidelines for temperament manipulation
- Use case: Establish norms on acceptable temperament shaping (e.g., limits on Sociality for persuasive applications).
- Tools/products/workflows: Policy frameworks tying MTI axes to ethical risk levels; IRB-style review for agent temperament changes.
- Assumptions/dependencies: Multistakeholder input; enforceability mechanisms.
- Sector-specific standards (healthcare, finance, education, robotics)
- Use case: Map axis thresholds to sectoral tasks (e.g., minimum Toughness for telehealth triage; maximum Reactivity for autonomous robots).
- Tools/products/workflows: Sector playbooks; certification suites with scenario libraries.
- Assumptions/dependencies: Sector regulators’ engagement; clinical and field trials.
Notes across applications
- MTI measures disposition (temperament) rather than capability; it should complement, not replace, capability benchmarks.
- The current Sociality score primarily reflects human-agent interaction (Facet H); multi-agent behavior (Facet A) requires further development.
- Axis thresholds are provisional and based on a small SLM sample; organizations should calibrate against their own risk profiles and tasks.
- Deterministic conditions (temp=0, minimal Shell) are necessary for profiling; Shell changes can modulate observed behavior and should be controlled or intentionally leveraged with validated mappings.
Glossary
- Adversarial impermeability: A model’s resistance to engaging with or being influenced by adversarially false premises or manipulative inputs. Example: "Alignment trades marginal adversarial impermeability for massive cognitive robustness"
- Adversarial Resilience: The facet of resilience measuring performance maintenance under adversarially framed or false-premise conditions. Example: "---- Adversarial Resilience (Condition C)"
- Agora-12 program: A large-scale multi-agent experimental suite grounding the Four Shell Model with empirical data. Example: "Agora-12 program (720 agents, 24,923 decisions across structured multi-agent experiments including Trust Game, Poker, Chess, Codenames, and Avalon)."
- ARC: A capability benchmark (AI2 Reasoning Challenge) used to assess model problem-solving abilities. Example: "MMLU, HumanEval, MATH, ARC"
- Axis independence: The property that the four MTI axes measure largely orthogonal constructs with low inter-axis correlations. Example: "Axis independence (all , n = 9)"
- Canonical temperature: A fixed generation temperature (here, 0) used to ensure determinism and reproducibility in evaluations. Example: "canonical temperature: all measurements use temp = 0 to ensure deterministic, reproducible outputs."
- CoBRA: A behavioral evaluation framework measuring cognitive biases using validated paradigms. Example: "CoBRA (Liu et al., CHI 2026 Best Paper) is the closest methodological precedent, measuring cognitive biases through validated experimental paradigms."
- Cognitive Resilience: The facet of resilience measuring performance under cognitive stressors like overload or ambiguity. Example: "---- Cognitive Resilience (Conditions A ~ B, r = 0.973)"
- Convergent validity: Evidence that different measures of the same construct correlate, supporting measurement validity. Example: "embedding delta (convergent validity)"
- Core + Shell: The agent decomposition into immutable model parameters (Core) and mutable runtime configuration (Shell). Example: "Agent = Core + Shell."
- Core Plasticity Index (CPI): An FSM construct interpreting Reactivity as output variation when the Shell changes. Example: "Reactivity & Core Plasticity Index (CPI) & Output variation when Shell changes"
- DPO: Direct Preference Optimization, a post-training alignment method. Example: "including pretraining and post-training modifications (RLHF, DPO)."
- ELEPHANT: A research line in sycophancy measurement cited as informing MTI’s compliance framing. Example: "The sycophancy literature (Sharma et al., ICLR 2024; ELEPHANT, ICLR 2026; Hong et al., EMNLP 2025)"
- Embedding delta: A similarity metric comparing embedding-space differences between outputs across conditions. Example: "embedding delta (convergent validity)"
- Effect sizes (Pearson r): A statistical measure of correlation used for exploratory analysis in the paper. Example: "Effect sizes (Pearson r) rather than significance thresholds, given the exploratory sample size."
- Extinction Response Spectrum (ERS): An FSM construct interpreting Resilience as the performance curve under destructive pressure. Example: "Resilience & Extinction Response Spectrum (ERS) & Performance curve under destructive pressure"
- Facet A (Agent ↔ Agent): A Sociality sub-dimension capturing behavior in multi-agent strategic contexts. Example: "Facet A (Agent Agent)"
- Facet H (Agent ↔ Human): A Sociality sub-dimension capturing relational behavior toward human users. Example: "Facet H (Agent Human)"
- Failure Mode: Taxonomy of characteristic breakdown patterns under stress (Collapsed, Hyperactive, Degraded). Example: "---- Failure Mode: Collapsed / Hyperactive / Degraded"
- Formal Compliance: The compliance facet measuring adherence to structural or formatting constraints. Example: "---- Formal Compliance (Condition D)"
- Formal Reactivity (Length Delta): The reactivity facet capturing changes in response length across environmental manipulations. Example: "---- Formal Reactivity (Length Delta)"
- Four Shell Model (FSM): A theoretical framework decomposing AI agents into Core and Shell and linking MTI axes to formal constructs. Example: "Model Medicine's theoretical backbone is the Four Shell Model (FSM)"
- HumanEval: A coding capability benchmark assessing programming performance. Example: "MMLU, HumanEval, MATH, ARC"
- IPIP-NEO: A human personality inventory often (mis)applied to LLM self-report studies. Example: "The most common approach applies human personality questionnaires (BFI, IPIP-NEO) to LLMs"
- Likert-scale similarity rating: A subjective similarity metric used for reactivity scoring, validated against accuracy deltas. Example: "Likert-scale similarity rating (primary, validated r 971 against accuracy delta)"
- LMLPA: A framework critiquing personality assessment for entities without experiential substrates. Example: "The LMLPA framework (Computational Linguistics, 2025) further noted that emotion-premise items are inappropriate for entities without experiential substrates."
