- The paper shows that increasing depth in linear and second-order RNNs enhances memory capacity and enables efficient higher-order polynomial mappings.
- It demonstrates that for fixed parameter budgets, deeper networks achieve tasks like delayed copying more efficiently than wider, shallow architectures.
- The work clarifies the tradeoff between multiplicative interactions and depth-wise nonlinear activations for effective state-tracking in RNNs.
The Expressivity of Recurrent Neural Networks: Depth as a Key Factor
Introduction and Motivation
The paper "On the Role of Depth in the Expressivity of RNNs" (2604.02201) systematically analyzes the interplay of depth and recurrence in RNN architecture, isolating their impact on expressivity and memory capacity. While depth in feedforward architectures is well-established as a driver of compositional expressive power, its precise contribution within recurrent networks—accounting for their temporal dynamics—has lacked rigorous formal characterization. The authors fill this gap by distinguishing expressivity contributions from depth, hidden size, and architectural enhancements such as second-order (multiplicative) interactions.
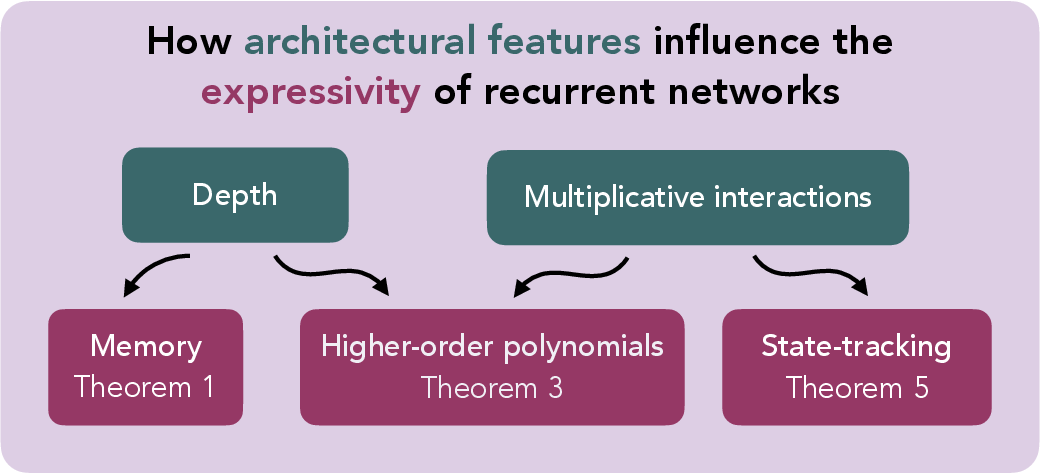
Figure 1: Theoretical insights overview of the effects of architectural choices on the expressivity of RNNs.
Theoretical Foundations: Depth, Memory, and Polynomial Expressivity
Linear RNNs: Depth Enhances Memory and Parameter Efficiency
Linear RNNs (without nonlinear activations) compute linear transformations of their input sequences, yet the paper proves that adding layers strictly increases memory capacity—even in the absence of nonlinearities (Theorem 1). Depth provides a strictly larger set of representable functions, as it enables the network to stage and propagate information through multiple hidden vectors, ultimately extending temporal retention.
The authors demonstrate that for tasks requiring information to be copied over long temporal intervals, increasing depth is a more parameter-efficient strategy than simply enlarging hidden size. Formally, for fixed parameter budgets, deeper linear RNNs can implement functions such as delayed copies that shallower models cannot (Theorem 3). However, if representational capacity is measured by total hidden units, a shallow but wide RNN is strictly more expressive than a deep and narrow one (Proposition 1). This discrepancy is a product of the block structure imposed by depth, which constrains representational flexibility but dramatically reduces parameter count.
