- The paper shows that sparse routing in MoE models leads to highly monosemantic experts, improving interpretability compared to dense FFNs.
- It employs k-sparse probing across 12 models and 58 concepts to quantify expert specialization and functional routing effects.
- The study introduces an automatic LLM-based labeling pipeline, demonstrating scalable mechanistic analysis of modular subroutines.
Interpreting Mixture-of-Experts LLMs at the Expert Level
Background and Motivation
Mixture-of-Experts (MoE) architectures are now the predominant method for scaling LLMs efficiently. These models employ sparse routing, wherein only a subset of parameters (“experts”) are activated per token, reducing computational cost without sacrificing model capacity. However, whether this inherent sparsity yields increased interpretability compared to dense feed-forward networks (FFNs) has remained unresolved. A principal barrier to interpreting dense models is polysemanticity—individual neurons fire for multiple, unrelated concepts due to representational superposition. Recent works argue that increased architectural sparsity should reduce superposition and enable more transparent, monosemantic components. This work provides a systematic, empirical investigation of this hypothesis at both neuron and expert levels in production-scale models, ultimately proposing the expert as the preferred unit of mechanistic analysis.
Monosemanticity and Polysemantic Suppression in MoE
The study applies k-sparse probing to 12 models across 58 concepts and multiple domains, measuring each component’s ability to linearly decode supervised concepts with varying numbers of active neurons. In dense FFNs, probe performance is poor at low k—even the best neuron is often weakly diagnostic—indicating distributed, highly polysemantic representations. In contrast, MoE experts consistently achieve near-optimal performance with k=1, implying most neurons are monosemantic for specific concepts. This gap persists and even widens as routing sparsity (NA/N) increases; sparser routing yields experts with cleaner, less entangled representations, and reduced variance across probed concepts.
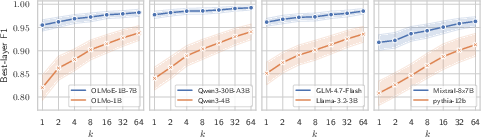
Figure 1: Best-layer F1 score for probes trained on MoE and dense models, highlighting increased monosemanticity in MoEs, especially at k=1.
Additionally, direct per-concept comparison shows virtually all points above the equality line: for matched parameter budgets, MoE experts are more monosemantic than dense alternatives regardless of conceptual category.
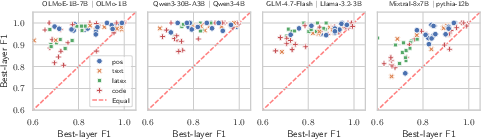
Figure 2: For every concept tested, MoE experts achieve higher probe F1 scores than dense models, establishing the interpretability advantage concretely.
Further analysis within the OLMo family, which includes dense and MoE variants at equal active parameter counts, rules out the total parameter count as the source of this effect. Instead, routing sparsity is the crucial factor—models with more experts and fewer active experts per token are more interpretable.
Scaling Behavior and the Role of Routing
The empirical investigation links the reduction in superposition directly to architectural and operational routing sparsity. Models with extremely sparse activation, such as Qwen3-30B-A3B (NA/N≈0.06), display the sharpest monosemantic signals. By contrast, “denser” MoEs (e.g., Mixtral-8x7B with NA/N=0.25) show diminished, but still superior, interpretability compared to dense FFNs. This trend persists across all tested models, supporting the theoretical prediction that large-scale MoEs, as deployed in industry, are structurally more amenable to mechanistic interpretation as the field pursues greater routing sparsity.
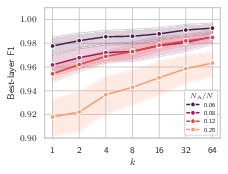
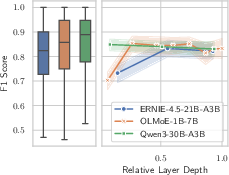
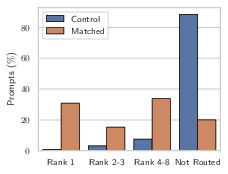
Figure 3: Left: Best-layer F1 as a function of routing sparsity; Center: Distribution and per-layer average of automatic interpretability scores; Right: Causal attribution experiment results with expert routing/importance.