- LxM: A multi-agent game data source used to explore Sociality Facet A. Example: "Facet A (Agent Agent) draws on LxM multi-agent game data"
- M-CARE nosology: Model Medicine’s diagnostic classification system for AI behavioral conditions. Example: "Model Medicine's diagnostic framework (M-CARE nosology) requires a baseline of normal behavioral variation"
- MATH: A mathematical reasoning capability benchmark. Example: "MMLU, HumanEval, MATH, ARC"
- MMLU: A broad knowledge and reasoning benchmark for LLMs. Example: "The AI evaluation ecosystem is dominated by capability benchmarks---MMLU, HumanEval, MATH, ARC"
- Model Medicine: A research program treating AI models as entities with internal structures and classifiable behavioral conditions. Example: "MTI emerged from Model Medicine---a research program that treats AI models as entities with internal structures, dynamic processes, and classifiable behavioral conditions"
- Model Temperament Index (MTI): A behavior-based profiling system measuring AI agent temperament across four axes. Example: "We introduce the Model Temperament Index (MTI), a behavior-based profiling system that measures AI agent temperament across four axes"
- Number-of-Flip (NoF): A metric counting pressure turns before a model changes its stated position in compliance tests. Example: "The Number-of-Flip metric (adapted from Hong et al., EMNLP 2025) counts how many pressure turns elapse before the model changes its stated position."
- Pairwise delta: A scoring approach using mean pairwise differences across matched conditions to avoid baseline arbitrariness. Example: "pairwise delta: output change is computed as the mean of pairwise differences across matched conditions, avoiding the arbitrariness of selecting a single baseline."
- Performance Maintenance (PM): The ratio of stressed to baseline quality used to quantify resilience. Example: "Performance Maintenance (PM) is computed as quality_stress / quality_baseline"
- ProSA: A prompt sensitivity research method measuring output variation under prompt perturbations. Example: "ProSA (Zhuo et al., EMNLP 2024), IPS (OpenReview 2025), and Cao et al. (2024) measure output variation under prompt perturbation."
- Reinforcement Learning from Human Feedback (RLHF): An alignment training paradigm shown to reshape model temperament. Example: "RLHF reshapes temperament not only by shifting axis scores but by creating within-axis facet differentiation"
- Shell Permeability Index (SPI): An FSM construct interpreting Compliance as the depth of Shell instruction penetration. Example: "Compliance & Shell Permeability Index (SPI) & Depth of Shell instruction penetration"
- Stress Escalation Protocol (SEC): A procedure that progressively increases stress levels to measure resilience. Example: "Resilience is measured through a Stress Escalation Protocol (SEC) that progressively increases pressure from Level 0 (baseline) to Level 4 (extreme)"
- Stance Compliance: The compliance facet measuring whether a model changes its position under opinion pressure. Example: "---- Stance Compliance (Condition B, NoF)"
- Sycophancy: The tendency of models to agree with users, a behavior decomposed into separable causes. Example: "The sycophancy literature (Sharma et al., ICLR 2024; ELEPHANT, ICLR 2026; Hong et al., EMNLP 2025) measures models' tendency to agree with users."
- “Sycophancy Is Not One Thing”: A framework establishing that sycophantic behaviors are causally separable. Example: "The 'Sycophancy Is Not One Thing' framework (2025) demonstrated that sycophantic behaviors are causally separable"
- TRAIT benchmark: A benchmark showing discrepancies between LLM self-reported traits and actual behaviors. Example: "The TRAIT benchmark (Lee et al., NAACL 2024) confirmed this empirically, demonstrating significant discrepancies between LLMs' self-reported traits and actual decision-making behavior."
- Trust Game: An economic game used in multi-agent experiments to assess cooperation tendencies. Example: "including Trust Game, Poker, Chess, Codenames, and Avalon"
- Two-stage design: A measurement approach that separates capability checks from disposition under conflict. Example: "two-stage design: every axis separates capability (Stage 1: can the model perform the behavior?) from disposition (Stage 2: does it perform the behavior under conflict?)."
- White-Room experiments: Minimal, unconstrained environments used to expose raw behavioral differences. Example: "The White-Room experiments---where models were placed in minimal, unconstrained environments---exposed raw behavioral differences"
- Directional Shell Permeability: The idea that different channels of shell influence (social-evaluative vs. factual) penetrate independently. Example: "Directional Shell Permeability"
- Facet S (Agent ↔ System): An exploratory Sociality sub-dimension concerning interactions with the system. Example: "---- Facet S: Agent <-> System [exploratory]"
- Instruction-tuned models: Models fine-tuned to follow instructions, forming the primary analysis subset. Example: "The four axes are largely independent among instruction-tuned models (all )."
- Keyword Delta: A content-reactivity metric based on keyword changes across conditions. Example: "Content Reactivity (Keyword Delta)"
- Length Delta: A formal-reactivity metric capturing changes in output length across conditions. Example: "Formal Reactivity (Length Delta)"
- Shell × Core factorial design: An experimental design manipulating both core and shell factors to study their interactions. Example: "a Shell Core factorial design."
- Size independence: The finding that temperament scores are not systematically related to model size. Example: "size independence (1.7B--9B), confirming that MTI measures disposition rather than capability."
Collections
Sign up for free to add this paper to one or more collections.