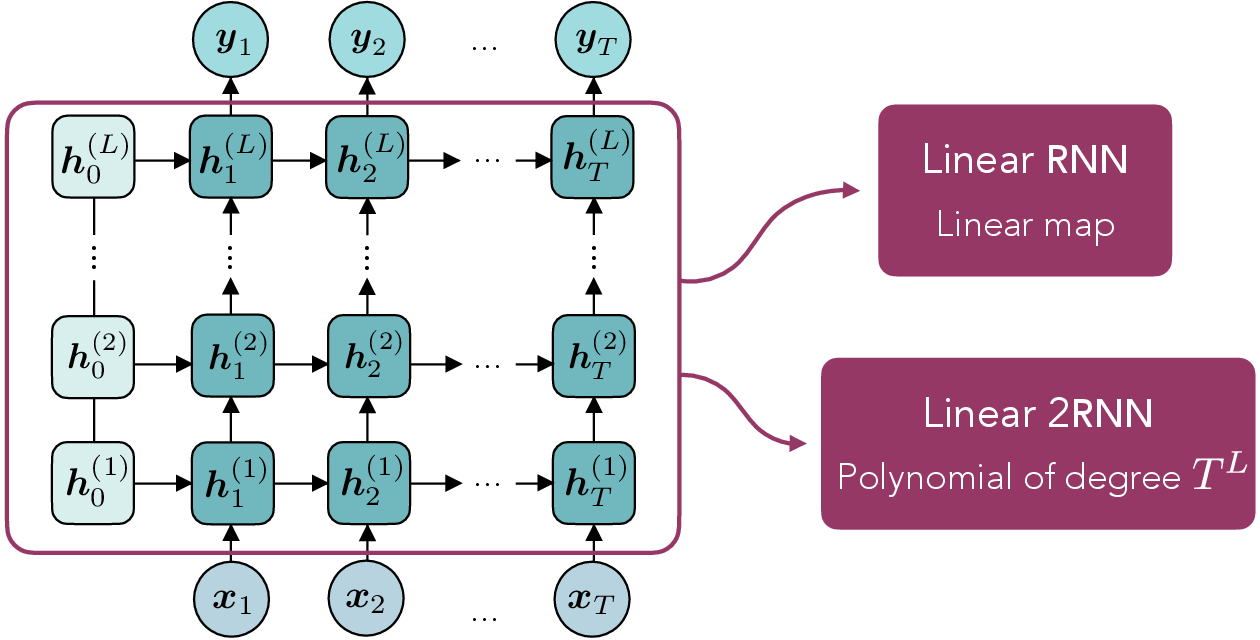
Figure 2: Unrolled deep recurrent architecture. Linear RNNs compute linear mappings; linear 2RNNs produce polynomial mappings.
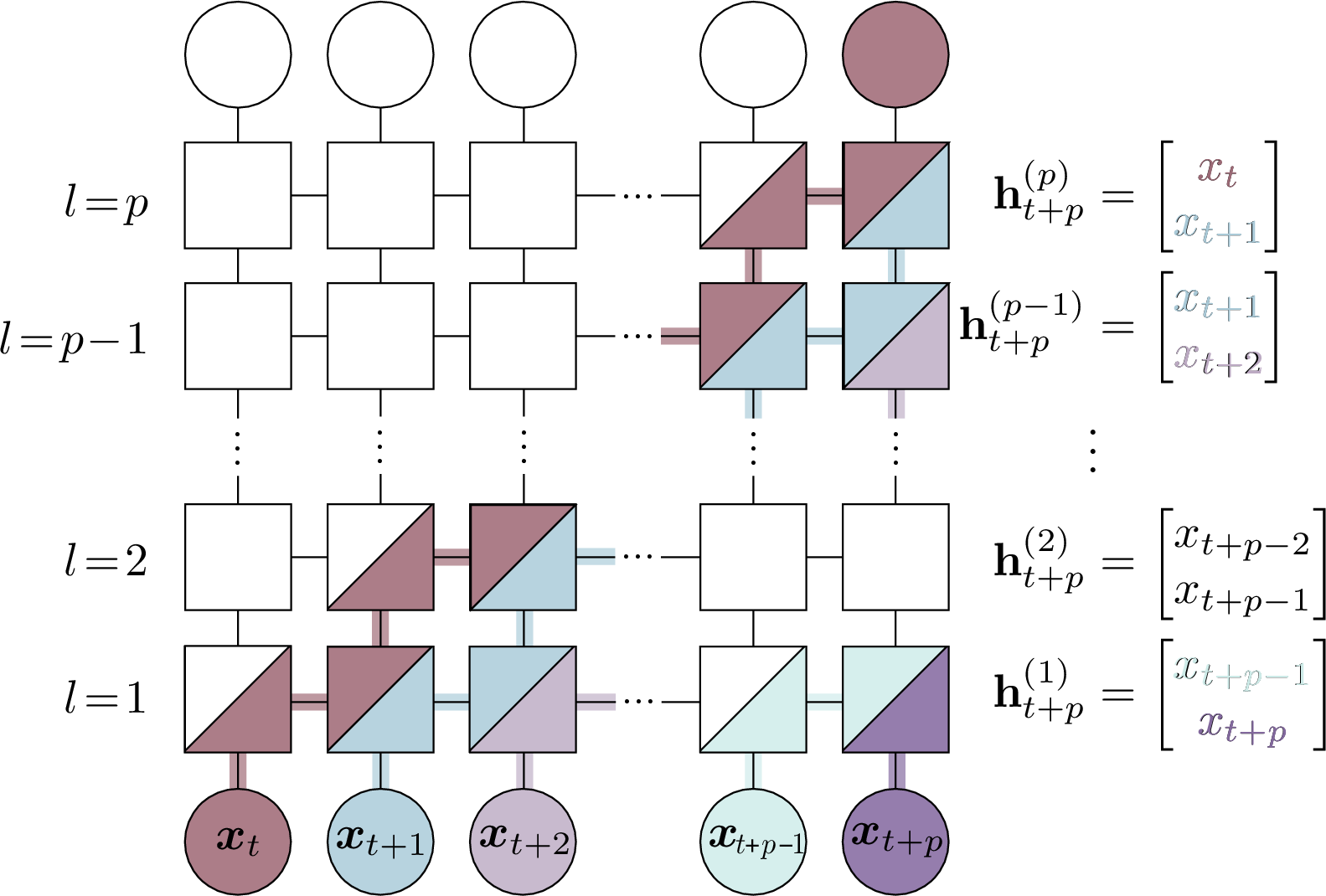
Figure 3: Information flow for the copy function in deep linear RNNs.
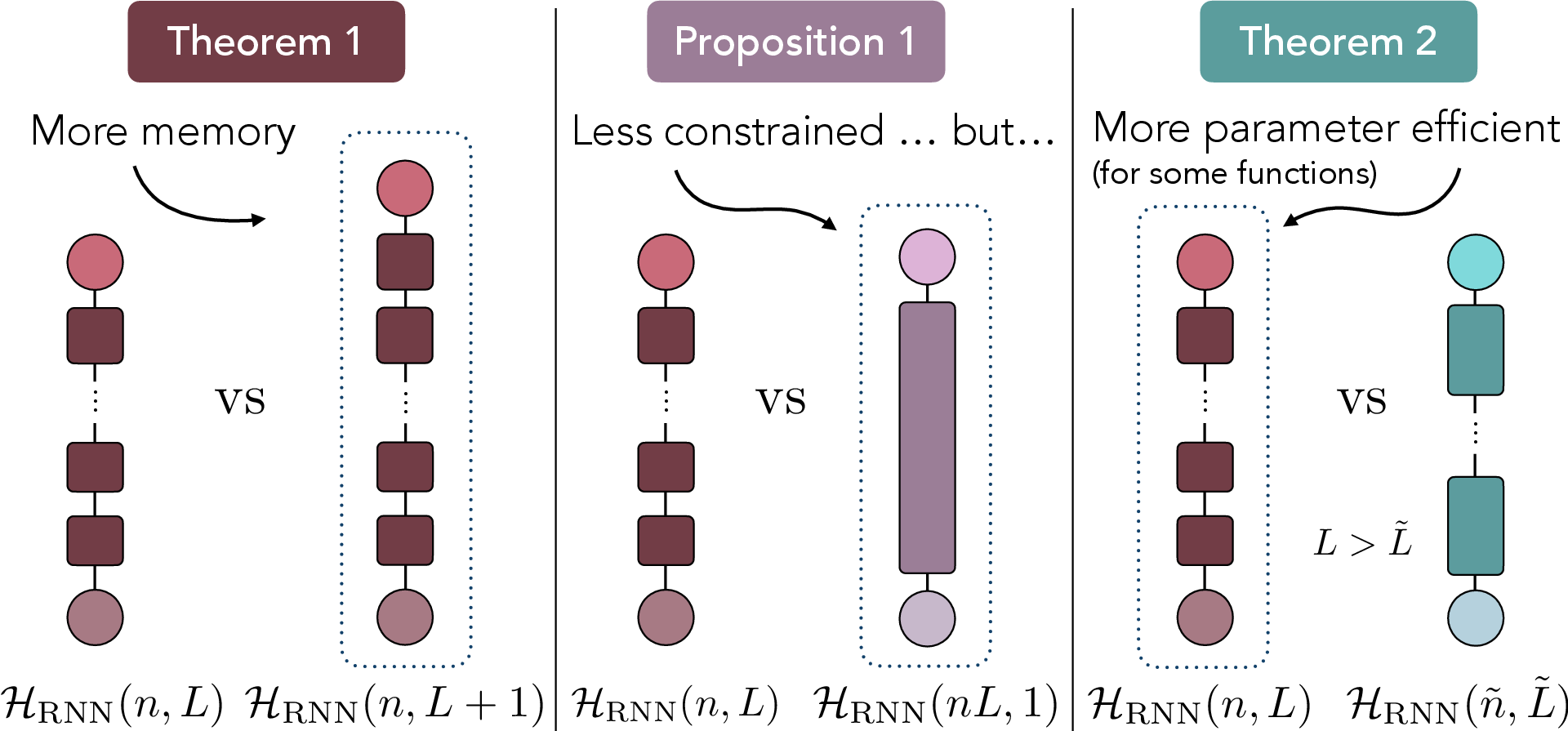
Figure 4: Adding layers increases memory capacity (Theorem 1); increasing width offers more flexibility but is less parameter-efficient.
The extension to second-order RNNs (2RNNs), which incorporate multiplicative (bilinear) interactions between hidden state and input, reveals that depth increases not only memory but also the degree of polynomial mappings: linear 2RNNs compute polynomials whose maximal degree grows with depth (Theorem 2). This is a qualitative departure from linear RNNs, as the expressive capacity for higher-order dependencies is expanded independent of hidden size.
In practical architectures, the authors analyze CPRNNs (CP-decomposed 2RNNs) to bound parameter count. The expressivity gain via depth in CPRNNs is orthogonal to the gain from CP rank, and both can be tuned independently for strictly increased capacity (Theorem 4)—a result generalizing prior findings about shallow CP(BI)RNNs.