Automatic Expert-Level Interpretation
The finding that neurons align monosemantically motivates a paradigm shift: analyzing MoEs at the expert level rather than at the neuron or post-hoc concept level. The authors introduce an LLM-based automatic labeling pipeline, which combines high-activation context selection (via router and vector output magnitude) with natural language hypothesis generation and scoring. This labeled taxonomy is then causally validated: synthetic trigger-target experiments show that labeled experts, when routed and highly activated, are causally responsible for their hypothesized operational effect; in context-matched prompts, the relevant expert is frequently the top contributor by DLA to the target word, but is silent or uninvolved in control prompts.
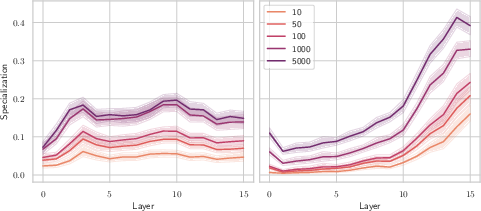
Figure 4: Expert specialization scores reveal the depth-resolved functional partitioning of MoE layers.
Scores remain high across all layers in highly sparse models, and the vast majority of experts are automatable described in precise, functional language as fine-grained task experts. Moreover, this interpretability is directly correlated with routing sparsity: sparser models yield more reliable, contractive expert roles.
Functional and Routing Specialization
To assess the degree and nature of expert specialization, the authors introduce a quantification based on the Jensen-Shannon divergence between the empirical token distributions for each expert (both pre- and post-FFN) and the layer-wise token distribution. They define two axes: Routing Specialization (input tokens routed to the expert) and Functional Specialization (output token distributions promoted via Logit Lens projections). Broad “domain specialists” are expected to both receive and promote tokens deviant from the average at coarse granularity (low k); “task experts,” by contrast, may process a broad input but make extremely sharp predictions at high k.
The analysis of OLMoE-1B-7B shows that early and mid-layer routing exhibits bimodal partitioning, and that deep layers see dramatic spikes in functional specialization—at high k, some experts exclusively promote highly specific outputs even when fed diverse input. This supports the conclusion that expert-level functionality is largely that of specialized, modular subroutines: closing LaTeX brackets, filling legal citations, or domain-specific completions. MoEs achieve this modularity inherently, by virtue of their architectural and operational design.
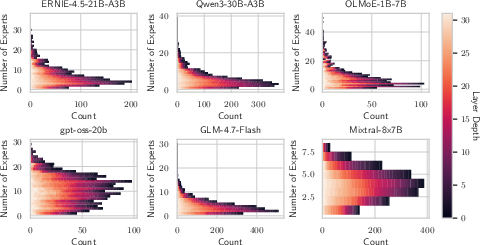
Figure 5: Per-concept, per-layer estimation of the number of experts delivering high prediction quality—most concepts are isolated to a handful of experts, supporting the claim of strong specialization.
Implications and Limitations
These results have substantial implications for both mechanistic interpretability and the practical auditability of high-capacity LLMs. First, the discovery that MoE architectures—particularly with extreme routing sparsity—produce experts that are reliably describable and causally responsible for targeted, task-level computations provides a direct path to scalable interpretability. Instead of training layerwise autoencoders or conducting expensive per-unit analysis, one can focus on hundreds of task-specialized experts with direct, testable roles. This not only accelerates interpretability research but can facilitate targeted interventions, debugging, and safety monitoring; interventions can be localized to a small set of modules rather than diffuse neuron sets.
Furthermore, the MoE “circuits” revealed here bear a strong conceptual resemblance to functional subroutines or modules; this aligns with literature on the circuits view of LLM computation and opens up future work on mapping out such computational graphs, understanding cross-expert interactions, and exploring modularity at larger system scales.
A remaining limitation is that some superposition and overlap likely persists, and the line between domain and task specialization is gradient, not absolute. The authors also acknowledge that their hardware scale precludes testing trillion-parameter MoEs (e.g., DeepSeek-V3), though they hypothesize the same trends will apply. Finally, interpretability labeling is subject to data- and prompt-dependence, and expert functions could shift with prompt or context.
Conclusion
This study demonstrates that MoE architectures substantially reduce polysemanticity at both neuron and expert levels and, through architectural sparsity, enable robust, automatic, and scalable interpretation at the expert level. This provides compelling evidence that sparse MoEs represent not only a breakthrough in scaling efficiency, but also realize interpretable, modular computation by construction—a critical advance for mechanistic understanding and responsible deployment of LLMs.