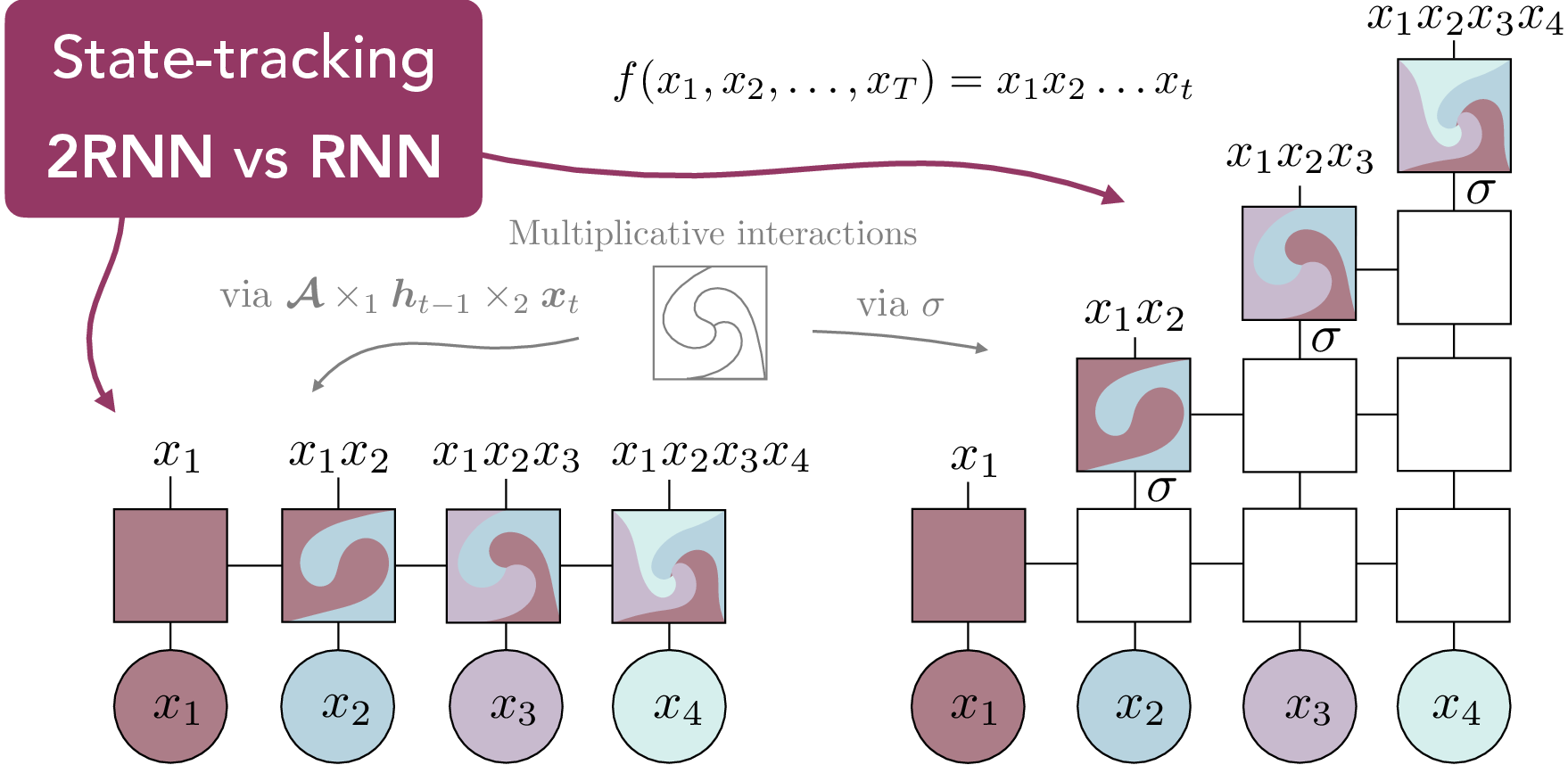
Figure 5: State-tracking information flow via multiplicative interactions in 2RNNs vs. nonlinear activations in RNNs.
Architectural Distinctions: Multiplicative vs Nonlinear Mechanisms
A crucial theoretical result is the separation between expressivity gained through multiplicative interactions versus depth-wise nonlinear activations. Certain functions—those involving explicit state-tracking, as in automata computations—can be realized by single-layer 2RNNs but not by arbitrarily deep RNNs with nonlinearities applied only in depth (Theorem 5). The need for temporal multiplicative interaction cannot be satisfied by compositions of nonlinearities restricted to layer-wise application.
This separation is significant in the context of state-space models (SSMs), where nonlinear activations are often applied only depth-wise. Empirically, such models cannot perform state-tracking on arbitrarily long sequences, confirming theoretical limitations shown in recent work [merrill2024illusion].
Empirical Validation: Synthetic and Real-world Tasks
Copy and Sinus Tasks
Experiments on synthetic tasks validate theoretical predictions. For the copy task, deeper linear RNNs required fewer hidden units to achieve zero loss; but for fixed total units, shallow models perform better. Depth provides parameter efficiency in memory-intensive tasks.
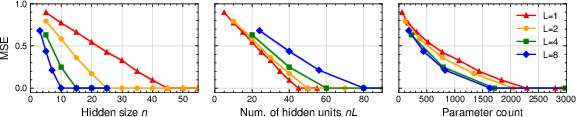
Figure 6: MSE on the copy task versus hidden size, units, and parameter count for varying depth.
In the sinus-copy task (combining memory and nonlinearity), deep RNNs outperform shallow ones for fixed parameter budgets, specifically when both memory and nonlinear transformation are required.
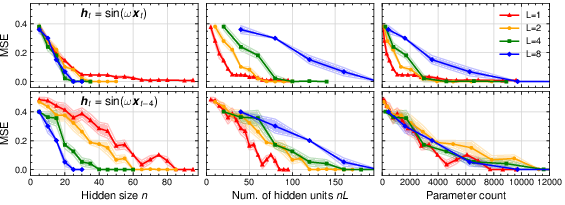
Figure 7: Test MSE for sinus and copy-sinus tasks of tanh-activated RNNs as a function of hidden size, units, and parameters for varying depth.
Parity: State-Tracking vs Memory
The parity task, requiring state-tracking rather than memory, demonstrates depth's limitation when nonlinearities are applied only in depth. RNNs with recurrent nonlinear activations solve parity efficiently, while depth-only nonlinear models require excessive hidden size and still fail as predicted.

Figure 8: Test MSE for parity task in RNNs by activation scheme and parameter count.
Language Modeling: Tiny Shakespeare Dataset
On real datasets, including character-level language modeling, depth consistently improves performance for RNNs, CPRNNs, and S4 models, but parameter efficiency varies by task. For CPRNNs, expressivity saturates after a certain depth (correlated with polynomial degree), suggesting that gains are task-dependent.

Figure 9: Test bits-per-character for RNNs, CPRNNs, and S4 models as a function of depth and parameter count.
Long Range Arena (LRA) Benchmarks
Across LRA tasks, depth benefits performance depending on the memory or state-tracking requirements, but saturates or becomes less significant for tasks where memory is less critical (e.g., Retrieval).
Practical and Theoretical Implications
The findings clarify architectural tradeoffs in recurrent sequence modeling:
- Depth increases memory retention and parameter efficiency, particularly for tasks requiring propagation of information across time.
- Multiplicative (bilinear) interactions provide a mechanistically distinct form of expressivity, enabling state-tracking and higher-order polynomial modeling—function classes unreachable by depth-wise nonlinear activation alone.
- Balancing depth, hidden size, and multiplicative mechanisms, as well as parameterization via tensor decompositions (e.g., CP), enables targeted capacity gains for specific task demands.
For practical model design, these results suggest that depth should be leveraged for memory-centric sequence tasks, while multiplicative interactions are indispensable for state-tracking or modeling higher-order input dependencies. The tuning of depth, width, and rank parameters should be informed by task structure and computational budget.
Future Directions
The paper motivates further investigation into how other architectural elements (e.g., gating, time variance, structured state-space kernels) interplay with optimization and expressivity. The challenge of aligning theoretical expressivity with practical optimization dynamics remains central, especially in the training of deep and/or multiplicative RNNs. Future work should also address modular architectures combining both mechanisms to achieve universal sequence modeling capacity.
Conclusion
Depth in recurrent architectures provides strictly increased expressive power and memory retention, with significant parameter efficiency compared to mere width expansion. The additive role of multiplicative interactions introduces higher-order polynomial expressivity and enables state-tracking functionalities. Empirical results on synthetic and real sequence modeling tasks corroborate theoretical insights, highlighting the nuanced and task-dependent effects of architectural choices. These findings provide principled guidance for the design of effective, efficient, and theoretically robust recurrent sequence models.